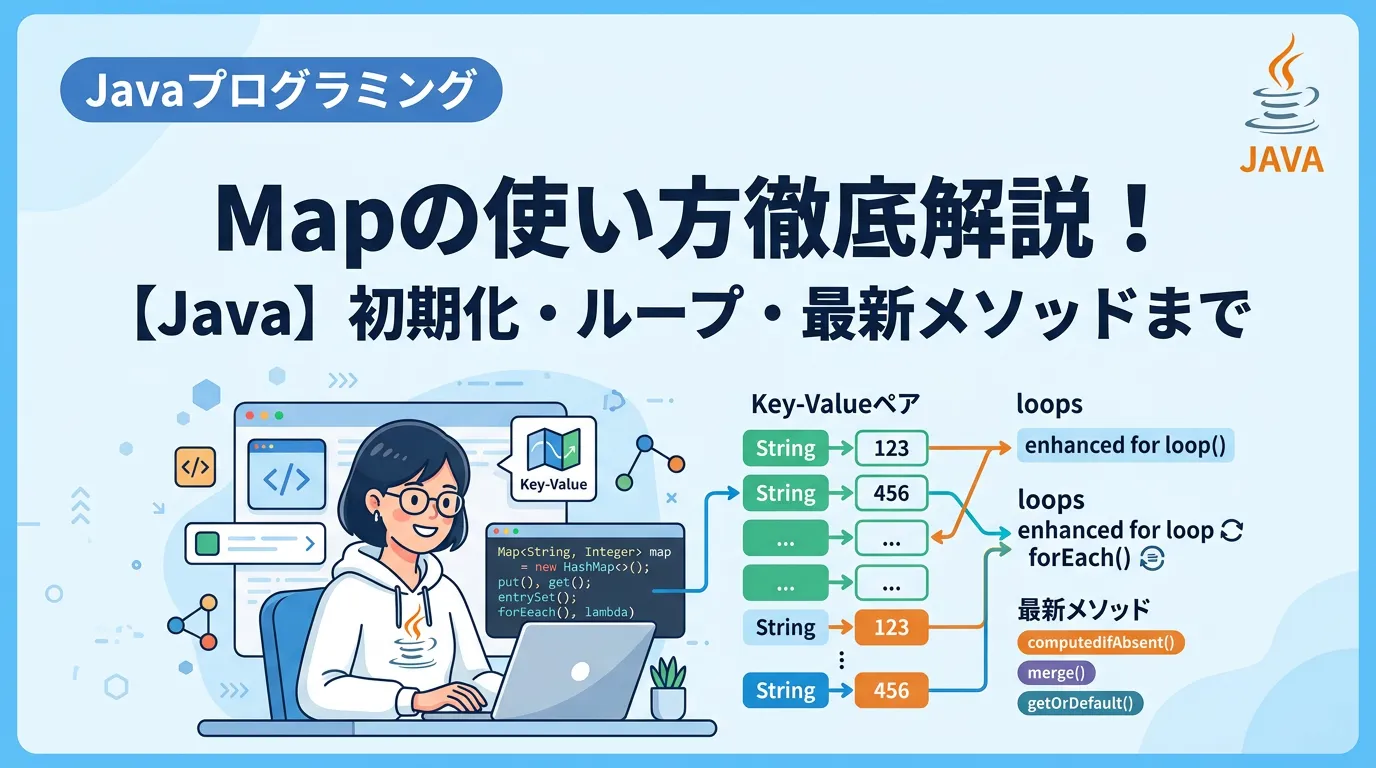
Javaプログラミングにおいて、データの管理は避けて通れない重要な要素です。
その中でも「Map」は、特定のキーと値をペアにして保持するデータ構造として、実務のあらゆる場面で活用されています。
ユーザーIDからユーザー情報を検索したり、設定ファイルの内容をメモリ上に保持したりと、その用途は多岐にわたります。
本記事では、JavaのMapインターフェースの基本的な概念から、主要な実装クラスの使い分け、さらにはモダンなJava開発で欠かせない便利なメソッドや最新のテクニックまでを網羅的に解説します。
初心者の方には分かりやすく、中級者以上の方には再発見があるような、実践的なコード例を交えてご紹介します。
Mapの基本概念とインターフェース
JavaにおけるMapは、キー (Key) と値 (Value) を対にして保持するデータ構造です。
数学的な「写像」の概念に基づており、特定のキーを指定することで、それに対応する値を効率的に取得できるのが最大の特徴です。
Mapは java.util パッケージに含まれるインターフェースであり、要素の重複や順序の保持に関するルールが List や Set とは異なります。
Mapの主な特徴
Mapを利用する上で理解しておくべき基本的なルールは以下の通りです。
- キーの重複は許されない
一つのMap内に、同じ値を持つキーを複数格納することはできません。
既存のキーに対して新しい値を
putすると、古い値は上書きされます。- 値の重複は可能
異なるキーに対して、同じ値を割り当てることは可能です。
- キーによる高速な検索
インデックス番号ではなく、意味のある「キー」を使ってデータにアクセスできるため、特定のデータを瞬時に取り出す用途に適しています。
Mapの主要な実装クラスとその使い分け
Mapはインターフェースであるため、実際にプログラムで使用する際はその「実装クラス」を選択する必要があります。
Javaには用途に応じて複数の実装クラスが用意されています。
HashMap(最も標準的なMap)
HashMap は、最も頻繁に利用される実装クラスです。
ハッシュテーブルというアルゴリズムを利用しており、データの追加、削除、検索が非常に高速です。
- 順序
要素の格納順序は保持されません。
- nullの扱い
キーおよび値に
nullを許容します。- パフォーマンス
基本的には最高速ですが、マルチスレッド環境での安全性(スレッドセーフ)はありません。
LinkedHashMap(順序を保持するMap)
LinkedHashMap は、HashMap の機能に加えて、要素が追加された順序を記憶するクラスです。
- 順序
要素を追加した順序、または最後にアクセスした順序を維持します。
- 用途
設定情報の保持や、
LRU(Least Recently Used)キャッシュの実装などに適しています。
TreeMap(キーでソートされるMap)
TreeMap は、キーの「自然順序(数値の昇順や文字列の辞書順)」または指定した Comparator に従って、常にキーがソートされた状態を保つクラスです。
- 順序
キーによってソートされます。
- パフォーマンス
HashMapよりも低速ですが、範囲検索(特定の範囲のキーを抽出するなど)に強みを持ちます。- nullの扱い
キーに
nullを入れることはできません(比較ができないため)。
各クラスの比較表
| クラス名 | 順序保持 | ソート | キーのnull | 特徴 |
|---|---|---|---|---|
HashMap | なし | なし | 許可 | 高速・一般的 |
LinkedHashMap | 追加順 | なし | 許可 | 順序が重要 |
TreeMap | ソート順 | あり | 不可 | キーで並べたい |
ConcurrentHashMap | なし | なし | 不可 | スレッドセーフ |
Mapの生成と初期化方法
Javaのバージョンアップに伴い、Mapの初期化方法は非常に簡潔になりました。
用途に合わせて最適な方法を選びましょう。
1. インスタンス化による標準的な初期化
最も古典的な方法です。
要素を動的に追加していく場合に適しています。
import java.util.HashMap;
import java.util.Map;
public class MapExample {
public static void main(String[] args) {
// インターフェース型で宣言し、実装クラスを代入するのが一般的
Map<String, Integer> fruitStock = new HashMap<>();
// 要素の追加
fruitStock.put("Apple", 10);
fruitStock.put("Banana", 20);
fruitStock.put("Orange", 15);
System.out.println(fruitStock);
}
}{Apple=10, Banana=20, Orange=15}2. Map.of による不変Mapの生成 (Java 9以降)
Java 9で導入された Map.of() メソッドを使用すると、少ない記述で変更不可能な(Immutable)Mapを作成できます。
テストコードや固定の定数定義に非常に便利です。
// 最大10ペアまで指定可能
Map<String, String> config = Map.of(
"host", "localhost",
"port", "8080",
"timeout", "5000"
);
// 注意:このMapに対して put() や remove() を呼ぶと UnsupportedOperationException が発生します3. Map.ofEntries による多数の要素の初期化
要素数が10を超える不変Mapを作りたい場合は、 Map.ofEntries を使用します。
import java.util.Map;
import static java.util.Map.entry;
Map<Integer, String> monthMap = Map.ofEntries(
entry(1, "January"),
entry(2, "February"),
entry(3, "March"),
// ... 中略
entry(12, "December")
);Mapの基本操作:データの追加・取得・削除・確認
Mapでよく使われる基本的なメソッドを整理します。
これらは日常的なコーディングで最も頻繁に登場します。
データの追加と更新 (put)
put(K key, V value) メソッドを使用します。
- 指定したキーが存在しない場合:新しく追加されます。
- 指定したキーが既に存在する場合:値が上書きされ、メソッドの戻り値として古い値が返されます。
データの取得 (get, getOrDefault)
通常、 get(key) を使用しますが、キーが存在しない場合は null が返ります。
Java 8で導入された getOrDefault を使うと、キーがない場合のデフォルト値を指定でき、NullPointerExceptionのリスクを減らせます。
Map<String, Integer> scores = new HashMap<>();
scores.put("Alice", 90);
// 通常の取得
Integer aliceScore = scores.get("Alice"); // 90
Integer bobScore = scores.get("Bob"); // null
// デフォルト値付きの取得
int finalBobScore = scores.getOrDefault("Bob", 0); // 0存在確認 (containsKey, containsValue)
特定のキーや値が含まれているかを判定します。
if (scores.containsKey("Alice")) {
System.out.println("Aliceのスコアは登録済みです");
}削除 (remove, clear)
remove(key):指定したキーのペアを削除します。remove(key, value):キーと値の両方が一致する場合のみ削除します。clear():すべての要素を削除します。
Mapのループ処理(繰り返し)
Mapの全要素を走査する方法はいくつかありますが、Java 8以降は forEach メソッドやStream APIを使うのが主流です。
1. forEachメソッド(推奨)
ラムダ式を使用して、キーと値を直接扱えます。
記述が最もシンプルです。
Map<String, String> map = Map.of("Japan", "Tokyo", "USA", "Washington");
map.forEach((country, capital) -> {
System.out.println(country + " の首都は " + capital + " です");
});2. entrySet() による拡張for文
Mapの内部クラスである Map.Entry を使用します。
ループ内でMapの値を変更したり、特定の条件で削除したりする場合(Iteratorを併用)に有効です。
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue());
}3. keySet() や values() の使用
キーのみ、あるいは値のみが必要な場合に使用します。
ただし、キーのリストを取得してから get(key) をループ内で呼び出すのはパフォーマンス的に非効率(ハッシュ計算が二重に発生するため)なので、キーと値の両方が必要な場合は entrySet() を使いましょう。
Java 8以降で追加された便利な最新メソッド
Java 8以降、Mapインターフェースには関数型プログラミングを取り入れた非常に強力なメソッドが追加されました。
これらを使いこなすことで、複雑な条件分岐を排除したクリーンなコードが書けるようになります。
computeIfAbsent:値がない場合のみ生成
「もしキーに対応する値がなければ、新しい値を計算して格納する」という処理を一文で書けます。
キャッシュの構築などに最適です。
Map<String, List<String>> groupMap = new HashMap<>();
// "Fruits" というキーがなければ ArrayList を作成し、そこに "Apple" を追加する
groupMap.computeIfAbsent("Fruits", k -> new ArrayList<>()).add("Apple");
groupMap.computeIfAbsent("Fruits", k -> new ArrayList<>()).add("Banana");
System.out.println(groupMap);{Fruits=[Apple, Banana]}merge:値の結合と更新
既存の値と新しい値をどのように組み合わせるかを定義できます。
集計処理に非常に便利です。
Map<String, Integer> wordCount = new HashMap<>();
String text = "apple orange apple banana orange apple";
for (String word : text.split(" ")) {
// キーがなければ 1 をセット、あれば既存の値 (v) に 1 を加算
wordCount.merge(word, 1, (oldValue, newValue) -> oldValue + newValue);
}
System.out.println(wordCount);{banana=1, orange=2, apple=3}putIfAbsent
put と似ていますが、既にキーが存在する場合は上書きしないという動作をします。
Mapのパフォーマンスと使い分けのポイント
大量のデータを扱う場合、Mapの内部構造を知っておくことは重要です。
HashMapの初期容量と負荷係数
HashMap は内部的に「バケット」と呼ばれる配列を持っています。
- 初期容量 (Initial Capacity)
デフォルトは16です。
格納する要素数が分かっている場合は、あらかじめ大きめの値を指定することで、配列の再確保(リサイズ)によるコストを抑えられます。
- 負荷係数 (Load Factor)
デフォルトは0.75です。
要素数が「容量 × 負荷係数」を超えると、容量が拡張されます。
スレッドセーフなMap
マルチスレッド環境でMapを共有する場合、通常の HashMap ではデータの不整合や無限ループが発生する危険があります。
- Collections.synchronizedMap(map)
Map全体をロックします。
安全ですが、競合が多いと低速になります。
- ConcurrentHashMap
Mapを分割してロック(セグメントロックなど)を行うため、高い並行性とパフォーマンスを両立しています。
現代のJava開発ではこちらが推奨されます。
Java 21の最新トピック:SequencedMap
Java 21では、新しいインターフェースである SequencedMap が導入されました。
これにより、順序を持つMap(LinkedHashMapなど)に対する操作が標準化されました。
これまで、Mapの「最後の要素」を取得するのは少し面倒でしたが、SequencedMap により直感的な操作が可能になっています。
// Java 21以降
LinkedHashMap<String, String> map = new LinkedHashMap<>();
map.put("First", "1");
map.put("Second", "2");
// 逆順のビューを取得
Map<String, String> reversed = map.reversed();
// 最初と最後の要素に簡単にアクセス(理論上のイメージ)
// map.firstEntry(), map.lastEntry(), map.pollFirstEntry() などが利用可能これにより、順序が保証されたMapの扱いがより強力かつ一貫性のあるものになりました。
Map使用時の注意点とアンチパターン
Mapは便利ですが、誤った使い方をするとバグやパフォーマンス低下の原因になります。
1. キーにするオブジェクトの不変性
Mapのキーには、不変(Immutable)なオブジェクトを使用してください。
もし、キーとして使用しているオブジェクトの状態が put 後に変化してしまうと、hashCode() の値が変わり、そのオブジェクトをMapから二度と見つけ出せなくなる(迷子になる)可能性があります。
自作クラスをキーにする場合は、必ず equals() と hashCode() を正しくオーバーライドし、フィールドを final にすることを検討してください。
2. ループ内での直接削除
拡張for文でMapを走査している最中に map.remove() を呼び出すと、ConcurrentModificationException がスローされます。
要素を削除したい場合は、Iterator の remove() を使うか、Java 8の removeIf メソッドを使用しましょう。
// 安全な削除方法
scores.entrySet().removeIf(entry -> entry.getValue() < 60);3. 大きすぎるMapによるメモリ圧迫
Mapは要素ごとにエントリーオブジェクトを生成するため、Listなどに比べてメモリ消費量が多くなります。
数百万件単位のデータをMapに詰め込む際は、ヒープメモリの設定や、キー・値のデータ型を見直す(プリミティブ型のコレクションライブラリを検討するなど)必要があります。
まとめ
JavaのMapは、単なるデータの保管場所ではなく、適切な実装クラスとメソッドを選択することで、プログラムのロジックを劇的にシンプルにできる強力なツールです。
- 基本は
HashMap、順序が必要ならLinkedHashMap、ソートが必要ならTreeMapを選ぶ。 - 不変Mapには
Map.of()を活用する。 - Java 8以降の
computeIfAbsentやmergeを使い、条件分岐の少ないコードを目指す。 - キーの不変性とスレッド安全性には常に注意を払う。
- Java 21の
SequencedMapなど、最新の言語仕様もキャッチアップしておく。
これらの知識をバランスよく活用することで、保守性が高くパフォーマンスに優れたJavaアプリケーションを開発できるようになります。
日々のコーディングの中で、今回紹介したメソッドを積極的に取り入れてみてください。