C言語を学ぶ上で、避けては通れない非常に重要な概念の一つにポインタがあります。
その中でも、関数への引数としてアドレスを渡すポインタ渡しは、プログラムの実行効率を向上させたり、複数の戻り値を実質的に実現したりするために欠かせないテクニックです。
プログラミング初心者にとって、ポインタは「メモリの住所を扱う」という抽象的なイメージから難解に感じられがちですが、その仕組みを正しく理解すれば、C言語の持つ強力な低レイヤ操作の能力を最大限に引き出すことができます。
本記事では、ポインタ渡しの基本的な仕組みから、値渡しとの決定的な違い、さらには実践的な活用メリットや注意点について、テクニカルな視点から詳しく解説していきます。
C言語におけるポインタ渡しとは何か
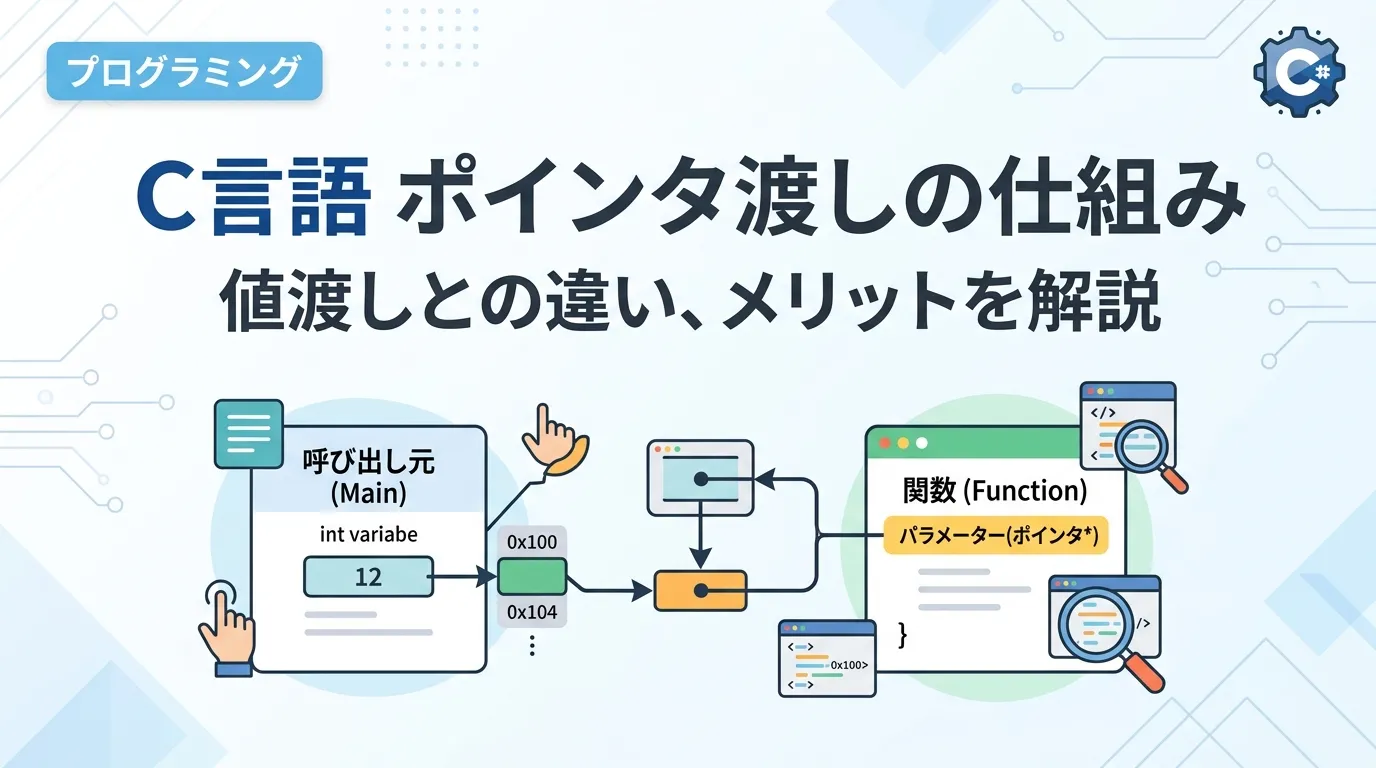
C言語における関数の引数渡しには、大きく分けて「値渡し」と、ポインタを利用した「ポインタ渡し」の2種類が存在します。
厳密に言えば、C言語の仕様上はすべてが「値渡し」であり、ポインタ渡しは「メモリアドレスの値をコピーして渡している」に過ぎません。
しかし、プログラミングの実践においては、これによって呼び出し先の関数から呼び出し元の変数を直接操作できるようになるため、一般的にポインタ渡し(あるいはアドレス渡し)と呼ばれます。
変数とメモリアドレスの関係
ポインタ渡しを理解するためには、まず変数がコンピュータのメモリ上でどのように管理されているかを知る必要があります。
プログラムで変数を宣言すると、メモリ上の特定の場所にその値を格納するための領域が確保されます。
その領域には、一意の番号であるアドレスが割り振られています。
通常の値渡しでは、変数の中身(数値など)だけをコピーして関数に渡しますが、ポインタ渡しではこの「メモリ上の住所(アドレス)」を関数に伝えます。
住所を教えられた関数は、その住所を頼りにメモリへ直接アクセスし、値を書き換えることが可能になるのです。
ポインタ変数の役割
ポインタ渡しを実現するためには、int *ptr のように宣言されるポインタ変数を使用します。
ポインタ変数は、他の変数のアドレスを格納するための特殊な変数です。
関数の引数にポインタ型を指定することで、呼び出し元からアドレスを受け取ることができるようになります。
値渡しとポインタ渡しの決定的な違い
値渡しとポインタ渡しの最大の違いは、「関数内での変更が呼び出し元に波及するかどうか」という点にあります。
この違いを理解するために、それぞれの挙動を詳しく見ていきましょう。
値渡し (Call by Value)
値渡しでは、引数として渡された変数の「値のコピー」が関数のローカル変数として作成されます。
そのため、関数の中でその値をいくら書き換えても、呼び出し元の元の変数には一切影響を与えません。
以下に、値渡しを用いた場合のコード例を示します。
#include <stdio.h>
// 値を書き換えようとする関数(値渡し)
void updateValue(int n) {
n = 100; // 関数内のコピーを書き換える
printf("関数内の値: %d\n", n);
}
int main() {
int x = 10;
printf("呼び出し前のx: %d\n", x);
updateValue(x); // 値をコピーして渡す
printf("呼び出し後のx: %d\n", x);
return 0;
}呼び出し前のx: 10
関数内の値: 100
呼び出し後のx: 10この結果からわかるように、updateValue 関数の中で変数 n を書き換えても、main 関数の変数 x は 10 のまま変化していません。
ポインタ渡し (Pointer Passing)
対してポインタ渡しでは、変数のアドレスを渡します。
関数側では受け取ったアドレスをデリファレンス(間接参照)することで、呼び出し元のメモリ領域を直接操作します。
#include <stdio.h>
// 値を書き換える関数(ポインタ渡し)
void updateValueByPointer(int *p) {
// *p を使って、アドレスの先にある値を書き換える
*p = 100;
printf("関数内での処理が完了しました\n");
}
int main() {
int x = 10;
printf("呼び出し前のx: %d\n", x);
// 変数xのアドレスを & 演算子で渡す
updateValueByPointer(&x);
printf("呼び出し後のx: %d\n", x);
return 0;
}呼び出し前のx: 10
関数内での処理が完了しました
呼び出し後のx: 100このように、ポインタ渡しを利用することで、関数の中から呼び出し元の変数の値を恒久的に変更することが可能になります。
値渡しとポインタ渡しの比較表
| 特徴 | 値渡し | ポインタ渡し |
|---|---|---|
| 渡すデータ | 変数の値のコピー | 変数のメモリアドレス |
| 関数内での変更 | 呼び出し元に影響しない | 呼び出し元に反映される |
| メモリ効率 | 大容量データの場合、コピーコストが高い | アドレス(通常4/8バイト)のみで効率的 |
| 安全性 | 元の値が保護されるため安全 | 誤ったアドレス操作によるバグの危険がある |
| 主な用途 | 計算結果のみが必要な場合 | 複数の戻り値、巨大な構造体の操作など |
ポインタ渡しの具体的な使い方と構文
ポインタ渡しを正しく実装するためには、「アドレス演算子(&)」と「間接参照演算子(*)」の使い分けをマスターする必要があります。
手順1:関数プロトタイプの宣言
関数の引数リストにおいて、ポインタを受け取る変数の型の後ろに * を付けます。
void func(int *ptr);手順2:関数の呼び出し
呼び出し側では、変数名の前に & を付けることで、その変数のアドレスを抽出して関数に渡します。
int num = 0;
func(&num);手順3:関数内部での操作
関数内部では、引数名の前に * を付けることで、そのアドレスに格納されている実体にアクセス(デリファレンス)します。
void func(int *ptr) {
*ptr = 50; // ptrが指すアドレスの値を50に書き換える
}ポインタ渡しを利用するメリット
なぜC言語のプログラミングにおいて、わざわざ複雑なポインタ渡しを多用するのでしょうか。
それには主に3つの大きなメリットがあるからです。
1. 関数の外にある複数の値を更新できる
C言語の return 文は、基本的に一つの値しか返すことができません。
しかし、複数の計算結果を呼び出し元に伝えたい場合、ポインタ渡しを使えば実質的に複数の戻り値を得ることができます。
以下の例は、2つの数値の「合計」と「差」を同時に算出する関数です。
#include <stdio.h>
void calculate(int a, int b, int *sum, int *diff) {
*sum = a + b;
*diff = a - b;
}
int main() {
int s, d;
calculate(30, 10, &s, &d);
printf("合計: %d, 差: %d\n", s, d);
return 0;
}合計: 40, 差: 20このように、引数経由で値を書き戻すことで、関数の制限を超えた柔軟なデータの受け渡しが可能になります。
2. メモリの消費と処理時間を節約できる
大きなサイズの構造体や配列を関数に渡す際、値渡しを行うと、そのデータ全体がスタックメモリ上にコピーされます。
例えば1KBの構造体を値渡しで渡すと、関数を呼び出すたびに1KBのコピーが発生し、パフォーマンスの低下やメモリ不足を招く恐れがあります。
一方、ポインタ渡しであれば、渡されるのはアドレス(数バイト程度)のみです。
データの本体がどれだけ巨大であっても、ポインタのサイズは一定であるため、極めて高速かつ省メモリに処理を行うことができます。
3. 動的なデータ構造の操作
リンクドリスト(連結リスト)や木構造などの複雑なデータ構造を扱う場合、各ノードのアドレスをポインタで管理し、関数間で受け渡しすることで、動的なメモリ操作を効率的に行うことができます。
実践的な活用シーン:構造体のポインタ渡し
C言語の実務開発において最も頻繁にポインタ渡しが使われるのが、「構造体」の操作です。
構造体をポインタで渡す場合、ドット演算子 . の代わりにアロー演算子 -> を使用するのが一般的です。
#include <stdio.h>
#include <string.h>
typedef struct {
char name[50];
int age;
} Person;
// 構造体のポインタ渡し
void updatePerson(Person *p, const char *newName, int newAge) {
// p->name は (*p).name と同等
strcpy(p->name, newName);
p->age = newAge;
}
int main() {
Person myProfile = {"名無し", 0};
printf("更新前: %s (%d歳)\n", myProfile.name, myProfile.age);
updatePerson(&myProfile, "田中太郎", 25);
printf("更新後: %s (%d歳)\n", myProfile.name, myProfile.age);
return 0;
}更新前: 名無し (0歳)
更新後: 田中太郎 (25歳)Person 構造体のような複数のメンバを持つデータを扱う場合、ポインタ渡しは必須のテクニックとなります。
ポインタ渡しを使用する際の注意点とバグ対策
ポインタ渡しは強力である反面、一歩間違えるとプログラムの異常終了(セグメンテーションフォールト)や、メモリリーク、データの破壊を引き起こすリスクがあります。
安全に使用するためのポイントを整理しておきましょう。
NULLポインタのチェック
関数側で受け取ったポインタが、正しいアドレスを指しているとは限りません。
呼び出し側が誤って NULL を渡した場合、そのままアクセスするとプログラムがクラッシュします。
void safeFunction(int *p) {
if (p == NULL) {
printf("エラー: ポインタがNULLです\n");
return;
}
*p = 10;
}このように、関数の入り口でポインタが有効かどうかをチェックする癖をつけることが、堅牢なプログラムへの第一歩です。
書き換えを禁止したい場合の const 指定
「メモリ効率のためにポインタ渡しを使いたいが、関数内で値を書き換えられたくない」というケースもあります。
その場合は、const 修飾子を付与します。
void displayLargeData(const BigData *data) {
// data->value = 100; // これはコンパイルエラーになるため安全
printf("%d", data->value);
}const を活用することで、ポインタ渡しのメリット(効率性)を享受しつつ、値渡しのメリット(安全性)を確保することができます。
ローカル変数のアドレスを返さない
ポインタに関連する最も危険なバグの一つが、関数のローカル変数のアドレスを戻り値として返してしまうことです。
int* dangerousFunction() {
int temp = 10;
return &temp; // エラー: 関数終了時にtempは消滅するため、返されたアドレスは無効
}関数の実行が終了すると、その関数内のローカル変数はメモリから解放されます。
解放された場所を指し続けるポインタ(ダングリングポインタ)を参照することは、未定義の動作を引き起こします。
アドレスをやり取りする際は、その変数の寿命(スコープ)を常に意識しなければなりません。
まとめ
C言語におけるポインタ渡しは、単に変数の値を渡すだけでなく、プログラムの柔軟性と実行効率を劇的に向上させるための鍵となる機能です。
今回の内容をまとめると、以下のようになります。
- ポインタ渡しとは、変数のメモリアドレスを渡すことで、呼び出し先の関数から元の値を直接操作する手法である。
- 値渡しはデータのコピーを作成するため元の値が保護されるが、大きなデータの扱いには不向きである。
- ポインタ渡しを使うことで、複数の戻り値を実現したり、メモリの節約が可能になったりする。
- 構造体の操作にはアロー演算子
->を使用し、安全性のためにNULLチェックやconstを活用する。
ポインタは慣れるまで時間がかかる概念ですが、ポインタ渡しを使いこなせるようになれば、C言語の持つ真のパワーを実感できるようになります。
まずは簡単な swap 関数や構造体の更新から練習を始め、徐々に複雑なデータ構造の操作へとステップアップしていきましょう。