C#を用いたアプリケーション開発において、日本語入力が想定されるシステムでは全角と半角の変換処理が頻繁に求められます。
ユーザーが入力するデータには全角英数字や半角カタカナが混在しやすく、データベースの検索精度向上や表示の統一感を保つためには、プログラム側での正規化が不可欠です。
本記事では、C#で全角・半角変換を行うための主要な手法から、パフォーマンスを意識した実装例、さらには注意すべき文字コードの特性まで、エンジニアが実務で即活用できる情報を詳しく解説します。
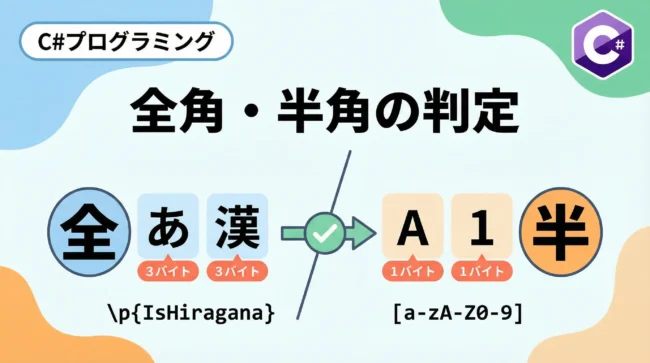
全角・半角変換が必要とされる背景と基礎知識
日本のシステム開発において、全角・半角の混在は避けて通れない課題です。
かつてメモリやディスク容量が極めて貴重だった時代、日本語を扱うために「半角カタカナ」という特殊な文字セットが作られました。
その後、多機能な全角文字(2バイト文字)が普及しましたが、現在でも過去のデータとの互換性や、限られた表示スペースへの対応として半角文字が利用され続けています。
C#でこれらの文字を扱う際、まず理解しておくべきはUnicode(UTF-16)における文字の扱いです。
多くの英数字や記号は、全角と半角で異なる文字コードが割り当てられています。
例えば、半角の A は U+0041 ですが、全角の A は U+FF21 です。
この規則性を利用して変換を行うか、あるいは標準ライブラリの機能を利用するかが、実装の分かれ道となります。
特に、Webフォームからの入力データや、レガシーな基幹システムから出力されたCSVファイルのインポート処理などでは、データクレンジングの一環として変換処理を組み込むことが一般的です。
Visual Basicライブラリを使用した変換方法
C#で最も手軽に全角・半角変換を実現する方法の一つに、Microsoft.VisualBasic 名前空間の Strings.StrConv メソッドを使用する方法があります。
Visual Basicという名称が含まれていますが、C#プロジェクトから参照を追加することで問題なく利用可能です。
StrConvメソッドによる一括変換
このメソッドは、引数に指定する VbStrConv 列挙型によって、全角から半角、半角から全角への変換を制御します。
using System;
using Microsoft.VisualBasic; // プロジェクトの参照追加が必要
class Program
{
static void Main()
{
string input = "アイウエオ カキクケコ 123 ABC ABC 123";
// 半角から全角へ変換
string wide = Strings.StrConv(input, VbStrConv.Wide, 0);
// 全角から半角へ変換
string narrow = Strings.StrConv(input, VbStrConv.Narrow, 0);
Console.WriteLine("元の文字列: " + input);
Console.WriteLine("全角に変換: " + wide);
Console.WriteLine("半角に変換: " + narrow);
}
}元の文字列: アイウエオ カキクケコ 123 ABC ABC 123
全角に変換: アイウエオ カキクケコ 123 ABC ABC 123
半角に変換: アイウエオ カキクケコ 123 ABC ABC 123注意点と.NET Core以降の対応
StrConv メソッドは内部的に Windows API(LCMapString)を使用しているため、Windows環境以外(Linux上の.NETコンテナなど)では期待通りに動作しない、あるいは例外が発生する可能性がある点に注意が必要です。
また、.NET 5以降のモダンな環境でこの機能を利用する場合、プロジェクトファイル(.csproj)の設定や追加のパッケージ導入が必要になることがあります。
クロスプラットフォーム環境をターゲットにする場合は、後述する手動マッピング方式や外部ライブラリの検討が推奨されます。
手動マッピングによる高速かつクロスプラットフォームな変換
OSのAPIに依存せず、いかなる環境でも安定して動作させるためには、文字コードの差分を利用した手動変換の実装が最適です。
特に英数字については、Unicode上で全角と半角が一定の距離(0xFEE0)を保って配置されているため、単純な加減算で変換可能です。
英数字の変換ロジック
以下のサンプルコードは、英数字および一般的な記号に絞って全角・半角変換を行うクラスの例です。
using System;
using System.Text;
public static class CharConverter
{
// 全角英数字を半角に変換
public static string ToNarrow(string input)
{
if (string.IsNullOrEmpty(input)) return input;
char[] chars = input.ToCharArray();
for (int i = 0; i < chars.Length; i++)
{
// 全角英数字・記号の範囲
if (chars[i] >= 0xFF01 && chars[i] <= 0xFF5E)
{
chars[i] = (char)(chars[i] - 0xFEE0);
}
// 全角スペースの処理
else if (chars[i] == 0x3000)
{
chars[i] = (char)0x0020;
}
}
return new string(chars);
}
// 半角英数字を全角に変換
public static string ToWide(string input)
{
if (string.IsNullOrEmpty(input)) return input;
char[] chars = input.ToCharArray();
for (int i = 0; i < chars.Length; i++)
{
// 半角英数字・記号の範囲
if (chars[i] >= 0x0021 && chars[i] <= 0x007E)
{
chars[i] = (char)(chars[i] + 0xFEE0);
}
// 半角スペースの処理
else if (chars[i] == 0x0020)
{
chars[i] = (char)0x3000;
}
}
return new string(chars);
}
}
class Program
{
static void Main()
{
string sample = "Hello C# 2026!";
string result = CharConverter.ToNarrow(sample);
Console.WriteLine("変換前: " + sample);
Console.WriteLine("変換後: " + result);
}
}変換前: Hello C# 2026!
変換後: Hello C# 2026!カタカナ変換の難しさ(濁音・半濁音の処理)
英数字と異なり、カタカナの変換には注意が必要です。
半角カタカナの「ガ」(カ + ゙)は、2つの文字(基底文字と結合文字)で構成されていますが、全角の「ガ」は1つの文字です。
このような「2文字から1文字」あるいは「1文字から2文字」への変換が発生するため、単純なループ処理ではなく、Dictionaryを用いたマッピングテーブルの定義が必要になります。
正規表現を用いた特定の文字種のみの変換
「住所フィールドの番地だけを半角にしたい」「氏名フリガナのカタカナだけを全角にしたい」といったケースでは、Regex.Replace と MatchEvaluator を組み合わせる手法が有効です。
特定範囲の文字を抽出して変換する
以下の例では、文字列内の全角数字のみを特定し、それを半角に変換しています。
using System;
using System.Text.RegularExpressions;
class Program
{
static void Main()
{
string input = "東京都千代田区1-2-3 ABCビル5階";
// 全角数字(0-9)にマッチする正規表現
string pattern = "[0-9]+";
string result = Regex.Replace(input, pattern, m =>
{
// マッチした部分ごとに変換処理を実行
char[] chars = m.Value.ToCharArray();
for (int i = 0; i < chars.Length; i++)
{
chars[i] = (char)(chars[i] - 0xFEE0);
}
return new string(chars);
});
Console.WriteLine("元の文字列: " + input);
Console.WriteLine("数字のみ半角: " + result);
}
}元の文字列: 東京都千代田区1-2-3 ABCビル5階
数字のみ半角: 東京都千代田区1-2-3 ABCビル5階この手法のメリットは、変換対象を細かく制御できる点にあります。
一括変換では変換したくない記号(ハイフンや長音記号など)を除外する場合に非常に便利です。
Unicode正規化と全角・半角の関係
C#の string.Normalize メソッドを使用することで、Unicodeの標準的な正規化処理を行うことができます。
全角・半角の変換とは厳密には異なりますが、互換性等価(Normalization Form KC/KD)を用いることで、一部の文字を正規化する副次的な効果として全角・半角の統一が行われます。
Normalizeメソッドによる変換
using System;
using System.Text;
class Program
{
static void Main()
{
// 全角カタカナ、全角英数字、半角カタカナが混在
string input = "テスト ガイダンス 123 123";
// FormKC (Compatibility Decomposition, followed by Canonical Composition)
string normalized = input.Normalize(NormalizationForm.FormKC);
Console.WriteLine("元データ: " + input);
Console.WriteLine("正規化後: " + normalized);
}
}元データ: テスト ガイダンス 123 123
正規化後: テスト ガイダンス 123 123NormalizationForm.FormKC を使用すると、半角カタカナは全角カタカナに、全角英数字は半角英数字に変換されます。
これは、日本のビジネスアプリケーションにおいて「最も標準的な状態」に近づける処理として非常に有用です。
ただし、濁音の結合状態が意図せず変化する場合や、一部の特殊記号が変換される可能性があるため、事前の検証が欠かせません。
実務で役立つ拡張メソッドの実装例
変換処理をプロジェクト全体で使いやすくするために、string 型の拡張メソッドとして定義しておくことを推奨します。
これにより、コードの可読性が大幅に向上します。
究極の変換ユーティリティクラス
以下に、実務で使いやすいように設計された変換ユーティリティの例を示します。
using System;
using System.Collections.Generic;
using System.Text;
public static class StringExtensions
{
/// <summary>
/// 文字列内の全角英数字を半角に、半角カタカナを全角に正規化します。
/// </summary>
public static string ToStandardJapanese(this string self)
{
if (string.IsNullOrEmpty(self)) return self;
// Unicode正規化(NFKC)を利用するのが最も効率的
return self.Normalize(NormalizationForm.FormKC);
}
/// <summary>
/// 全角英数字のみを半角に変換します(カタカナは維持)。
/// </summary>
public static string ToNarrowAlphanumeric(this string self)
{
if (string.IsNullOrEmpty(self)) return self;
char[] chars = self.ToCharArray();
for (int i = 0; i < chars.Length; i++)
{
if (chars[i] >= '!' && chars[i] <= '~')
{
chars[i] = (char)(chars[i] - 0xFEE0);
}
else if (chars[i] == ' ')
{
chars[i] = ' ';
}
}
return new string(chars);
}
}
// 呼び出し側のコード
class Program
{
static void Main()
{
string messyText = "C#プログラミング 2026";
// 拡張メソッドで直感的に呼び出し
string cleanText = messyText.ToStandardJapanese();
Console.WriteLine($"変換前: {messyText}");
Console.WriteLine($"変換後: {cleanText}");
}
}変換前: C#プログラミング 2026
変換後: C#プログラミング 2026パフォーマンス比較と手法の選び方
変換処理の選択基準は、「開発速度」「実行速度」「ポータビリティ」の3点です。
| 手法 | 実行速度 | ポータビリティ | 特徴 |
|---|---|---|---|
| Microsoft.VisualBasic | 普通 | 低 (Windows依存) | 実装が最も容易。古いプロジェクトで多用。 |
| 手動マッピング (charループ) | 最高 | 高 | 依存関係がなく最速。英数字のみなら最適。 |
| Unicode正規化 (NFKC) | 普通 | 高 | カタカナの結合なども含め、標準的な変換が可能。 |
| 正規表現 (Regex) | 低 | 高 | 複雑な条件指定が可能だが、オーバーヘッドが大きい。 |
大量のデータをバッチ処理する場合や、高トラフィックなWeb APIで利用する場合は、手動マッピング方式または十分に検証された拡張メソッドを使用してください。
逆に、社内向けのWindowsデスクトップツールなどであれば、StrConv を利用して実装工数を削減するのが合理的です。
まとめ
C#における全角・半角変換は、単なる文字の置き換え以上に、日本のシステム文化やUnicodeの仕様が深く関わっています。
- 手軽さを優先するなら Microsoft.VisualBasic.Strings.StrConv
- OSを選ばず標準的な変換を行うなら string.Normalize(NormalizationForm.FormKC)
- パフォーマンスと特定の文字種へのこだわりが必要なら 手動のマッピング処理
これらを用途に合わせて使い分けることが、堅牢なアプリケーションへの第一歩です。
特に昨今のクラウド開発(AzureやAWS上のLinuxコンテナ)では、Windows APIに依存しない実装が強く求められます。
今回紹介した Normalize メソッドや手動の文字コード計算をベースに、プロジェクトに最適な変換ライブラリを構築してみてください。
適切なデータ正規化を行うことで、検索漏れの防止やUIの崩れといったトラブルを未然に防ぎ、ユーザーにとって使いやすいシステムを提供できるようになります。