C言語を学び始めると、避けて通れないのが「文字列」の扱いです。
他のプログラミング言語では文字列が基本データ型として用意されていることが多いですが、C言語において文字列は「文字の配列」として扱われます。
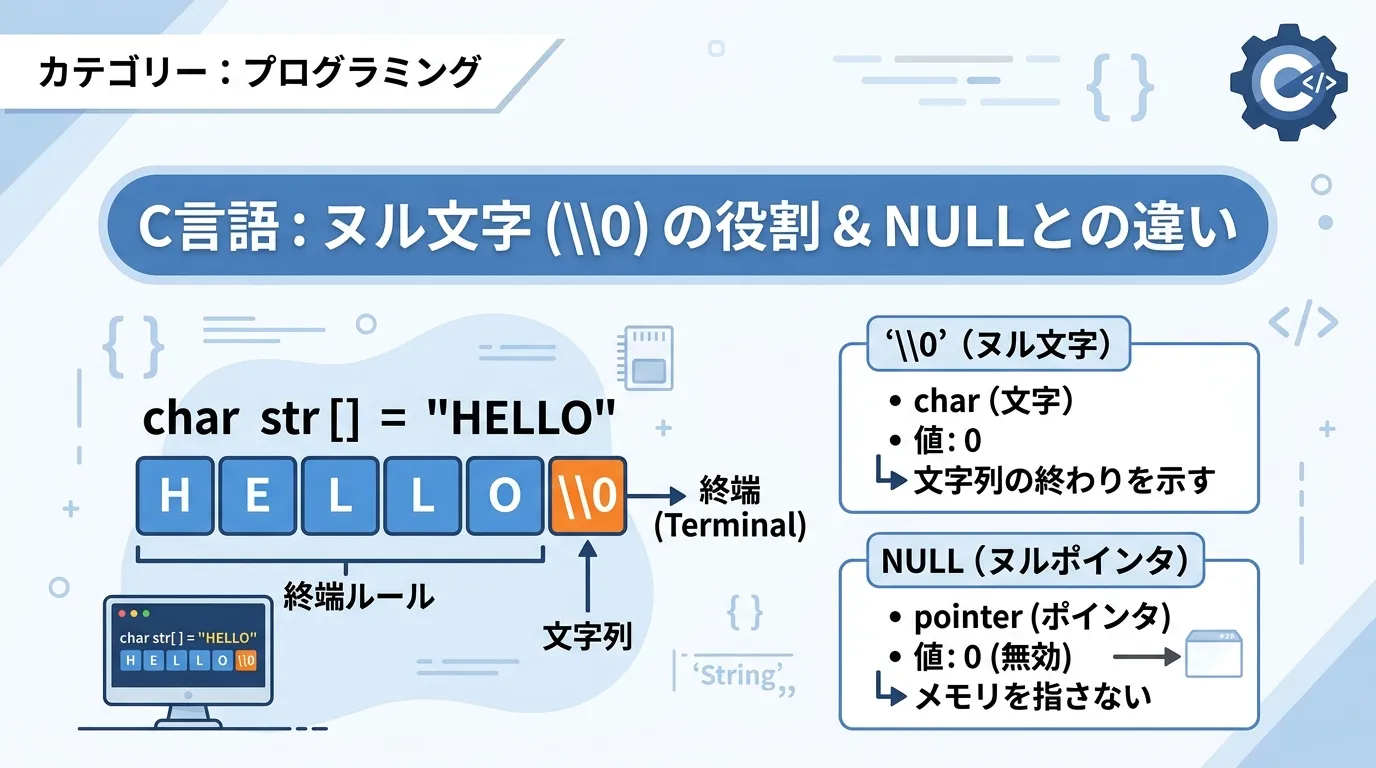
この文字配列を文字列として成立させるための鍵を握っているのがヌル文字(\0)です。
ヌル文字の役割を正しく理解することは、メモリ管理やバグのないプログラム作成において極めて重要です。
本記事では、ヌル文字の定義から、混同しやすいNULLとの違い、そして実務で役立つ注意点まで、テクニカルな視点で詳しく解説します。
C言語のヌル文字とは?基本的な定義と役割
C言語における文字列は、文字型の配列の末尾に特別な文字を置くことで、どこまでが文字列であるかを判断する仕組みを採用しています。
この末尾に置かれる特別な文字こそがヌル文字です。
ヌル文字の正体とエスケープシーケンス
ヌル文字は、ソースコード上では'\0'というエスケープシーケンスで表現されます。
内部的な実体は、ASCIIコード(あるいは他の文字コード体系)における数値の0です。
コンピュータにとって、メモリ上のデータは単なる数値の羅列に過ぎません。
例えば、メモリに 72, 105 という数値が並んでいたとき、それが「Hi」という文字列なのか、あるいは他の数値データなのかを判別する手段が必要です。
C言語では、データの末尾に 0 を置くことで、「ここで文字列が終了する」という合図(センチネル値)として機能させています。
文字列リテラルと自動付与
C言語でダブルクォーテーションを使用した文字列リテラル(例:"Hello")を記述すると、コンパイラは自動的にその末尾にヌル文字を付加します。
#include <stdio.h>
int main(void) {
// 文字列リテラルを定義
char str[] = "Hello";
// 各要素を表示してみる
for (int i = 0; i <= 5; i++) {
printf("str[%d] の値: %d (文字: '%c')\n", i, str[i], str[i]);
}
return 0;
}str[0] の値: 72 (文字: 'H')
str[1] の値: 101 (文字: 'e')
str[2] の値: 108 (文字: 'l')
str[3] の値: 108 (文字: 'l')
str[4] の benevolence: 111 (文字: 'o')
str[5] の値: 0 (文字: '')上記のコードから分かる通り、"Hello" という5文字の文字列を格納するために、配列 str は6バイトの領域を占有しています。
最後の str[5] には数値の 0 が自動的に入っており、これがヌル文字です。
文字列の終端ルールとメモリ構造
C言語の標準ライブラリ(string.h など)に含まれる関数の多くは、このヌル文字を基準に動作します。
ここでは、ヌル文字がどのようにメモリ上で機能しているのか、その構造を深掘りします。
なぜ終端文字が必要なのか
多くのモダンなプログラミング言語では、文字列オブジェクトが「文字列の長さ」という情報をプロパティとして持っています。
しかし、C言語の文字配列自体は、自分の長さが何バイトであるかという情報を保持していません。
もしヌル文字が存在しなければ、printf 関数などは配列の範囲を超えてメモリを読み続け、不正なメモリ参照(セグメンテーションフォールト)を起こすか、ゴミデータを表示し続けてしまいます。
ヌル文字があるおかげで、プログラムは「0に出会うまで読み進める」というシンプルなルールで文字列を処理できるのです。
メモリ上での配置イメージ
例えば、char data[8] = "CAT"; と宣言した場合、メモリ内は以下のようになります。
| インデックス | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 格納データ | ‘C’ | ‘A’ | ‘T’ | ‘\0’ | ? | ? | ? | ? |
| 数値表現 | 67 | 65 | 84 | 0 | 不定 | 不定 | 不定 | 不定 |
ここで重要なのは、配列のサイズが8であっても、文字列としての長さは「ヌル文字の直前まで」の3文字として扱われる点です。
インデックス4以降に何が入っていようと、文字列操作関数はインデックス3のヌル文字を見た瞬間に処理を終了します。
ヌル文字(\0)とNULLポインタの違い
C言語学習者が最も混乱しやすいのが、'\0' と NULL の違いです。
どちらも「ヌル」という言葉を含み、内部的な値も 0 であることが多いですが、言語仕様上の意味と用途は全く異なります。
型の違い
まず、根本的な「型」の違いを理解しましょう。
- ヌル文字(\0)
型:
char(文字型、整数として扱われる)用途:文字列の終端を示すデータ。
値:整数定数の
0。- NULL
型:
void *(ポインタ型)用途:ポインタが「どこも指していない」ことを示す値。
定義:マクロとして
(void *)0などと定義されている。
比較表による整理
| 特徴 | ヌル文字 (\0) | NULLポインタ |
|---|---|---|
| 表記 | '\0' | NULL |
| データ型 | char / int | void * (ポインタ) |
| 意味 | 文字列の終わり | 有効なアドレスがない |
| 使用例 | str[i] == '\0' | if (ptr == NULL) |
| サイズ | 通常 1バイト | ポインタサイズ(4 or 8バイト) |
誤用の例
以下のようなコードは、コンパイルは通るかもしれませんが、論理的には不適切です。
char *ptr = get_string();
if (ptr == '\0') { /* 不適切:ポインタと文字を比較している */ }
char str[] = "Hello";
str[5] = NULL; /* 不適切:文字配列の要素にポインタを代入している */最近のコンパイラでは警告(Warning)が出ることもあります。
セマンティクス(意味論)を正しく守り、文字には '\0'、ポインタには NULL を使うのがプロの書き方です。
ヌル文字に関連するプログラミングの実践例
実際にヌル文字を意識してプログラムを書く際の例を見てみましょう。
ここでは、標準ライブラリの strlen 関数と同等の機能を自作することで、ヌル文字の挙動を確認します。
自作の文字列長取得関数
文字列の長さをカウントするには、先頭から1文字ずつ読み進め、ヌル文字が出現したところでループを終了します。
#include <stdio.h>
// 文字列の長さを返す関数(ヌル文字自体は数えない)
size_t my_strlen(const char *s) {
size_t length = 0;
// ポインタの指す先がヌル文字でない間、カウントを増やす
while (s[length] != '\0') {
length++;
}
return length;
}
int main(void) {
char text[] = "C-Language";
printf("文字列: %s\n", text);
printf("長さ: %zu\n", my_strlen(text));
return 0;
}文字列: C-Language
長さ: 10このコードでは、s[length] != '\0' という条件式が重要な役割を果たしています。
ヌル文字を検知することで、配列の範囲を安全に走査できていることが分かります。
文字列の結合とヌル文字
文字列を結合する場合、結合先の末尾にあるヌル文字を上書きし、新しい文字列を追加した後に再度ヌル文字を付与する必要があります。
標準関数の strcat はこの処理を自動で行いますが、手動で行う場合は注意が必要です。
ヌル文字を扱う際の注意点とバグの回避策
ヌル文字の扱いを誤ると、プログラムは深刻な脆弱性やバグを抱えることになります。
特に注意すべきポイントを3つ挙げます。
1. 配列サイズの確保不足(プラス1の法則)
最も多いミスは、文字列の長さと同じサイズの配列を確保してしまうことです。
「Hello」は5文字ですが、これを格納するには「5 + 1(ヌル文字分) = 6バイト」の領域が必要です。
// 誤り:ヌル文字の場所がない
char buf[5] = "Hello";
// 正解
char buf[6] = "Hello";もしサイズが不足していると、隣接するメモリ領域を破壊するバッファオーバーランの原因となります。
2. ヌル終端の欠落
文字配列を1文字ずつ代入して作成する場合、最後に明示的にヌル文字を入れ忘れることがあります。
char str[3];
str[0] = 'A';
str[1] = 'B';
// str[2] に '\0' を入れ忘れると、文字列として破綻する
printf("%s\n", str); // どこまでもメモリを読み続けてしまうこのように、文字列を構築した後は必ず最後に '\0' を代入する癖をつけましょう。
3. バッファオーバーラン攻撃の標的
C言語のヌル終端文字列(C-Style String)は、歴史的にセキュリティ上の弱点となってきました。
攻撃者が意図的にヌル文字のない巨大なデータを送り込むことで、プログラムのスタック領域を上書きし、任意のコードを実行させる手法が存在します。
これを防ぐためには、strcpy ではなく strncpy、gets ではなく fgets といった、読み込み上限を指定できる関数を使用することが推奨されます。
文字列操作関数とヌル文字の関係
標準ライブラリの動作を理解するために、代表的な関数のヌル文字に対する挙動を整理します。
strcpy (文字列のコピー)
コピー元の文字列から、ヌル文字を含めてコピー先のメモリへ転送します。
コピー先に十分な空きがない場合、バッファオーバーランが発生します。
strcat (文字列の連結)
結合先の文字列の末尾にあるヌル文字を探し、そこから新しい文字列を上書きします。
最後に必ずヌル文字を付加して、新しい「一つの文字列」を完成させます。
strcmp (文字列の比較)
2つの文字列を先頭から順に比較していき、両方のヌル文字が同時に現れれば「等しい」と判定します。
一方が先にヌル文字に達した場合、長さが異なるため不等とみなされます。
sprintf (書式付き出力)
指定したバッファに文字列を書き込みますが、最後に必ず自動でヌル文字を付加します。
非常に便利ですが、出力サイズを予測しにくいため、現代ではサイズ指定が可能な snprintf の使用が一般的です。
応用:ヌル文字をデータとして含みたい場合
もし、画像データやバイナリファイルのように、途中に 0 という値が含まれるデータを扱いたい場合、C言語の「文字列関数」は使えません。
なぜなら、途中の 0 を文字列の終わりだと誤認してしまうからです。
このような場合は、char 配列ではなく unsigned char 配列(バイト列)として扱い、memcpy や memcmp といった「長さを明示的に指定するメモリ操作関数」を使用します。
#include <stdio.h>
#include <string.h>
int main(void) {
// 途中に 0 (ヌル文字相当) を含むバイナリデータ
unsigned char data[] = { 0x41, 0x42, 0x00, 0x43, 0x44 };
// strlen では 2 と判定されてしまう
printf("strlenの結果: %zu\n", strlen((char *)data));
// 正しいサイズ(5バイト)を扱うには sizeof や別途管理が必要
printf("実際のデータサイズ: %zu\n", sizeof(data));
return 0;
}strlenの結果: 2
実際のデータサイズ: 5このように、ヌル文字が「データの終わり」を意味するのか、それとも「単なる数値の0」を意味するのかを使い分けることが、C言語マスターへの一歩です。
まとめ
C言語におけるヌル文字(\0)は、単なる数値のゼロ以上の意味を持ち、文字列という概念を成立させるための「境界線」として機能しています。
本記事で解説した重要なポイントを振り返ります。
- ヌル文字の正体:ASCIIコードの
0であり、エスケープシーケンス'\0'で表現される。 - 終端ルール:C言語の文字列は、この文字が出現するまでを一つのデータとして扱う。
- NULLとの違い:
\0は文字データであり、NULLはポインタが空であることを示す。 - メモリの確保:文字列を格納する際は、表示文字数に加えて必ずプラス1バイト(ヌル文字分)の領域を確保する。
- セキュリティ:ヌル終端の欠落やバッファオーバーランは重大なバグの原因となるため、関数の選定には注意する。
ヌル文字は非常にシンプルな仕組みですが、それゆえにプログラマの責任も重くなります。
メモリの向こう側に常にヌル文字を意識しながらコードを書くことで、より堅牢で効率的なプログラムを構築できるようになるでしょう。