C#を用いたアプリケーション開発において、文字の「全角・半角」を判定しなければならない場面は多々あります。
特に、日本国内のビジネスシステムやレガシーなシステムとの連携、あるいは固定長ファイルの出力処理などでは、見た目上の幅やバイト数に基づいた厳密な区別が求められます。
しかし、現代の標準であるUnicode(UTF-16)を基盤とするC#において、文字はすべて1文字として扱われ、内部的には「全角」や「半角」という明確な属性を持っているわけではありません。
そのため、開発者は用途に応じて適切なロジックを選択し、実装する必要があります。
本記事では、バイト数による判定、正規表現による判定、そしてUnicodeの特性を利用した判定など、実務で役立つ具体的な手法を詳しく解説します。
C#における全角・半角判定の考え方
C#のstring型やchar型は、内部的にUTF-16エンコーディングを採用しています。
このエンコーディングでは、基本的にすべての文字が2バイト(サロゲートペアを除く)で表現されるため、メモリ上のサイズだけで全角と半角を区別することはできません。
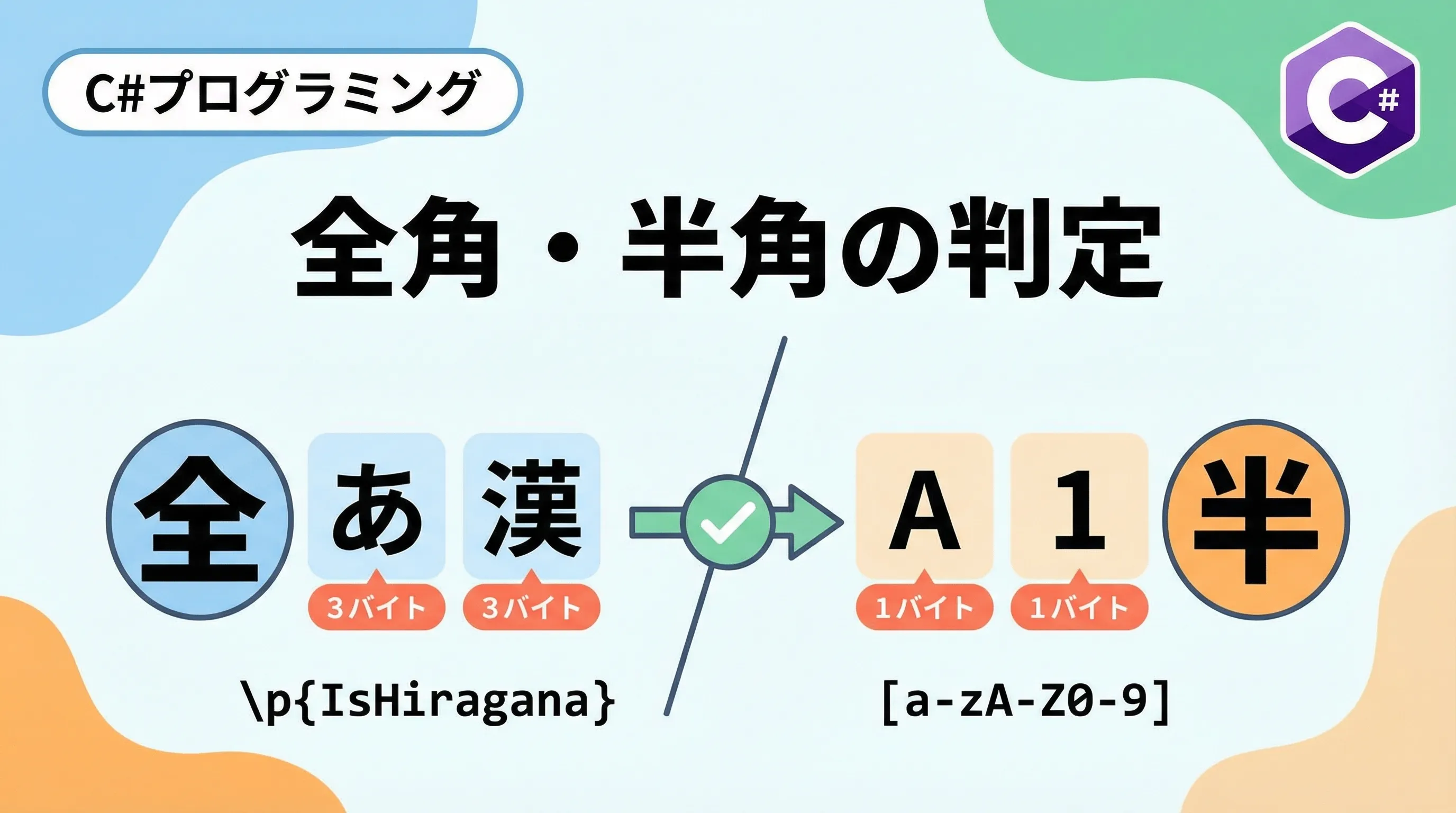
全角・半角という概念は、主に日本独自の「Shift-JIS」などの文字コードにおける「1バイト文字か2バイト文字か」という考え方に基づいています。
そのため、C#で判定を行う際には、「どの基準で全角・半角を定義するか」を明確にする必要があります。
一般的には、以下の3つのアプローチが取られます。
- バイト数による判定:特定のエンコーディング(主にShift-JIS)に変換した際のバイト数を確認する。
- 正規表現による判定:Unicodeの文字範囲を指定して、特定の文字種に含まれるかを確認する。
- Unicodeの文字特性による判定:EastAsianWidth(東アジアの文字幅)などの特性を利用する。
方法1:バイト数による判定(Shift-JISを利用)
最も古典的かつ確実な方法の一つが、「Shift-JISにエンコードした際のバイト数を確認する」手法です。
Shift-JISでは、半角英数字や半角カタカナは1バイト、それ以外の漢字や全角記号などは2バイトとして扱われます。
実装の注意点
.NET Coreや.NET 5以降のモダンな.NET環境では、既定でShift-JISなどのコードページがサポートされていません。
そのため、System.Text.CodePagesEncodingProviderを使用して、エンコーディングを有効化する必要があります。
using System;
using System.Text;
public class CharWidthChecker
{
public static void Main()
{
// .NET Core / .NET 5以降でShift-JISを扱うために必要
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
string testString = "Aあ1ア";
foreach (char c in testString)
{
if (IsFullWidth(c))
{
Console.WriteLine($"'{c}' は全角です。");
}
else
{
Console.WriteLine($"'{c}' は半角です。");
}
}
}
/// <summary>
/// 文字が全角かどうかを判定します。
/// </summary>
/// <param name="c">判定対象の文字</param>
/// <returns>全角の場合はtrue、それ以外はfalse</returns>
public static bool IsFullWidth(char c)
{
// Shift-JISエンコーディングを取得
Encoding sjis = Encoding.GetEncoding("Shift_JIS");
// バイト数を取得
int byteCount = sjis.GetByteCount(c.ToString());
// 2バイト以上であれば全角とみなす
return byteCount >= 2;
}
}'A' は半角です。
'あ' は全角です。
'1' は半角です。
'ア' は半角です。この方法のメリットは、「半角カタカナ」を正しく半角として判定できる点にあります。
Shift-JISの仕様に則っているため、古いシステムとの連携やCSV出力などで「バイト数制限」がある場合に非常に有効です。
方法2:正規表現による判定
特定の文字範囲を指定して判定を行う「正規表現」を用いた手法は、パフォーマンスや柔軟性の面で優れています。
例えば、「ASCII文字(半角英数字・記号)」と「それ以外」を分けたい場合に適しています。
Unicode範囲の指定
Unicodeにおいて、一般的な半角文字(ASCII)は \u0020 から \u007E までの範囲にあります。
また、半角カタカナは \uFF61 から \uFF9F までの範囲に定義されています。
using System;
using System.Text.RegularExpressions;
public class RegexWidthChecker
{
public static void Main()
{
string[] targets = { "a", "あ", "7", "サ", "!" };
foreach (var s in targets)
{
// 半角文字(ASCII + 半角カタカナ)にマッチするか判定
if (Regex.IsMatch(s, @"^[\u0020-\u007E\uFF61-\uFF9F]+$"))
{
Console.WriteLine($"'{s}' は半角範囲の文字です。");
}
else
{
Console.WriteLine($"'{s}' は全角範囲の文字です。");
}
}
}
}'a' は半角範囲の文字です。
'あ' は全角範囲の文字です。
'7' は半角範囲の文字です。
'サ' は半角範囲の文字です。
'!' は全角範囲の文字です。注意点として、正規表現による判定は「定義した範囲」に依存します。
特殊な記号や他言語の文字が含まれる場合、どの範囲までを「半角」とするかを厳密に定義しなければ、意図しない判定結果を招く恐れがあります。
方法3:Unicode特性(EastAsianWidth)の利用
Unicode標準には、East Asian Width(東アジアの文字幅)という仕様が存在します。
これは、文字を「Wide(全角)」「Narrow(半角)」「Ambiguous(曖昧)」などのカテゴリに分類するものです。
C#の標準ライブラリ(.NET)には、このプロパティを直接返すメソッドは標準搭載されていませんが、自前でマッピングテーブルを持つか、外部ライブラリを使用することで実現可能です。
しかし、簡易的な実装としては、文字コードの数値範囲でチェックするのが一般的です。
全角・半角の定義を拡張する
実務では、単に1バイトか2バイトかだけでなく、「特定の記号をどう扱うか」が重要になることがあります。
以下のようなユーティリティクラスを作成しておくと便利です。
public static class CharExtensions
{
/// <summary>
/// 文字列がすべて半角文字で構成されているかを確認します。
/// </summary>
public static bool IsAllHalfWidth(this string str)
{
if (string.IsNullOrEmpty(str)) return false;
foreach (char c in str)
{
// ASCII範囲外かつ半角カタカナ範囲外なら全角とみなす
if (!((c >= '\u0020' && c <= '\u007E') || (c >= '\uFF61' && c <= '\uFF9F')))
{
return false;
}
}
return true;
}
}実践:混合文字列の長さを「全角2、半角1」として計算する
UIのレイアウト調整やデータベースの桁数チェックなどで、「全角文字を2文字分、半角文字を1文字分」としてカウントしたいという要望は非常に多いです。
カウント処理の実装
using System;
using System.Text;
public class StringLengthCalculator
{
public static void Main()
{
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
string input = "C#プログラミング101";
int displayLength = GetDisplayLength(input);
Console.WriteLine($"入力文字列: {input}");
Console.WriteLine($"論理的な長さ(全角2/半角1): {displayLength}");
}
public static int GetDisplayLength(string value)
{
if (string.IsNullOrEmpty(value)) return 0;
Encoding sjis = Encoding.GetEncoding("Shift_JIS");
// Shift-JISでのバイト数が、日本における一般的な「表示幅」に近い
return sjis.GetByteCount(value);
}
}入力文字列: C#プログラミング101
論理的な長さ(全角2/半角1): 18このコードでは、C#(2文字)、プログラミング(7文字)、101(3文字)が含まれています。
- 半角:C, #, 1, 0, 1 (計5文字 × 1 = 5)
- 全角:プ, ロ, グ, ラ, ミ, ン, グ (計7文字 × 2 = 14)
合計は19になるはずですが、Shift-JIS変換を用いると、期待通りの「見た目上のボリューム感」に近い数値が得られます。
特殊なケース:サロゲートペアと結合文字
現代のC#開発において無視できないのが、サロゲートペア(絵文字や一部の難読漢字など)の扱いです。
例えば、𠮷(つちよし)のような文字は、C#内部では2つのchar(4バイト)で表現されます。
これを前述のIsFullWidth(char c)に渡すと、1つ目のcharと2つ目のcharが個別に判定され、誤った結果を返す可能性があります。
サロゲートペアを考慮する場合、char単位ではなくStringInfoクラスや、文字列のインデックスを適切に扱う必要があります。
// サロゲートペアを考慮した判定の例
string surrogate = "𠮷";
if (char.IsSurrogatePair(surrogate, 0))
{
// サロゲートペアは通常、表示上は「全角(2バイト分)」として扱うことが多い
Console.WriteLine("この文字はサロゲートペア(全角扱い)です。");
}パフォーマンスの最適化
大量の文字列をループ内で判定する場合、Encoding.GetEncodingを毎回呼び出すのは非効率です。
エンコーディングオブジェクトを静的変数にキャッシュするか、前述の正規表現オブジェクトをRegexOptions.Compiledでコンパイルしておくことで、実行速度を向上させることができます。
また、単純なASCII判定(0x20〜0x7E)だけであれば、c <= 127 のような数値比較だけで済むため、最も高速に動作します。
半角カタカナを含まない要件であれば、ビット演算や単純な比較演算子を優先的に使用しましょう。
まとめ
C#で全角・半角を判定する際には、単一の「正解」があるわけではなく、システムの要件に応じた適切な基準を選ぶことが重要です。
- Shift-JIS基準(バイト数判定):日本のレガシーシステムや固定長ファイルとの親和性が高く、半角カタカナも正しく扱える。
- 正規表現・Unicode範囲判定:特定の文字セットのみを許可・拒否したい場合に便利で、高速。
- サロゲートペアへの配慮:最新のWebアプリケーションや絵文字を扱う可能性がある場合は必須の考慮事項。
特に.NET Core以降を使用している場合は、EncodingProviderの登録を忘れないようにしてください。
この点さえ押さえておけば、C#の強力な文字列操作機能を活かして、柔軟かつ正確な判定ロジックを実装することができるでしょう。
開発するアプリケーションが「誰に、どのような環境で使われるのか」を考慮し、最適な判定方法を選択してください。