C#における文字列比較は、アプリケーションの動作の正確性、セキュリティ、そしてパフォーマンスに直結する非常に重要な要素です。
単純な == 演算子による比較から、文化圏(カルチャ)を考慮した並べ替え、あるいはメモリ効率を極限まで追求した最新の比較手法まで、その選択肢は多岐にわたります。
文字列比較を正しく理解していないと、特定の言語環境でのみバグが発生したり、不必要なメモリ割り当て(アロケーション)によってアプリケーションの動作が重くなったりするリスクがあります。
本記事では、プロフェッショナルなC#開発者が知っておくべき文字列比較の基本から、最新の.NET環境における最適な実装パターンまでを徹底的に解説します。
文字列比較の基本:演算子とメソッドの使い分け
C#で文字列を比較する際、最も一般的に使われるのは == 演算子と Equals メソッドです。
まずはこれらの違いと使い分けを明確にしましょう。
== 演算子による比較
C#の == 演算子は、文字列型(string)に対してオーバーロードされており、「値の比較」を行います。
つまり、2つの文字列変数が異なるメモリ参照を指していても、中身の文字列が同一であれば true を返します。
using System;
class Program
{
static void Main()
{
string str1 = "Hello";
string str2 = new string(new char[] { 'H', 'e', 'l', 'l', 'o' });
// 値が同じなので true
Console.WriteLine($"== 比較: {str1 == str2}");
// 片方が null の場合も安全に比較可能
string str3 = null;
Console.WriteLine($"null との比較: {str1 == str3}");
}
}== 比較: True
null との比較: False== 演算子の最大のメリットは、どちらかの変数が null であっても例外(NullReferenceException)が発生しないという点にあります。
Equals メソッドによる比較
一方、Equals メソッドは、インスタンスメソッドとして呼び出す方法と、静的メソッドとして呼び出す方法の2種類があります。
string str1 = "Hello";
string str2 = "hello";
// インスタンスメソッド(str1 が null だと例外が発生する)
bool result1 = str1.Equals(str2);
// 静的メソッド(null 安全)
bool result2 = string.Equals(str1, str2);インスタンスメソッドの Equals は、単純な比較においては == と同じ結果を返しますが、StringComparison 列挙型を指定できるという強力な特徴を持っています。
これにより、大文字小文字の区別やカルチャ(言語規則)の指定が可能になります。
StringComparison 列挙型の重要性
C#の文字列比較において、最も重要な概念が StringComparison 列挙型です。
これを適切に指定することで、プログラムの意図を明確にし、予期せぬ動作を防ぐことができます。
各オプションの違い
StringComparison には主に以下の6つの値があります。
| 値 | 説明 | 用途 |
|---|---|---|
Ordinal | 各文字のバイナリ値を直接比較します。 | ID、パス、内部的なキーの比較 |
OrdinalIgnoreCase | バイナリ値を大文字小文字を無視して比較します。 | 設定値のキー、URLのパス比較 |
CurrentCulture | 実行環境の言語設定に基づいて比較します。 | ユーザーに表示するリストの並び替え |
CurrentCultureIgnoreCase | 実行環境の言語設定に基づき、大文字小文字を無視します。 | UI上での検索やフィルタリング |
InvariantCulture | 言語に依存しない不変のカルチャで比較します。 | 異なるOS間で共通して扱うデータの比較 |
InvariantCultureIgnoreCase | 不変カルチャで大文字小文字を無視して比較します。 | 永続化された識別子の比較 |
Ordinal 比較を優先すべき理由
多くの開発者が CurrentCulture をデフォルトの動作と誤解しがちですが、プログラム内部のロジック(ファイルパス、XMLタグ名、内部IDなど)においては、必ず Ordinal または OrdinalIgnoreCase を使用すべきです。
理由は以下の2点です。
- パフォーマンス: 言語的な規則(アクセント記号の処理など)を考慮しないため、最も高速です。
- セキュリティ: 特定の言語(トルコ語の「i」など)において、大文字小文字変換の結果が一般的な英語と異なる場合があり、これが原因でセキュリティホールが生じることがあります(トルコ語問題)。
大文字小文字を無視する比較の最適解
「大文字小文字を区別せずに比較したい」というケースは非常に多いですが、間違った方法を選択するとパフォーマンスを著しく低下させます。
やってはいけない実装:ToLower() / ToUpper()
初心者がよくやってしまうのが、両方の文字列を一度小文字(または大文字)に変換してから比較する方法です。
// 非推奨な例
if (str1.ToLower() == str2.ToLower())
{
// 処理
}この方法は、比較のためだけに新しい文字列インスタンスを生成するため、メモリ(ヒープ領域)を浪費し、ガベージコレクション(GC)の負荷を高めます。
特にループ内でこれを行うと、アプリケーション全体のパフォーマンスに悪影響を及ぼします。
推奨される実装:StringComparison の指定
正解は、前述の StringComparison を指定する方法です。
using System;
class Program
{
static void Main()
{
string input = "User_Name";
string target = "user_name";
// メモリ割り当てなしで、大文字小文字を無視して比較
if (string.Equals(input, target, StringComparison.OrdinalIgnoreCase))
{
Console.WriteLine("一致しました(大文字小文字無視)");
}
}
}一致しました(大文字小文字無視)この方法であれば、新しい文字列を生成することなく比較処理が行われるため、非常に効率的です。
文字列の包含・前方・後方一致
単なる一致確認だけでなく、文字列が含まれているか、あるいは特定の文字で始まっているかを確認する場合も同様のルールが適用されます。
StartsWith, EndsWith, Contains
これらのメソッドも、.NET Core 以降(.NET 5/6/7/8+)では StringComparison を引数に取ることができます。
string fileName = "Report_2024.PDF";
// 前方一致
bool starts = fileName.StartsWith("report", StringComparison.OrdinalIgnoreCase);
// 後方一致
bool ends = fileName.EndsWith(".pdf", StringComparison.OrdinalIgnoreCase);
// 包含確認
bool contains = fileName.Contains("2024", StringComparison.Ordinal);
Console.WriteLine($"Start: {starts}, End: {ends}, Contains: {contains}");Start: True, End: True, Contains: True特に Contains メソッドは、古い .NET Framework では StringComparison を受け取れなかったため、IndexOf を代用する手法が一般的でしたが、現代のC#においては直接指定するのがベストプラクティスです。
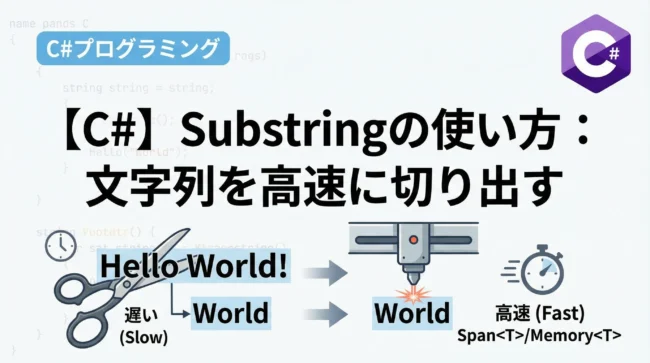
パフォーマンスを極める:Span<char> による比較
最新のC#(C# 7.2以降、および .NET Core 以降)では、ReadOnlySpan<char> を活用することで、「文字列の一部を切り出して比較する」際のパフォーマンスを劇的に向上させることができます。
例えば、長い文字列の中にある特定の部分が特定の文字列と一致するかを確認する場合、従来は Substring を使っていました。
しかし、Substring は新しい文字列を生成してしまいます。
using System;
class PerformanceDemo
{
static void Main()
{
string data = "ID:12345-TYPE:ADMIN";
// Substring は新しい文字列を作成する(メモリ消費あり)
string sub = data.Substring(3, 5);
bool resultOld = sub == "12345";
// Span を使うと、メモリをコピーせずに「参照」だけで比較できる
ReadOnlySpan<char> span = data.AsSpan();
bool resultNew = span.Slice(3, 5).Equals("12345", StringComparison.Ordinal);
Console.WriteLine($"結果: {resultNew}");
}
}結果: TrueSpan<T> を利用することで、アロケーションをゼロ(Zero-allocation)に抑えつつ、高速な文字列操作が可能になります。
高頻度で実行されるパース処理などでは、この手法が必須となります。
並べ替えと StringComparer
文字列のコレクション(ListやDictionary)をソートしたり、検索したりする場合、IEqualityComparer<string> や IComparer<string> を実装したクラスが必要になります。
これらを自作する必要はなく、StringComparer クラスが提供する定義済みのインスタンスを使用します。
Dictionary での使用例
ハッシュマップ(Dictionary)のキーとして文字列を使用し、大文字小文字を区別したくない場合は、コンストラクタで比較器を渡します。
using System;
using System.Collections.Generic;
class DictionaryDemo
{
static void Main()
{
// キーの大文字小文字を無視する辞書を作成
var settings = new Dictionary<string, string>(StringComparer.OrdinalIgnoreCase);
settings["Theme"] = "Dark";
// "theme"(小文字)でアクセスしても取得可能
Console.WriteLine($"Value: {settings["theme"]}");
}
}Value: Darkこれを指定しない場合、デフォルトでは Ordinal(大文字小文字を区別する)動作となり、settings["theme"] は KeyNotFoundException をスローします。
null や空文字の扱い
比較を行う際、対象の文字列が null または空文字("")である可能性を考慮する必要があります。
IsNullOrEmpty と IsNullOrWhiteSpace
比較の「前」に状態をチェックする場合は、以下のメソッドを使用します。
string.IsNullOrEmpty(str):nullまたは長さ 0 の文字列かどうか。string.IsNullOrWhiteSpace(str):null、空文字、または半角/全角スペースのみの文字列かどうか。
string s1 = " ";
Console.WriteLine(string.IsNullOrEmpty(s1)); // False
Console.WriteLine(string.IsNullOrWhiteSpace(s1)); // Trueユーザー入力のバリデーションなどでは、IsNullOrWhiteSpace を使用するのが一般的です。
特殊な比較:自然順ソート
Windowsのエクスプローラーのように、”File1.txt”, “File2.txt”, “File10.txt” を数値の大きさ順に並べたい場合があります。
標準の StringComparison.Ordinal では、文字列としての比較になるため、”File10.txt” が “File2.txt” よりも前に来てしまいます。
このような「自然順(Natural Sort)」を実現するには、Windows API(shlwapi.dll)を呼び出すか、専用の比較ロジックを実装する必要があります。
標準ライブラリだけでは対応できない特殊なケースがあることも覚えておきましょう。
パフォーマンス計測:ベンチマークの視点
実際の開発において、どの比較方法がどれほど速いのかを知ることは、最適化の指針になります。
一般的に、速度の序列は以下の通りです。
- Ordinal (最速:CPU命令レベルの比較に近い)
- OrdinalIgnoreCase (高速:テーブル参照による大文字小文字変換を伴う)
- InvariantCulture (低速:複雑な文字マッピング規則を適用)
- CurrentCulture (最遅:OSの地域設定に依存する動的な規則を適用)
大量のデータを処理する場合は、可能な限り Ordinal 系統を選択するのが鉄則です。
まとめ
C#における文字列比較は、単なる「一致確認」以上の奥深さを持っています。
状況に応じた最適な選択を行うためのポイントをまとめます。
- 内部ロジックの比較: パフォーマンスと安全性の観点から
StringComparison.Ordinalを使用する。 - 大文字小文字を無視する:
ToLower()を使わず、StringComparison.OrdinalIgnoreCaseを指定する。 - ユーザー向けの表示・ソート: 言語的な直感を優先するため
StringComparison.CurrentCultureを検討する。 - null 安全:
==演算子またはstring.Equals静的メソッドを活用する。 - 高負荷な処理:
ReadOnlySpan<char>を使って、不必要な文字列生成(アロケーション)を排除する。
これらのルールを徹底することで、バグが少なく、かつ高速に動作する堅牢なアプリケーションを構築することができます。
最新の.NETでは文字列操作の最適化が日々進んでいますが、その基礎となるのは常に StringComparison の正しい選択です。
日常的なコーディングから、これらの「最適解」を意識的に使い分けていきましょう。