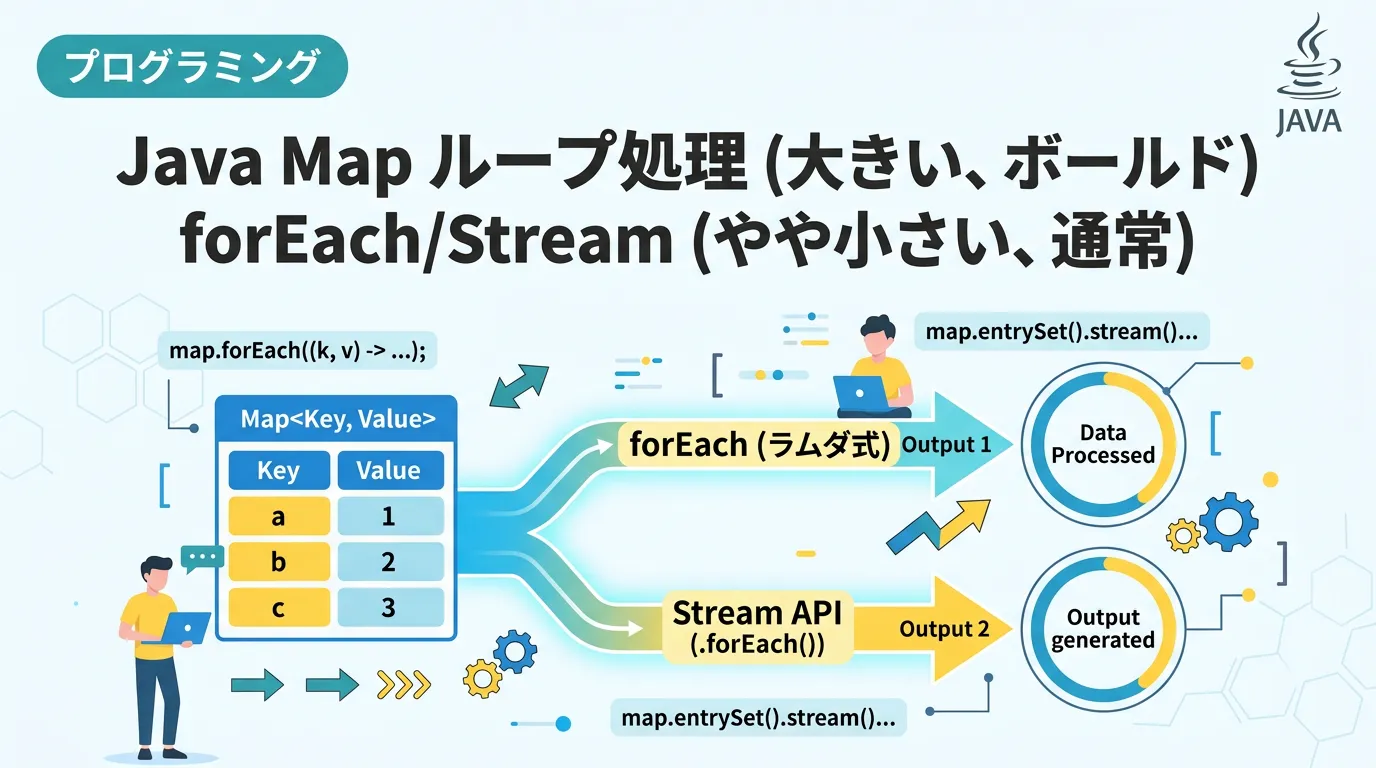
Javaプログラミングにおいて、Mapインターフェースはデータの保持や検索に欠かせない重要なデータ構造です。
キーと値のペアを管理するという特性上、リストなどの単一要素のコレクションとは異なるループ処理の知識が求められます。
特にJava 8以降、ラムダ式やStream APIが登場したことで、記述方法は劇的に進化しました。
かつての拡張for文によるループから、現代的な宣言型プログラミングまで、開発シーンに応じた最適な書き方を選択することは、コードの可読性だけでなくシステムのパフォーマンス向上にも直結します。
本記事では、JavaでMapをループ処理するためのあらゆる手法を網羅し、現場で役立つ実践的なテクニックを詳しく解説します。
JavaにおけるMapループの基本手法
Map自体はIterableインターフェースを直接継承していないため、ListのようにMapそのものを直接拡張for文に渡すことはできません。
そのため、Mapが保持する「エントリー(Entry)」、「キー(Key)」、「値(Value)」のいずれかのビュー(View)を取得してループ処理を行うのが基本となります。
entrySetを使用した効率的なループ
Mapのループ処理において、最も一般的かつ推奨されるのがentrySet()メソッドを使用する方法です。
このメソッドは、キーと値がペアになったMap.Entryオブジェクトのセットを返します。
特徴とメリット
キーと値の両方にアクセスする必要がある場合、entrySet()が最も効率的です。
なぜなら、後述するkeySet()を使用してループ内でget(key)を呼び出す手法に比べ、ハッシュ計算や内部ツリーの探索を二度行う必要がないからです。
import java.util.HashMap;
import java.util.Map;
public class MapLoopEntrySet {
public static void main(String[] args) {
Map<String, Integer> items = new HashMap<>();
items.put("Apple", 100);
items.put("Banana", 200);
items.put("Cherry", 300);
// entrySet()を使用した拡張for文によるループ
for (Map.Entry<String, Integer> entry : items.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("商品名: " + key + ", 価格: " + value);
}
}
}商品名: Apple, 価格: 100
商品名: Banana, 価格: 200
商品名: Cherry, 価格: 300keySetを使用したキーのみのループ
キーの情報だけが必要な場合、またはキーを使用して何らかの外部操作を行う場合は、keySet()を使用します。
注意点
もしキーを使って値も取得したい場合にkeySet()を使うと、ループのたびにmap.get(key)を実行することになり、計算コストが無駄に増大します。
大量のデータを扱う際は、必ずentrySet()を検討してください。
import java.util.HashMap;
import java.util.Map;
public class MapLoopKeySet {
public static void main(String[] args) {
Map<String, String> config = new HashMap<>();
config.put("host", "localhost");
config.put("port", "8080");
// keySet()を使用してキーのみを取得
for (String key : config.keySet()) {
System.out.println("設定項目: " + key);
}
}
}valuesを使用した値のみのループ
キーの情報が一切不要で、格納されているデータ(値)だけを処理したい場合は、values()を使用します。
このメソッドはCollectionを返すため、そのまま拡張for文で利用可能です。
import java.util.HashMap;
import java.util.Map;
public class MapLoopValues {
public static void main(String[] args) {
Map<Integer, String> users = new HashMap<>();
users.put(1, "田中");
users.put(2, "佐藤");
// values()を使用して値のみを処理
for (String name : users.values()) {
System.out.println("ユーザー名: " + name);
}
}
}Java 8以降のforEachメソッドによるモダンな書き方
Java 8で導入されたforEachメソッドは、関数型インターフェース(BiConsumer)を受け取ることで、より簡潔にMapのループを記述できるようにしました。
現代のJava開発においては、このスタイルが主流となっています。
ラムダ式を用いたforEach
Map.forEachを使うと、entrySet()を明示的に呼び出す必要がなく、キーと値を引数として直接受け取ることができます。
import java.util.HashMap;
import java.util.Map;
public class MapForEachLambda {
public static void main(String[] args) {
Map<String, Integer> stock = new HashMap<>();
stock.put("PC", 5);
stock.put("Monitor", 12);
// ラムダ式による簡潔な記述
stock.forEach((key, value) -> {
System.out.println(key + "の在庫数: " + value);
});
}
}この書き方の最大のメリットは、コードのボイラープレート(定型句)が大幅に削減される点にあります。
記述が直感的であり、一時的な変数の宣言も最小限で済みます。
メソッド参照の活用
特定の処理をメソッドとして定義している場合、メソッド参照を用いることでさらに可読性を高めることが可能です。
import java.util.HashMap;
import java.util.Map;
public class MapMethodReference {
public static void main(String[] args) {
Map<String, String> map = Map.of("K1", "V1", "K2", "V2");
// メソッド参照を用いた出力
map.forEach(MapMethodReference::printEntry);
}
private static void printEntry(String k, String v) {
System.out.println("Key: " + k + ", Value: " + v);
}
}Stream APIを活用した高度なループ処理
単に要素を一つずつ処理するだけでなく、フィルタリングや変換(マッピング)を伴うループを行いたい場合は、Stream APIの利用が最適です。
基本的なStreamの利用手順
MapからStreamを生成するには、一度entrySet().stream()を呼び出す必要があります。
import java.util.HashMap;
import java.util.Map;
public class MapStreamBasic {
public static void main(String[] args) {
Map<String, Integer> scores = new HashMap<>();
scores.put("Math", 80);
scores.put("English", 45);
scores.put("Science", 95);
// 60点以上の科目だけを表示する
scores.entrySet().stream()
.filter(entry -> entry.getValue() >= 60)
.forEach(entry -> System.out.println("合格科目: " + entry.getKey()));
}
}変換と新しいMapの生成
ループ処理の結果、元のMapとは異なる形式のMapを作成したり、特定の条件で絞り込んだ結果を保持したりする場合に真価を発揮します。
import java.util.Map;
import java.util.stream.Collectors;
public class MapStreamCollect {
public static void main(String[] args) {
Map<String, Integer> original = Map.of("A", 1, "B", 2, "C", 3);
// 値を10倍にした新しいMapを生成
Map<String, Integer> multiplied = original.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
e -> e.getValue() * 10
));
System.out.println(multiplied);
}
}{A=10, B=20, C=30}Iteratorを使用したループと要素の削除
現代のJavaではIteratorを直接記述する機会は減りましたが、ループ中にMapから要素を削除したい場合は、依然としてIteratorが重要な役割を果たします。
拡張for文やforEachの中でmap.remove()を呼び出すと、ConcurrentModificationExceptionが発生してプログラムが異常終了します。
これを回避するために、安全な削除手段としてIteratorを使用します。
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class MapIteratorRemove {
public static void main(String[] args) {
Map<Integer, String> data = new HashMap<>();
data.put(1, "Data1");
data.put(2, "RemoveMe");
data.put(3, "Data3");
Iterator<Map.Entry<Integer, String>> iterator = data.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
if ("RemoveMe".equals(entry.getValue())) {
// Iteratorのremoveメソッドなら安全に削除可能
iterator.remove();
}
}
System.out.println("削除後のMap: " + data);
}
}Java 8以降の代替手段:removeIf
なお、Java 8以降であれば、Iteratorを明示的に書かなくてもremoveIfメソッドを使用することで、同様の処理をよりシンプルに記述できます。
// 条件に一致する要素を削除する
data.entrySet().removeIf(entry -> "RemoveMe".equals(entry.getValue()));パフォーマンスと使い分けの比較
各ループ手法にはそれぞれ特性があります。
開発者が状況に応じて最適な選択をできるよう、主要な指標を比較表にまとめました。
| 手法 | 可読性 | 効率(速度・メモリ) | 主な用途 |
|---|---|---|---|
| entrySet() (拡張for文) | 普通 | 最高 | 大規模データ、従来のJava環境 |
| keySet() + get() | 普通 | 低い | キーのみ必要な場合(値取得には非推奨) |
| forEach (ラムダ式) | 高い | 良好 | シンプルなループ処理、モダンな記述 |
| Stream API | 非常に高い | 若干のオーバーヘッド有 | フィルタリング、変換、集計処理 |
| Iterator | 低い | 普通 | ループ中の動的な要素削除 |
パフォーマンスに関する考察
極端にパフォーマンスが求められるクリティカルなパス(1秒間に数百万回のループが発生するような箇所)では、entrySet()による拡張for文が最も低コストです。
これはラムダ式やStreamの生成に伴うオブジェクト作成のオーバーヘッドがないためです。
しかし、一般的な業務アプリケーションにおいては、可読性と保守性を優先してforEachやStream APIを選択するのがベストプラクティスと言えます。
よくある間違いとトラブルシューティング
Mapのループ処理を実装する際、初心者が陥りやすいミスや注意点について解説します。
ConcurrentModificationException の回避
前述の通り、拡張for文の中でMap.remove()やMap.put()を行うと、この例外が発生します。
Mapの構造がループ中に変更されることをJavaのランタイムが検知するためです。
これを防ぐには以下のいずれかの方法を取ります。
Iterator.remove()を使用する。removeIf()を使用する。- 削除対象のキーを別途リストに保存しておき、ループ終了後に一括削除する。
ConcurrentHashMapを使用する(スレッドセーフなMapが必要な場合)。
Mapがnullの場合の処理
Mapのインスタンス自体がnullである可能性がある場合、そのままループを回そうとするとNullPointerExceptionが発生します。
// 安全なループの例
if (map != null) {
map.forEach((k, v) -> { /* 処理 */ });
}または、Java 8のOptionalや、Apache Commons等のライブラリを利用して空のMapを保証するパターンも一般的です。
順序性の保証
HashMapを使用している場合、ループで取り出される要素の順序は保証されません。
もし「挿入順」にループを回したい場合はLinkedHashMapを、「キーの自然順序」で回したい場合はTreeMapを使用する必要があります。
ループ処理のロジック自体は同じですが、Mapの実装クラスによって出力結果が変わる点に注意してください。
並列処理による高速化
大規模なMapデータを高速に処理する必要がある場合、Stream APIのparallelStream()を利用することで、マルチコアCPUの性能を最大限に引き出すことができます。
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class MapParallelStream {
public static void main(String[] args) {
Map<Integer, Integer> largeMap = new ConcurrentHashMap<>();
for (int i = 0; i < 1000000; i++) {
largeMap.put(i, i);
}
// 並列処理によるループ
largeMap.entrySet().parallelStream().forEach(entry -> {
// 重い計算処理などを想定
int result = entry.getValue() * 2;
});
}
}ただし、並列ストリームを使用する場合はスレッドセーフな操作を意識しなければなりません。
共有変数への書き込みがある場合は、ConcurrentHashMapの利用や適切な同期化が必要です。
まとめ
JavaでMapをループ処理する方法は多岐にわたりますが、現在の開発基準では以下のように使い分けるのが最適です。
- 基本的には
forEach(ラムダ式) を使用して、簡潔で読みやすいコードを書く。 - 複雑な抽出やデータ変換が必要な場合は
Stream APIを活用する。 - ループ中に要素を削除する必要がある場合は
removeIfまたはIteratorを使用する。 - 非常に高いパフォーマンスが要求される場面では、伝統的な
entrySet()の拡張for文を選択する。
Mapの操作はJavaプログラミングの根幹を成す部分です。
それぞれのメソッドが持つ特性やパフォーマンス上の違いを正しく理解し、プロジェクトの要件やチームのコーディング規約に合わせて、最もメンテナンス性の高い記述方法を選んでいきましょう。
最新のJava機能を使いこなすことで、より洗練された堅牢なアプリケーション開発が可能になります。