Javaプログラミングにおいて、データ集合の操作は避けて通れない重要な要素です。
かつてのJavaでは、リストや配列の要素を処理するために (for文や拡張for文などのループ処理) を記述するのが一般的でした。
しかし、Java 8で導入された (Stream API) は、そのパラダイムを劇的に変えました。
Stream APIを活用することで、宣言的で読みやすく、かつ保守性の高いコードを記述することが可能になります。
本記事では、Stream APIの基本的な概念から、実務で多用される頻出メソッド、さらに一歩踏み込んだ応用テクニックまでを網羅的に解説します。
最新のJava開発において必須となるこの強力なツールをマスターし、より洗練されたコードを目指しましょう。
Stream APIとは何か
Stream APIは、配列やリストといったデータソースに対して、(「何をしたいか」を宣言的に記述するための仕組み) です。
従来の命令型プログラミング(どのように処理するかを逐一記述する手法)に対し、Stream APIは関数型プログラミングの考え方を取り入れています。
Stream APIの主な特徴
Stream APIを利用するメリットは多岐にわたりますが、主に以下の3点が挙げられます。
- コードの簡潔化と可読性の向上
ループ変数や条件分岐の記述が減り、処理の意図が明確になります。
- 遅延評価(Lazy Evaluation)
終端操作が呼び出されるまで、中間操作の処理は実行されません。
これにより、効率的なデータ処理が可能になります。
- 並列処理の容易化
parallelStream()を利用することで、マルチコアCPUを活かした並列処理を簡単に実装できます。
重要な点として、Stream APIは (元のデータソースを直接変更しない) という性質を持っています。
ストリームはデータの「流れ」を扱うものであり、データそのものを保持するコンテナではないことを理解しておく必要があります。
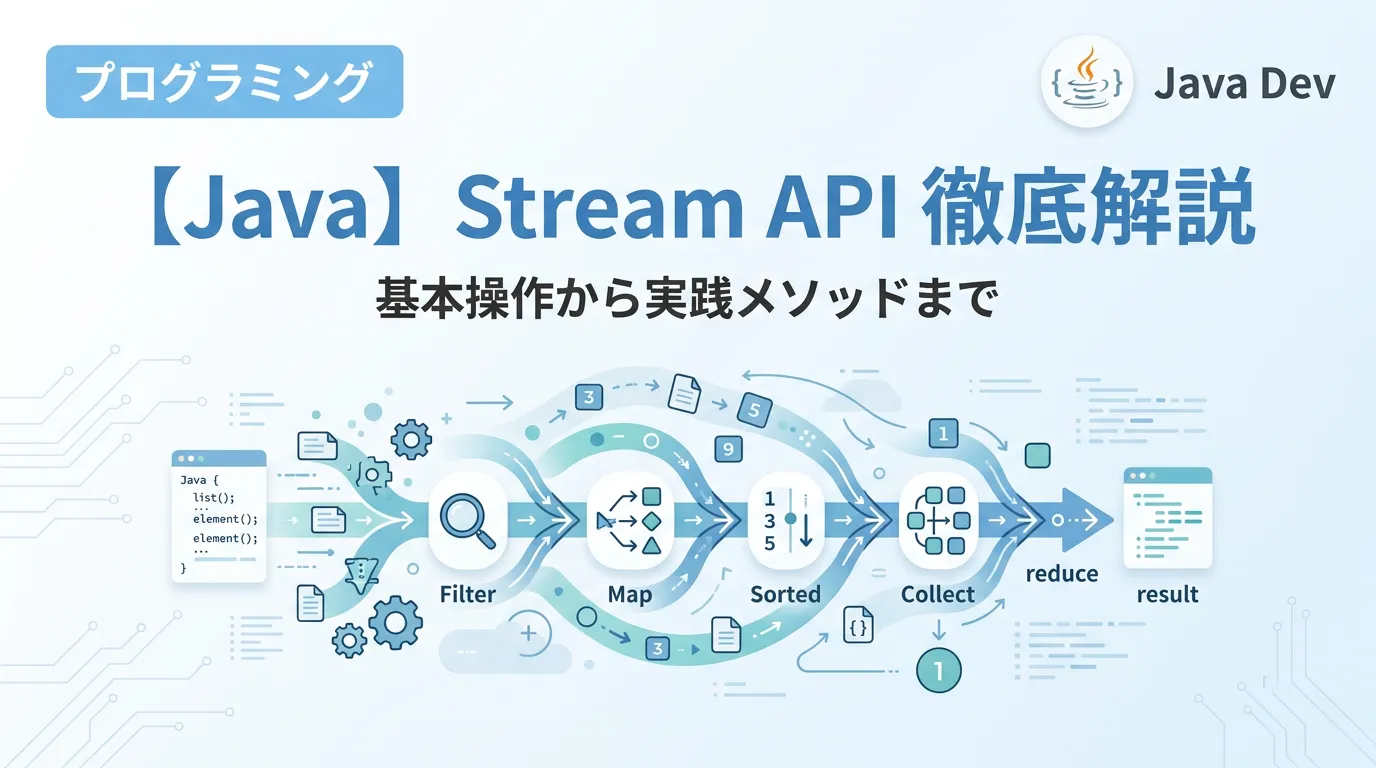
Stream操作の3つのステップ
Stream APIの操作は、常に以下の3つのフェーズで構成されます。
| フェーズ | 役割 | 主なメソッド |
|---|---|---|
| (1. 生成 (Source)) | コレクションや配列からストリームを作成する | (stream()), (of()), (Arrays.stream()) |
| (2. 中間操作 (Intermediate)) | データのフィルタリングや変換を行う(連結可能) | (filter()), (map()), (sorted()) |
| (3. 終端操作 (Terminal)) | 結果を収集したり、計算結果を返したりする | (collect()), (forEach()), (reduce()) |
このパイプライン構造を意識することが、Stream APIを使いこなすための第一歩です。
ストリームの生成方法
まずは、処理の対象となるストリームを生成する方法を見ていきましょう。
Javaでは様々なデータソースからストリームを作成できます。
コレクションからの生成
最も一般的な方法は、(List) や (Set) などの (Collection) インターフェースが持つ (stream()) メソッドを使用する方法です。
import java.util.List;
import java.util.stream.Stream;
public class StreamSourceExample {
public static void main(String[] args) {
List<String> fruits = List.of("apple", "banana", "cherry");
// Listからストリームを生成
Stream<String> fruitStream = fruits.stream();
// 処理の実行
fruitStream.forEach(System.out::println);
}
}apple
banana
cherry配列からの生成
配列の場合は、(Arrays.stream()) メソッドを利用します。
import java.util.Arrays;
import java.util.stream.Stream;
public class ArrayStreamExample {
public static void main(String[] args) {
String[] colors = {"Red", "Green", "Blue"};
// 配列からストリームを生成
Stream<String> colorStream = Arrays.stream(colors);
colorStream.forEach(System.out::println);
}
}任意の値や数値範囲からの生成
特定の値を直接指定する場合は (Stream.of()) を、連続した数値を扱う場合は (IntStream.range()) などを使用すると便利です。
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class DirectStreamExample {
public static void main(String[] args) {
// Stream.ofによる生成
Stream<Integer> directStream = Stream.of(10, 20, 30);
// 1から5未満(1, 2, 3, 4)の数値を生成
IntStream rangeStream = IntStream.range(1, 5);
rangeStream.forEach(System.out::print); // 1234 と出力
}
}中間操作:データの加工と絞り込み
中間操作は、ストリームの要素を加工したり、特定の条件でフィルタリングしたりするために使用されます。
中間操作の最大の特徴は、(戻り値が常に別のStreamであること) です。
これにより、メソッドチェーン(連結)が可能になります。
filter:条件による絞り込み
(filter()) メソッドは、引数に渡された述語(Predicate)が (true) を返す要素のみを抽出します。
import java.util.List;
public class FilterExample {
public static void main(String[] args) {
List<String> names = List.of("Tanaka", "Sato", "Suzuki", "Takahashi");
// "T"で始まる名前だけを抽出
names.stream()
.filter(name -> name.startsWith("T"))
.forEach(System.out::println);
}
}Tanaka
Takahashimap:要素の変換
(map()) メソッドは、各要素に対して関数(Function)を適用し、その結果を新しいストリームとして返します。
型を変換することも可能です(例:StringからIntegerへ)。
import java.util.List;
public class MapExample {
public static void main(String[] args) {
List<String> names = List.of("apple", "banana", "orange");
// 全ての要素を大文字に変換
names.stream()
.map(String::toUpperCase)
.forEach(System.out::println);
}
}distinct:重複の除去
(distinct()) は、要素の重複((equals()) メソッドによる比較)を取り除きます。
import java.util.List;
public class DistinctExample {
public static void main(String[] args) {
List<Integer> numbers = List.of(1, 2, 2, 3, 4, 4, 5);
numbers.stream()
.distinct()
.forEach(System.out::print);
}
}12345sorted:要素の並べ替え
(sorted()) を使用すると、要素を自然順序、または指定したコンパレータに従って並べ替えることができます。
import java.util.List;
import java.util.Comparator;
public class SortedExample {
public static void main(String[] args) {
List<Integer> nums = List.of(5, 2, 8, 1, 9);
// 昇順にソート
nums.stream()
.sorted()
.forEach(System.out::print);
System.out.println();
// 降順にソート
nums.stream()
.sorted(Comparator.reverseOrder())
.forEach(System.out::print);
}
}flatMap:ストリームの平坦化
少し複雑な操作として (flatMap()) があります。
これは、要素が「リストのリスト」のような階層構造になっている場合に、それを1つのストリームに展開(平坦化)するために使用されます。
import java.util.List;
import java.util.Collection;
public class FlatMapExample {
public static void main(String[] args) {
List<List<String>> nestedList = List.of(
List.of("A", "B"),
List.of("C", "D", "E")
);
// 階層を壊して1つのストリームにする
nestedList.stream()
.flatMap(Collection::stream)
.forEach(System.out::print);
}
}ABCDE終端操作:結果の導出
終端操作はストリームの処理を締めくくり、最終的な結果(List、単一の値、あるいは副作用としての出力)を得るために行われます。
終端操作が実行されると、そのストリームは (消費され、再利用はできなくなります)。
collect:結果をコレクションにまとめる
最も頻繁に使用される終端操作が (collect()) です。
特に (Collectors) ユーティリティクラスと組み合わせて、結果を (List) や (Map) に変換します。
import java.util.List;
import java.util.stream.Collectors;
public class CollectExample {
public static void main(String[] args) {
List<String> items = List.of("Pen", "Note", "Eraser");
// 文字数が4以上のものをListとして収集
List<String> filteredList = items.stream()
.filter(s -> s.length() >= 4)
.collect(Collectors.toList());
System.out.println(filteredList);
}
}forEach:各要素に対する繰り返し処理
(forEach()) は、ストリームの各要素に対してアクション(Consumer)を実行します。
主にデバッグ時のコンソール出力や、外部システムへの通知などに使用されます。
reduce:値を1つに集約する
(reduce()) は、ストリーム内の全要素を組み合わせて1つの結果を導き出します。
合計値の計算や、文字列の連結などに適しています。
import java.util.List;
import java.util.Optional;
public class ReduceExample {
public static void main(String[] args) {
List<Integer> numbers = List.of(1, 2, 3, 4, 5);
// 合計を計算 (初期値0に対して順次加算)
int sum = numbers.stream()
.reduce(0, (a, b) -> a + b);
System.out.println("Sum: " + sum);
}
}findFirst / anyMatch:検索と判定
これらはデータの存在確認や特定の要素の取得に使用されます。
(findFirst()):最初の要素を(Optional)で返します。(anyMatch()):条件に一致する要素が1つでもあるかチェックし、(boolean)を返します。
import java.util.List;
public class MatchExample {
public static void main(String[] args) {
List<String> names = List.of("Alice", "Bob", "Charlie");
// "B"で始まる名前が含まれているか?
boolean hasB = names.stream().anyMatch(n -> n.startsWith("B"));
System.out.println("Contains B: " + hasB);
}
}高度な集計操作:groupingByの活用
実務において非常に強力なのが、(Collectors.groupingBy()) です。
SQLの (GROUP BY) 句のように、特定のキーでデータをグループ化することができます。
以下の例では、従業員(Employee)リストを役職(Department)ごとにグループ化します。
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
class Employee {
String name;
String department;
Employee(String name, String department) {
this.name = name;
this.department = department;
}
public String getDepartment() { return department; }
@Override
public String toString() { return name; }
}
public class GroupingExample {
public static void main(String[] args) {
List<Employee> employees = List.of(
new Employee("Tanaka", "Sales"),
new Employee("Sato", "IT"),
new Employee("Suzuki", "Sales"),
new Employee("Ito", "IT")
);
// 部署ごとにグループ化
Map<String, List<Employee>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
System.out.println(byDept);
}
}{IT=[Sato, Ito], Sales=[Tanaka, Suzuki]}このように、数行のコードで複雑な集計ロジックを実装できるのが Stream API の真骨頂です。
並列ストリーム(Parallel Stream)の使い所と注意点
大量のデータを処理する場合、(parallelStream()) を使用することで処理時間を短縮できる可能性があります。
これは、内部的に (ForkJoinPool) を使用して処理を分割し、複数のスレッドで並列実行する仕組みです。
並列化の例
long count = largeList.parallelStream()
.filter(e -> e.isValid())
.count();注意すべきポイント
並列ストリームは常に高速になるわけではありません。
以下の点に注意が必要です。
- オーバーヘッド
スレッドの分割や結合にはコストがかかります。
データ量が少ない場合は、通常のストリーム(逐次処理)の方が高速です。
- スレッドセーフ
ストリーム内で行う処理は、外部の状態を変化させない(サイドエフェクトがない)純粋関数である必要があります。
- 順序性
forEach()を並列ストリームで使うと、実行順序が保証されません。順序が必要な場合は
forEachOrdered()を検討してください。
基本的には (「本当に必要になるまで並列化しない」) という方針が推奨されます。
Stream APIを使用する際のベストプラクティス
Stream APIを正しく、そして効率的に活用するためのポイントをまとめます。
1. 中間操作の順序を最適化する
例えば、膨大なデータに対して (map()) で重い変換を行った後に (filter()) で大部分を捨てるのは非効率です。
先に (filter()) を行い、対象データを絞り込んでから (map()) を適用するようにしましょう。
2. サイドエフェクト(副作用)を避ける
ストリームの内部で外部の変数を書き換えたり、リストに要素を追加したりすることは避けましょう。
これを行うと、並列実行時に予期しない動作を引き起こすだけでなく、コードの可読性も低下します。
結果が必要な場合は、必ず (collect()) や (reduce()) で受け取るようにします。
3. Optionalを適切に処理する
(findFirst()) や (max()) などの終端操作は (Optional) を返します。
これに対し、安易に (get()) を呼び出すのではなく、(orElse()) や (ifPresent()) を使用して、値が存在しない場合のハンドリングを記述しましょう。
4. デバッグにはpeek()を活用する
ストリームの途中でデータがどのように変化しているかを確認したい場合、(peek()) メソッドが役立ちます。
list.stream()
.filter(s -> s.length() > 3)
.peek(e -> System.out.println("Filtered: " + e)) // デバッグ用
.map(String::toUpperCase)
.collect(Collectors.toList());まとめ
Javaの Stream API は、単なるループの代替手段ではなく、(「データのパイプライン処理」という新しい考え方) を提供するものです。
本記事で解説した以下のポイントを振り返りましょう。
- 生成・中間操作・終端操作 の3ステップで構成される。
- filter や map などのメソッドを連結して、宣言的に処理を記述できる。
- Collectors.groupingBy などの高度な集計機能により、複雑なロジックを簡潔に実装できる。
- 遅延評価 により、必要な処理だけが効率的に実行される。
- 並列処理 は強力だが、データ量やスレッド安全性を考慮して慎重に適用する。
Stream API を習得することで、Javaでのプログラミングはより楽しく、そして生産的なものになります。
最初は慣れないかもしれませんが、既存の (for) 文を少しずつ Stream に書き換えてみることから始めてみてください。
現代のJavaエンジニアにとって、この流麗なAPIを使いこなすことは、保守性の高い高品質なソフトウェアを開発するための必須スキルと言えるでしょう。