Javaを用いたシステム開発において、文字コードの扱いは避けて通れない重要なテーマです。
特に日本語環境では、UTF-8、Shift_JIS、Windows-31J、EUC-JPなど複数の文字コードが混在することがあり、適切な変換処理を行わないと「文字化け」という致命的な不具合を招くことになります。
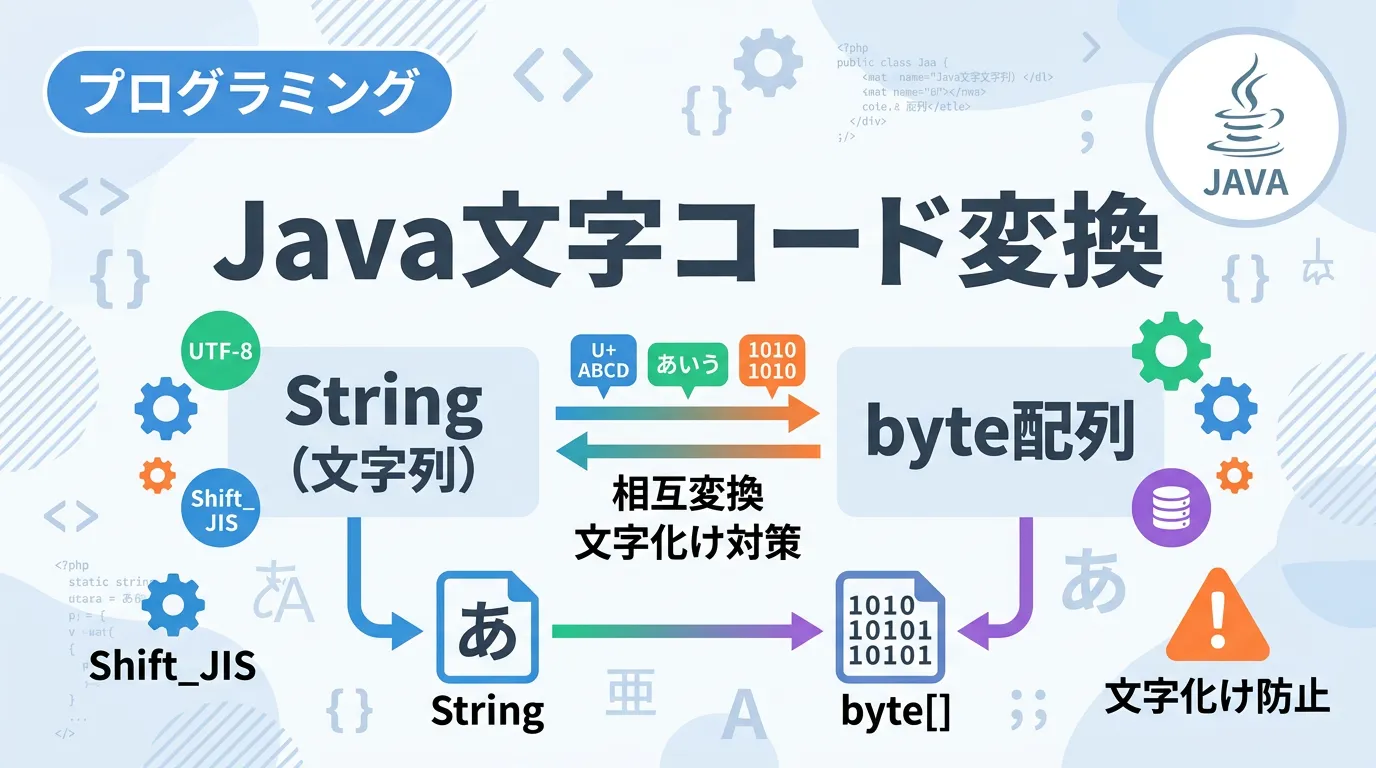
Javaは内部的に文字をUnicode(UTF-16)で保持していますが、ファイル出力やネットワーク通信、データベースへの保存といった外部入出力の際には、特定の文字コード(エンコーディング)への変換が必要になります。
本記事では、Javaにおける文字コード変換の基本原理から、最新の標準的な実装方法、そして文字化けを未然に防ぐためのベストプラクティスまでを詳しく解説します。
Javaにおける文字の内部表現とエンコーディングの仕組み
Javaで文字コード変換を正しく実装するためには、まずJavaがどのように文字を管理しているかを理解する必要があります。
Javaの型である char や String は、内部的には Unicode(UTF-16) を採用しています。
プログラム内で扱う文字列そのものは、どのOSや環境であってもUTF-16として保持されますが、これを「バイトデータ」として外部に出力したり、外部から読み込んだりする際に、特定の文字コードへの「符号化(エンコード)」や「復号(デコード)」が発生します。
文字列(String)とバイト配列(byte[])の関係
Javaにおける文字コード変換の実体は、「Stringオブジェクト」と「byte配列」の間の相互変換です。
- エンコード(符号化):
String(UTF-16)を、特定の文字コード(UTF-8など)のbyte[]に変換すること。 - デコード(復号): 外部から取り込んだ
byte[]を、特定の文字コードとして解釈し、Java内部のString(UTF-16)に変換すること。
この変換プロセスにおいて、変換元と変換先で指定する文字コードが一致していない場合に、文字化けが発生します。
Stringとbyte配列の相互変換:基本の実装方法
Javaで最も頻繁に使用される文字コード変換の手法は、String クラスのメソッドを利用する方法です。
getBytesメソッドによるエンコード
String をバイト配列に変換するには、getBytes() メソッドを使用します。
引数なしの getBytes() も存在しますが、これは 実行環境のデフォルト文字コードに依存するため、使用は推奨されません。
必ず文字コード(Charset)を明示的に指定するようにしましょう。
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
public class EncodingExample {
public static void main(String[] args) {
String originalText = "こんにちは、Java";
// UTF-8でエンコード(バイト配列に変換)
byte[] utf8Bytes = originalText.getBytes(StandardCharsets.UTF_8);
// Windows-31J(Shift_JIS拡張)でエンコード
// StandardCharsetsにないものは、Charset.forNameで指定
byte[] sjisBytes = originalText.getBytes(java.nio.charset.Charset.forName("Windows-31J"));
System.out.println("UTF-8バイト列: " + Arrays.toString(utf8Bytes));
System.out.println("Windows-31Jバイト列: " + Arrays.toString(sjisBytes));
}
}UTF-8バイト列: [-29, -127, -126, -29, -127, -114, -29, -127, -101, -29, -127, -107, -29, -127, -93, -17, -68, -116, 74, 97, 118, 97]
Windows-31Jバイト列: [-126, -91, -126, -78, -126, -65, -126, -71, -126, -57, -125, 65, 74, 97, 118, 97]Stringコンストラクタによるデコード
バイト配列を文字列に戻す場合は、String クラスのコンストラクタを使用します。
ここでも、バイト配列がどの文字コードで作成されたものかを正しく指定する必要があります。
import java.nio.charset.StandardCharsets;
public class DecodingExample {
public static void main(String[] args) {
// UTF-8形式のバイト配列(「Java」という文字列)
byte[] data = {74, 97, 118, 97};
// バイト配列をUTF-8として文字列に変換
String decodedText = new String(data, StandardCharsets.UTF_8);
System.out.println("復元された文字列: " + decodedText);
}
}復元された文字列: JavaCharsetクラスとStandardCharsetsの活用
文字コードを指定する際、以前のJava(Java 6以前)では文字列(”UTF-8″ など)で指定することが一般的でしたが、現在は java.nio.charset.Charset オブジェクトを使用することが推奨されています。
StandardCharsetsを使用するメリット
java.nio.charset.StandardCharsets クラスには、主要な文字コードの定数が定義されています。
これを利用することで、以下のメリットが得られます。
- タイポ(打ち間違い)の防止
UTF8やUTF-8といった文字列指定でのミスを防げます。- 例外処理の簡略化
文字列指定の場合、
UnsupportedEncodingExceptionのキャッチが必要になりますが、StandardCharsetsを使用すれば、コンパイル時に存在が保証されるためチェック例外の処理が不要です。
| 定数名 | 文字コードの説明 |
|---|---|
StandardCharsets.UTF_8 | 最も一般的な多言語対応文字コード |
StandardCharsets.UTF_16 | Java内部でも使われる16ビットUnicode |
StandardCharsets.US_ASCII | 7ビットASCII文字 |
StandardCharsets.ISO_8859_1 | 西欧言語用文字コード |
日本語固有の文字コード指定
StandardCharsets には、残念ながら Shift_JIS や EUC-JP は含まれていません。
これらを使用する場合は、Charset.forName("MS932") や Charset.forName("Shift_JIS") のように指定します。
特に Windows 環境で作成されたファイルを扱う場合は、純粋な “Shift_JIS” ではなく、Microsoft拡張が含まれた “Windows-31J”(別名: MS932)を使用するのが一般的です。
ファイルI/Oにおける文字コード変換
実務で最も多いのは、ファイルから文字列を読み込んだり、ファイルに書き出したりする際の変換処理です。
Java 8以降およびJava 11以降で導入された java.nio.file.Files クラスを使うと、非常に簡潔に記述できます。
ファイルの読み込み(Files.readAllLines)
ファイルを一行ずつ読み込み、リストとして取得する例です。
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.io.IOException;
public class FileReadExample {
public static void main(String[] args) {
var path = Paths.get("example.txt");
try {
// 文字コードを指定して読み込み
List<String> lines = Files.readAllLines(path, StandardCharsets.UTF_8);
lines.forEach(System.out::println);
} catch (IOException e) {
e.printStackTrace();
}
}
}ファイルの書き出し(Files.writeString)
Java 11以降では、Files.writeString を使うことで、文字列を直接ファイルに出力できます。
import java.nio.file.Files;
import java.nio.file.Paths;
import java.nio.charset.StandardCharsets;
import java.io.IOException;
public class FileWriteExample {
public static void main(String[] args) {
var path = Paths.get("output.txt");
String content = "Javaでのファイル出力テスト";
try {
// 文字コードを指定して書き込み
Files.writeString(path, content, StandardCharsets.UTF_8);
System.out.println("ファイルの書き出しが完了しました。");
} catch (IOException e) {
e.printStackTrace();
}
}
}文字化けを防ぐための重要ポイント
システム開発において文字化けが発生する原因は、「データの実際の文字コード」と「プログラムが解釈しようとする文字コード」の不一致に集約されます。
これを防ぐための具体的なポイントを解説します。
1. デフォルト文字コードに依存しない
Javaの古いAPIや特定のメソッドは、引数に文字コードを与えない場合、システム・プロパティ file.encoding に設定された「プラットフォームのデフォルト文字コード」を使用します。
Windowsであれば通常は MS932、Linuxであれば UTF-8 となることが多く、開発環境(Windows)で動いていたプログラムが本番環境(Linux)で文字化けするというトラブルの最大の原因です。
必ず明示的に Charset を指定する習慣をつけましょう。
2. Shift_JISとWindows-31J(MS932)の違いを理解する
日本語環境で非常に多いトラブルが、これら2つの混同です。
- Shift_JIS
JIS規格に基づいた基本の文字コード。
- Windows-31J (MS932)
MicrosoftがShift_JISを拡張したもの。
丸数字(①②③)や「はしご高」などの機種依存文字が含まれます。
Javaで Shift_JIS と指定すると、JIS規格に厳密に従うため、Windows固有の文字が化けることがあります。
Windowsユーザーが作成したデータを扱う場合は、Charset.forName("Windows-31J") を使用するのが安全です。
3. Unicodeサロゲートペアへの対応
UTF-16では、一部の特殊な漢字や絵文字を1つの char(16ビット)で表現できず、2つの char を組み合わせて表現します。
これを サロゲートペア と呼びます。
文字数をカウントする際に String.length() を使うと、サロゲートペアを「2文字」と数えてしまうため、正確な文字数を取得するには codePointCount を使用する必要があります。
public class SurrogateExample {
public static void main(String[] args) {
String emoji = "𩸽"; // ほっけ(サロゲートペア文字)
System.out.println("length(): " + emoji.length()); // 2が返る
System.out.println("codePointCount: " + emoji.codePointCount(0, emoji.length())); // 1が返る
}
}高度な文字コード変換:CharsetEncoderとCharsetDecoder
より複雑な要件、例えば「変換できない文字が含まれていた場合にエラーにする」あるいは「別の文字に置換する」といった細かい制御が必要な場合は、CharsetEncoder および CharsetDecoder クラスを使用します。
変換エラーのハンドリング
デフォルトの String.getBytes() では、変換できない文字は「?」に置換されてしまいますが、以下の実装では変換不能な文字を検知して例外を投げることができます。
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.charset.Charset;
import java.nio.charset.CharsetEncoder;
import java.nio.charset.CodingErrorAction;
public class AdvancedEncoding {
public static void main(String[] args) throws Exception {
Charset encoderCharset = Charset.forName("Shift_JIS");
CharsetEncoder encoder = encoderCharset.newEncoder();
// 変換できない文字があった場合にエラーを報告する設定
encoder.onUnmappableCharacter(CodingErrorAction.REPORT);
String input = "この文字はShift_JISで表現できません:㊙";
try {
ByteBuffer output = encoder.encode(CharBuffer.wrap(input));
System.out.println("変換に成功しました。");
} catch (java.nio.charset.UnmappableCharacterException e) {
System.err.println("変換できない文字が含まれています。");
}
}
}このように、onUnmappableCharacter や onMalformedInput を設定することで、データ整合性を厳格に保つことが可能になります。
Webアプリケーションにおける文字コード
Java ServletやSpring Bootなどを用いたWebアプリケーションでは、HTTPリクエストおよびレスポンスの文字コード設定も重要です。
リクエスト・レスポンスの指定
最近のフレームワークではデフォルトでUTF-8が適用されていますが、古いシステムとの連携ではフィルターなどで明示的に指定する必要があります。
// Servletでの例
request.setCharacterEncoding("UTF-8");
response.setContentType("text/html; charset=UTF-8");また、データベース接続時も接続文字列(JDBC URL)に文字コードを指定することが一般的です。
jdbc:mysql://localhost:3306/mydb?useUnicode=true&characterEncoding=UTF-8
文字コード変換のベストプラクティス・チェックリスト
開発時に意識すべきポイントをまとめました。
- システムの入り口と出口で変換する
Java内部では常に
String(UTF-16)として扱い、外部への出力時や外部からの入力時のみ変換を行います。- UTF-8を標準にする
新規システムであれば、特別な理由がない限り全ての層(Java, DB, ファイル, フロントエンド)でUTF-8を採用します。
- 定数クラスを活用する
StandardCharsetsを優先的に使い、マジックストリング(直書きの文字列)を排除します。- ログ出力の確認
ログファイル自体の文字コードも統一されているか確認します。
- BOM(Byte Order Mark)の有無
UTF-8ファイルにはBOM付きとBOMなしがあります。
Windowsのメモ帳などで作成されたBOM付きファイルを読み込む際は、先頭の不可視文字によるエラーに注意が必要です。
まとめ
Javaにおける文字コード変換は、単なるメソッドの呼び出し以上の深い理解を必要とします。
Java内部が UTF-16 であることを前提に、byte[] との相互変換をいかに正確に行うかが鍵となります。
現代のJava開発においては、StandardCharsets や java.nio.file.Files クラスといった便利なAPIが揃っており、これらを正しく使用することで、多くの文字化けトラブルを未然に防ぐことができます。
また、日本語特有の事情(Windows-31Jの存在やサロゲートペア)を把握しておくことは、堅牢なシステムを構築するテクニカルライターやエンジニアにとって必須の知識と言えるでしょう。
常に「現在の文字コードは何か?」を意識し、暗黙のデフォルト設定を排除したコードを書くことが、保守性の高い高品質なプログラムへの第一歩です。