Javaにおける正規表現は、文字列のバリデーション(妥当性確認)、特定のパターンの抽出、置換、分割など、多岐にわたるテキスト処理を効率化するための強力なツールです。
標準ライブラリとして提供されている「java.util.regex」パッケージを活用することで、複雑な文字列操作を簡潔なコードで実装できるようになります。
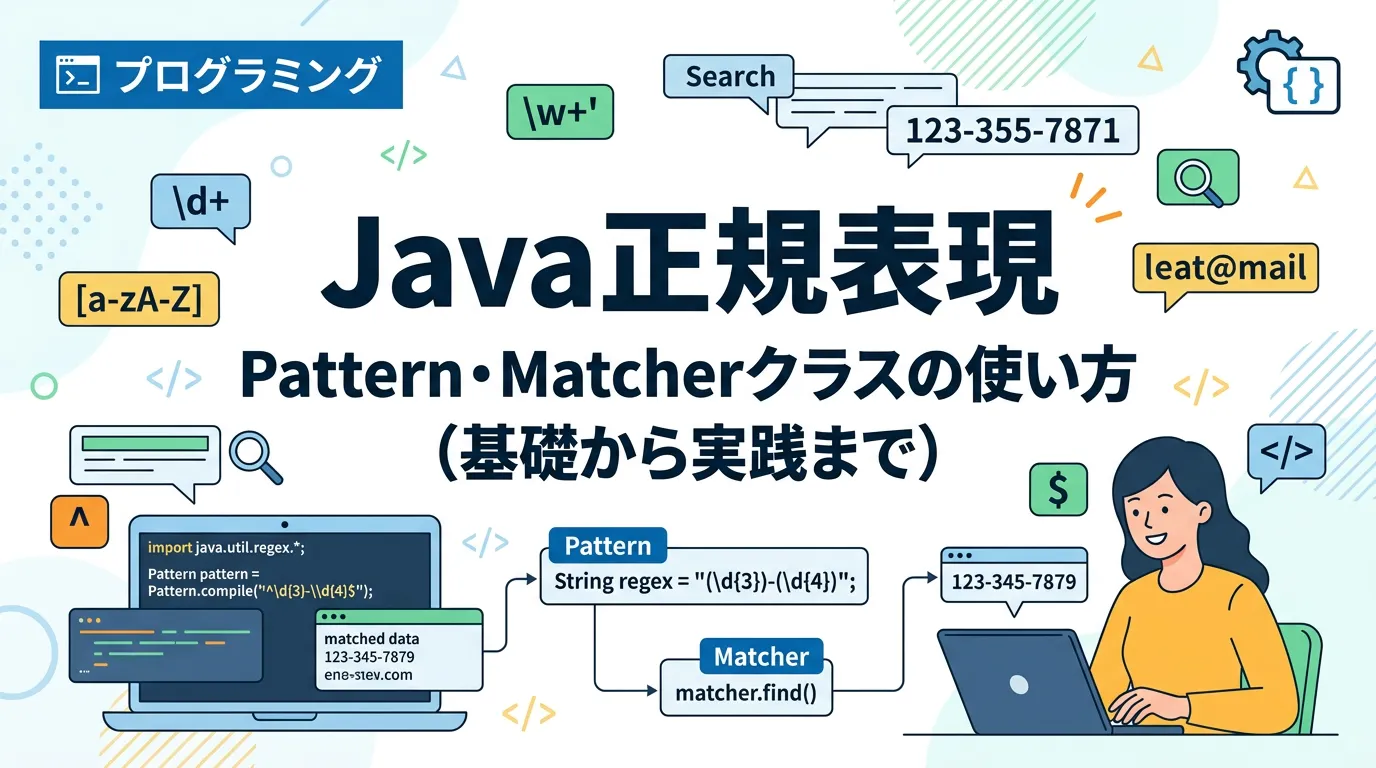
本記事では、Javaで正規表現を扱うための基本クラスであるPatternクラスとMatcherクラスの使い方を中心に、実務で役立つ具体的なサンプルコードやパフォーマンス、セキュリティ上の注意点までを詳しく解説します。
Java正規表現の基礎知識
Javaで正規表現を利用する場合、主にjava.util.regexパッケージに含まれるクラスを使用します。
このパッケージには、正規表現のパターンを定義するPatternクラスと、そのパターンを実際の文字列に対して照合するMatcherクラスが含まれています。
正規表現とは何か
正規表現(Regular Expression)とは、特定の文字の並びを表現するための「パターン記法」です。
例えば、「数字3桁-数字4桁」というパターンを定義すれば、電話番号や郵便番号などの形式を簡単にチェックできます。
Javaの正規表現は、Perl 5に近い構文を採用しており、非常に柔軟で強力な記述が可能です。
java.util.regexパッケージの役割
Javaで正規表現を扱うための中心的な役割を果たすのは、以下の3つのコンポーネントです。
- Patternクラス
正規表現パターンのコンパイル済み表現です。
文字列として定義された正規表現を、Javaが実行可能な内部形式に変換します。
- Matcherクラス
Patternを使用して、入力文字列に対してマッチング操作を行うエンジンです。- PatternSyntaxException
正規表現の構文に誤りがある場合にスローされる非チェック例外です。
また、Stringクラス自体にもmatchesやreplaceAllといった正規表現を簡易的に利用できるメソッドが備わっていますが、内部的にはこれらもPatternクラスを利用しています。
PatternクラスとMatcherクラスの基本操作
Javaで正規表現を利用する最も標準的な手順は、「パターンのコンパイル」と「マッチングの実行」の2ステップに分かれます。
1. Patternオブジェクトの作成
正規表現の文字列をPattern.compile()メソッドに渡して、Patternインスタンスを生成します。
正規表現のコンパイルは計算負荷が高いため、同じパターンを繰り返し使用する場合は、インスタンスを再利用することが推奨されます。
import java.util.regex.Pattern;
// 正規表現パターンのコンパイル
Pattern pattern = Pattern.compile("^[0-9]+$");2. Matcherオブジェクトの作成
作成したPatternオブジェクトのmatcher()メソッドを呼び出し、検査対象の文字列を渡すことで、Matcherオブジェクトを取得します。
import java.util.regex.Matcher;
String target = "12345";
Matcher matcher = pattern.matcher(target);3. マッチング結果の確認
Matcherクラスには、マッチングの方法に応じていくつかのメソッドが用意されています。
matches():文字列全体がパターンに一致するかを判定します。find():文字列の中にパターンに一致する部分があるかを探します。lookingAt():文字列の先頭部分がパターンに一致するかを判定します。
if (matcher.matches()) {
System.out.println("全体が一致しました");
}Java正規表現の構文ルール
Javaの正規表現で使用される主なメタ文字と、Java特有の記述ルールについて解説します。
基本的なメタ文字一覧
正規表現では、特定の意味を持つ「メタ文字」を使用してパターンを構築します。
| メタ文字 | 説明 | 例 |
|---|---|---|
. | 任意の1文字(改行を除く) | a.c は “abc”, “axc” などに一致 |
^ | 行の先頭 | ^Java は行頭の “Java” に一致 |
$ | 行の末尾 | end$ は行末の “end” に一致 |
* | 直前の文字の0回以上の繰り返し | ab* は “a”, “ab”, “abbb” に一致 |
+ | 直前の文字の1回以上の繰り返し | ab+ は “ab”, “abbb” に一致 |
? | 直前の文字が0回または1回出現 | ab? は “a”, “ab” に一致 |
\d | 数字 [0-9] | \d{3} は “123” などに一致 |
\w | 単語構成文字 [a-zA-Z_0-9] | \w+ は英数字に一致 |
\s | 空白文字(スペース、タブなど) | \s+ |
Javaにおけるバックスラッシュの扱い
Javaのソースコード内で正規表現を記述する際、最も注意すべき点がバックスラッシュ(エスケープ文字)の扱いです。
Javaの文字列リテラルにおいて、バックスラッシュ自体がエスケープ文字として機能するため、正規表現のメタ文字としてのバックスラッシュを表現するには、「\\」と2回重ねて記述する必要があります。
例えば、数字を意味する \d をJavaで記述する場合は、"\d" となります。
また、正規表現でドット . 自体を文字として検索したい場合は、"\." と記述します。
文字クラスと範囲指定
文字クラスを使用すると、特定の文字集合のいずれかに一致させることができます。
[abc]:「a」または「b」または「c」のいずれか。[^abc]:「a」「b」「c」以外の任意の文字。[a-z]:小文字の「a」から「z」まで。[a-zA-Z]:英字全般。
実践的なマッチングと抽出のサンプルコード
ここでは、実際に動作するJavaプログラムを用いて、文字列の判定と部分抽出の方法を解説します。
文字列のバリデーション(matchesメソッド)
ユーザーが入力した文字列が特定の形式(例:郵便番号)を守っているかを確認する例です。
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class RegexValidationSample {
public static void main(String[] args) {
// 日本の郵便番号形式 (3桁-4桁)
String regex = "^\\d{3}-\\d{4}$";
String input = "123-4567";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
if (matcher.matches()) {
System.out.println("正しい郵便番号形式です。");
} else {
System.out.println("形式が正しくありません。");
}
}
}正しい郵便番号形式です。部分一致の検索と抽出(find, groupメソッド)
長いテキストの中から、特定のパターンに一致する箇所をすべて抜き出す処理です。
丸括弧 () を使用した「キャプチャグループ」を利用することで、一致した部分の一部だけを取り出すことも可能です。
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class RegexExtractionSample {
public static void main(String[] args) {
String text = "価格は、商品Aが1500円、商品Bが2300円、商品Cが800円です。";
// 「商品[名前]が[数値]円」というパターンから名前と数値を抽出
String regex = "商品([A-Z])が(\\d+)円";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
System.out.println("抽出結果:");
while (matcher.find()) {
// group(0) は一致した全体、group(1) 以降が各括弧に対応
String itemName = matcher.group(1);
String price = matcher.group(2);
System.out.println("商品名: " + itemName + ", 価格: " + price);
}
}
}抽出結果:
商品名: A, 価格: 1500
商品名: B, 価格: 2300
商品名: C, 価格: 800matcher.find() は、次の一致箇所が見つかるたびに true を返し、内部のポインタを移動させます。
これを while ループで回すことで、テキスト内の全ヒット箇所を処理できます。
置換と分割のテクニック
正規表現は検索だけでなく、文字列の変換(置換)や特定の区切り文字での分割にも力を発揮します。
文字列の置換(replaceAll)
Matcher.replaceAll() を使用すると、パターンに一致したすべての箇所を指定した文字列に置換できます。
import java.util.regex.Pattern;
import java.util.regex.Matcher;
public class RegexReplaceSample {
public static void main(String[] args) {
String input = "2024/01/01 2024-05-10 2024.12.31";
// 区切り文字「/」「-」「.」をすべて「年」「月」「日」形式に変換する(簡易的な例)
// $1, $2, $3 は後方参照と呼ばれ、キャプチャグループの内容を置換後の文字列で利用できます
String regex = "(\\d{4})[/\\-\\.](\\d{2})[/\\-\\.](\\d{2})";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(input);
String result = matcher.replaceAll("$1年$2月$3日");
System.out.println("変換後: " + result);
}
}変換後: 2024年01月01日 2024年05月10日 2024年12月31日文字列の分割(split)
Pattern.split() を使うと、正規表現を区切り文字として文字列を分割し、配列として取得できます。
import java.util.regex.Pattern;
public class RegexSplitSample {
public static void main(String[] args) {
String csvData = "apple, orange , banana,grape";
// カンマとその前後の任意の空白を区切り文字とする
Pattern pattern = Pattern.compile("\\s*,\\s*");
String[] fruits = pattern.split(csvData);
for (String fruit : fruits) {
System.out.println("フルーツ: [" + fruit + "]");
}
}
}フルーツ: [apple]
フルーツ: [orange]
フルーツ: [banana]
フルーツ: [grape]高度な正規表現の機能
Javaの正規表現エンジンには、より高度な制御を行うための機能が備わっています。
マッチングフラグの使用
Pattern.compile() の第2引数にフラグを指定することで、マッチングの挙動を変更できます。
Pattern.CASE_INSENSITIVE:大文字と小文字を区別しない。Pattern.MULTILINE:^と$が行の先頭と末尾に一致するようになる。Pattern.DOTALL:ドット.が改行文字にも一致するようになる。
Pattern pattern = Pattern.compile("java", Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher("JAVA");
System.out.println(matcher.matches()); // true先読みと後読み(境界の制御)
「特定の文字が続く(あるいは続かない)場合のみマッチさせる」という高度な条件を指定できます。
- 肯定先読み
(?=pattern):後に pattern が続く場合のみ一致。 - 否定先読み
(?!pattern):後に pattern が続かない場合のみ一致。
これらは「一致はさせるが、一致した文字列自体はマッチ結果(group)には含めない」という特性があります。
パフォーマンスとメモリの最適化
大規模なシステムや高頻度で呼び出される処理において、正規表現の扱いはパフォーマンスに直結します。
Patternオブジェクトの事前コンパイル
冒頭でも触れましたが、String.matches() をループ内で使用するのは避けるべきです。
なぜなら、String.matches() は内部で呼び出されるたびに Pattern.compile() を実行し、使い捨てているからです。
大量のデータを処理する場合は、以下のように static なフィールドとして一度だけコンパイルしておくのが定石です。
public class PerformanceOptimization {
// クラスロード時に一度だけコンパイルされる
private static final Pattern EMAIL_PATTERN =
Pattern.compile("^[a-zA-Z0-9+_.-]+@[a-zA-Z0-9.-]+$");
public boolean isValidEmail(String email) {
return EMAIL_PATTERN.matcher(email).matches();
}
}非キャプチャグループの活用
括弧 () を使用すると、デフォルトではマッチした内容がメモリに保持され、後で group() メソッドで取得できるようになります。
しかし、単に「AまたはB」というグループ化のために括弧を使いたいだけで、抽出の必要がない場合は、(?:pattern) という記法(非キャプチャグループ)を使うことで、メモリ消費と処理時間をわずかに削減できます。
セキュリティ上の考慮事項(ReDoS対策)
正規表現には「正規表現サービス拒否攻撃(ReDoS: Regular Expression Denial of Service)」と呼ばれる脆弱性が存在します。
ReDoSとは
複雑で効率の悪い正規表現(特に、入れ子になった繰り返し構文など)に対して、意図的にマッチしにくい長い文字列を入力することで、CPU使用率を100%に高騰させ、システムを停止させる攻撃です。
対策方法
- 複雑な繰り返しの回避
(a+)+のような入れ子の繰り返しを避ける。- 独占的量子化子(Possessive Quantifiers)の使用
*+や++を使用して、バックトラック(戻り試行)を抑制する。- タイムアウトの実装
Java標準の
Matcherにはタイムアウト機能がないため、必要に応じて処理時間を監視するラッパーを作成する。- 入力値の長さ制限
チェックを行う前に、入力文字列の最大長を制限する。
まとめ
Javaの正規表現は、PatternクラスとMatcherクラスを使いこなすことで、高度な文字列操作を実現します。
本記事で解説したポイントを振り返ります。
- Javaではバックスラッシュを「\\」と2回書く必要がある。
- 繰り返し使用するパターンは
static finalなPatternオブジェクトとして事前コンパイルする。 matches()は全体一致、find()は部分一致を判定する。- キャプチャグループ
()を使うことで、特定の部分文字列を抽出できる。 - ReDoS(脆弱性)を避けるために、効率的で安全なパターン設計を心がける。
正規表現は、一度習得すればJava以外の言語でも応用が効く汎用的なスキルです。
最初はメタ文字の多さに戸惑うかもしれませんが、簡単なバリデーションから少しずつ実践に取り入れ、複雑なテキスト処理をスマートに解決できるようになりましょう。