C#におけるデータ構造の管理は、効率的でスケーラブルなアプリケーションを開発する上で非常に重要な要素です。
特に、データを追加された順番どおりに処理したい場合には、「キュー(Queue)」というデータ構造が頻繁に利用されます。
キューは「先入れ先出し(FIFO: First-In, First-Out)」の原則に基づき、最初に入力されたデータから順番に取り出して処理を行う仕組みです。
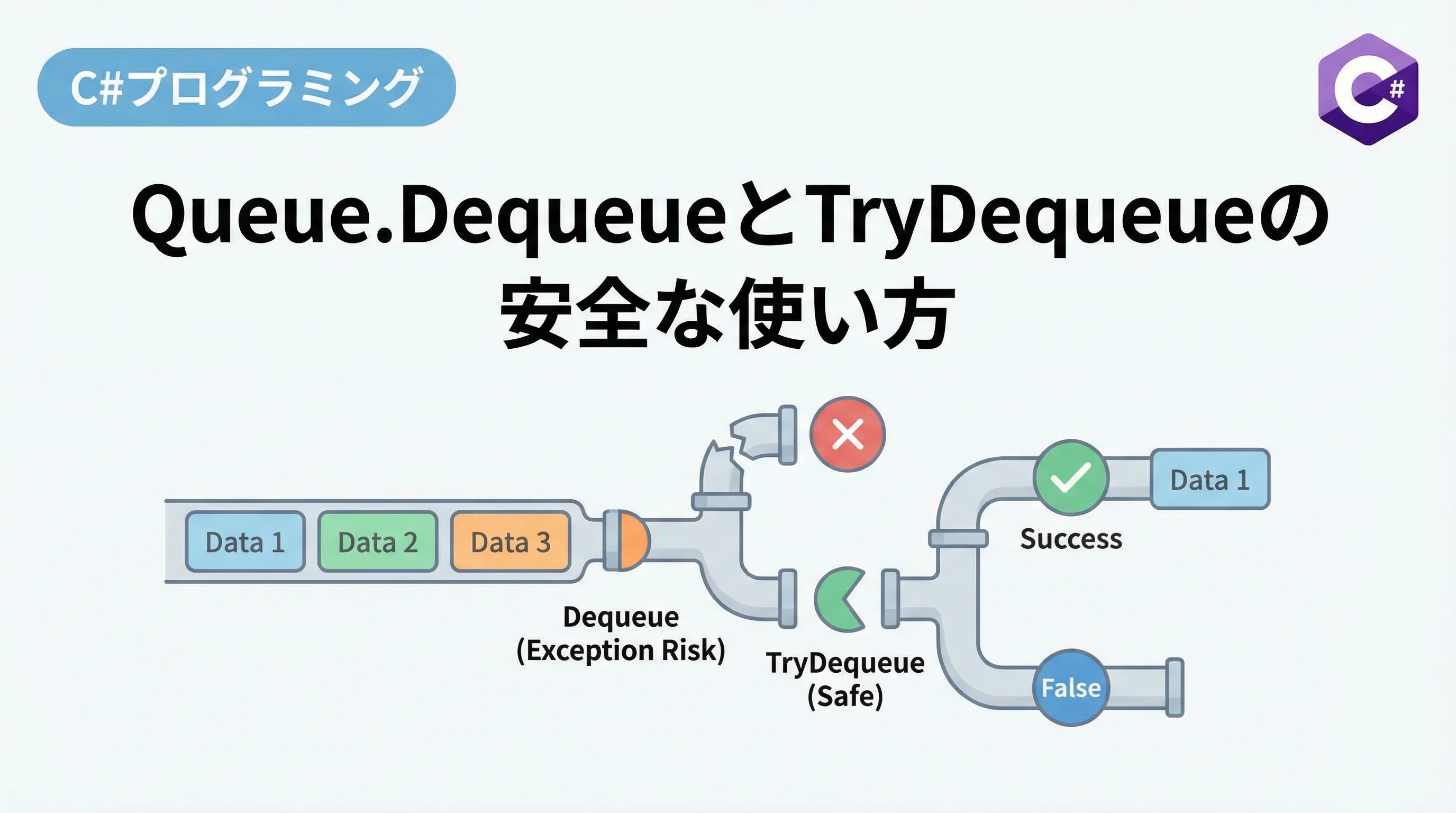
このキュー操作において、核となるメソッドが Dequeue です。
しかし、単純に Dequeue を呼び出すだけでは、キューが空の場合に例外が発生するといったリスクも伴います。
現代的なC#プログラミングでは、これらのリスクを回避するために TryDequeue メソッドを活用することが推奨されています。
本記事では、C#の Queue<T> クラスにおけるデータの取り出し処理に焦点を当て、基本的な使い方から例外処理、そしてより安全な実装パターンまでを詳しく解説します。
C#におけるQueue<T>の基本概念
C#でキューを扱う場合、通常は System.Collections.Generic 名前空間に用意されている generic型の Queue<T> クラスを使用します。
このクラスは、特定の型のオブジェクトを順番に格納し、取り出すための最適化されたアルゴリズムを提供します。
FIFO(First-In, First-Out)とは
キューの最大の特徴は FIFO です。
これは、レジの行列やプリンターの印刷ジョブのように、「先に並んだものから順番に処理される」というルールを指します。
C#の Queue<T> において、要素を追加する操作を「Enqueue(エンキュー)」、要素を取り出す操作を「Dequeue(デキュー)」と呼びます。
リスト(List<T>)でも同様のことは可能ですが、リストの先頭要素を削除する操作(RemoveAt(0))は、残りの全要素を一つずつ前にずらす必要があるため、要素数が多い場合にパフォーマンスが著しく低下します。
それに対し、Queue<T> は内部的にリングバッファ構造などを利用しているため、先頭からの取り出しを非常に高速(O(1))に行えるという利点があります。
Queue<T>クラスの主要なメソッド
キューを操作する上で覚えておくべき主なメソッドは以下の3つです。
- Enqueue(T item)
Enqueue(T item):キューの末尾に要素を追加します。- Dequeue()
Dequeue():キューの先頭にある要素を取り出し、それを返します。取り出された要素はキューから削除されます。
- Peek()
Peek():キューの先頭にある要素を返しますが、キューからは削除しません。
Dequeueメソッドの使い方と動作
Dequeue メソッドは、キューに蓄積されたデータのうち、最も古い(最初に入れた)データを取り出すために使用します。
戻り値として取り出した要素を返し、同時にその要素をキューから完全に消去します。
基本的な実装例
まずは、文字列型のキューを作成し、複数のデータを追加してから順番に取り出す基本的なコードを見てみましょう。
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
// 文字列型のキューを初期化
Queue<string> messageQueue = new Queue<string>();
// データを追加 (Enqueue)
messageQueue.Enqueue("第1メッセージ");
messageQueue.Enqueue("第2メッセージ");
messageQueue.Enqueue("第3メッセージ");
Console.WriteLine($"現在のキューの数: {messageQueue.Count}");
// データを取り出す (Dequeue)
string first = messageQueue.Dequeue();
Console.WriteLine($"取り出し1: {first}");
string second = messageQueue.Dequeue();
Console.WriteLine($"取り出し2: {second}");
Console.WriteLine($"取り出し後のキューの数: {messageQueue.Count}");
}
}現在のキューの数: 3
取り出し1: 第1メッセージ
取り出し2: 第2メッセージ
取り出し後のキューの数: 1この例から分かるように、Dequeue を呼び出すたびにキューのカウント(Count プロパティ)が減少し、追加した順番どおりにデータが取得されています。
Dequeueで発生する例外
Dequeue メソッドを使用する際に最も注意しなければならないのが、キューが空の状態で呼び出した場合に発生する例外です。
もしキューの中に要素が一つもない状態で Dequeue() を実行すると、InvalidOperationException がスローされます。
この例外を適切にハンドリングしないと、アプリケーションはクラッシュしてしまいます。
Queue<int> numbers = new Queue<int>();
// キューが空の状態でDequeueを呼ぶ
int value = numbers.Dequeue(); // ここで InvalidOperationException が発生この問題を回避する従来の方法は、Count プロパティを確認することでした。
if (numbers.Count > 0)
{
int value = numbers.Dequeue();
// 処理を行う
}しかし、マルチスレッド環境や、より簡潔なコードを記述したい場合には、次に解説する TryDequeue が非常に有効です。
TryDequeueによる安全な要素取得
.NET Core 以降(および .NET 5 以降のモダンな .NET 環境)では、Queue<T> クラスに TryDequeue メソッドが追加されました。
これは、要素の存在確認と取り出しを一つのステップで行うことができる、非常に便利なメソッドです。
TryDequeueの構文と戻り値
TryDequeue は、以下のようなシグネチャを持っています。
public bool TryDequeue(out T result);- 戻り値:キューから要素が正常に取り出せた場合は
true、空だった場合はfalseを返します。 - out 引数:取り出された要素が格納されます。キューが空の場合は、型のデフォルト値(
intなら 0、参照型ならnull)が格納されます。
TryDequeueの使用例
TryDequeue を使うことで、例外処理や事前のカウントチェックを記述することなく、安全に要素を取り出すことができます。
using System;
using System.Collections.Generic;
class Program
{
static void Main()
{
Queue<int> jobQueue = new Queue<int>();
jobQueue.Enqueue(101);
jobQueue.Enqueue(102);
// ループで安全に取り出す
while (jobQueue.TryDequeue(out int jobID))
{
Console.WriteLine($"ジョブ ID: {jobID} を処理中...");
}
// すでにキューは空だが、TryDequeueなら例外は起きない
if (jobQueue.TryDequeue(out int result))
{
Console.WriteLine($"取得成功: {result}");
}
else
{
Console.WriteLine("キューは空です。処理をスキップしました。");
}
}
}ジョブ ID: 101 を処理中...
ジョブ ID: 102 を処理中...
キューは空です。処理をスキップしました。このように、TryDequeue は 「取得できるなら取得し、できないなら安全に失敗する」という挙動をシンプルに実装できるため、現代のC#開発におけるデファクトスタンダードとなっています。
Peekメソッドとの使い分け
Dequeue とよく比較されるのが Peek メソッドです。
どちらもキューの先頭要素にアクセスしますが、その挙動には明確な違いがあります。
DequeueとPeekの比較
| 特徴 | Dequeue() / TryDequeue() | Peek() / TryPeek() |
|---|---|---|
| 要素の取得 | 先頭要素を取得する | 先頭要素を取得する |
| キューの変更 | 要素を削除する | 要素を削除しない |
| 用途 | タスクを実行して完了させる時 | 次のタスクを事前に確認する時 |
例えば、「次に処理すべきデータの内容を確認してから、特定の条件下で実際に処理を開始したい」という場合には、まず Peek で内容をチェックし、問題がなければ Dequeue で取り出すという手順を踏みます。
ただし、Peek もキューが空のときに呼び出すと例外が発生するため、安全性を考慮するなら TryPeek を使用するのが賢明です。
パフォーマンスとメモリ管理の最適化
大量のデータをキューで扱う場合、Dequeue の効率だけでなく、キュー全体のメモリ管理についても理解しておく必要があります。
計算量(Time Complexity)
Queue<T>.Dequeue メソッドの計算量は O(1) です。
これは、キューの要素数が10個であっても100万個であっても、要素の取り出しにかかる時間は一定であることを意味します。
内部的には配列を利用した循環バッファで実装されているため、リストのような要素の詰め替えが発生せず、非常に軽量な操作です。
容量の自動調整とメモリ
キューに要素を追加し続けると、内部の配列が不足した際に自動的にリサイズ(拡張)が行われます。
しかし、Dequeue によって要素を取り出したとしても、内部配列のサイズは自動的には縮小されません。
もし一時的に膨大なデータをキューに積み、その後にほとんどを Dequeue した場合、メモリ上に大きな空の配列が残ることになります。
これを解消してメモリを節約したい場合は、TrimExcess() メソッドを呼び出すことで、現在の要素数に合わせて内部バッファを最適化できます。
Queue<int> largeQueue = new Queue<int>();
// 100万個追加
for (int i = 0; i < 1000000; i++) largeQueue.Enqueue(i);
// 全て取り出し
while (largeQueue.Count > 0) largeQueue.Dequeue();
// この時点ではメモリを多く占有したままなので、解放を促す
largeQueue.TrimExcess();実践的な活用シーン:生産者・消費者パターン
Dequeue の最も一般的な活用例は、「プロデューサー・コンシューマー(生産者・消費者)パターン」です。
これは、データを生成する側と処理する側を分離し、キューを介してデータの受け渡しを行う設計です。
シンプルなタスク処理システムの例
以下のコードは、バックグラウンドジョブをキューに溜め込み、それを順番に処理するシンプルなワーカークラスのイメージです。
using System;
using System.Collections.Generic;
using System.Threading;
public class TaskWorker
{
private Queue<string> _tasks = new Queue<string>();
public void AddTask(string taskName)
{
_tasks.Enqueue(taskName);
Console.WriteLine($"[追加]: {taskName}");
}
public void Run()
{
Console.WriteLine("ワーカーを開始します...");
while (true)
{
// TryDequeueを使って安全にタスクを取り出す
if (_tasks.TryDequeue(out string currentTask))
{
Console.WriteLine($"[実行中]: {currentTask} を処理しています...");
// 擬似的な処理時間
Thread.Sleep(500);
}
else
{
// タスクがない場合は少し待機して再確認、または終了
Console.WriteLine("タスク待ち...");
Thread.Sleep(2000);
// サンプルのため、キューが空なら終了
if (_tasks.Count == 0) break;
}
}
Console.WriteLine("全てのタスクが完了しました。");
}
}このような構造にすることで、UIスレッドを止めずにバックグラウンドで重い処理を順番にこなす、といった制御が可能になります。
スレッド安全性とConcurrentQueue<T>
標準の Queue<T> はスレッドセーフではありません。
つまり、複数のスレッドから同時に Enqueue や Dequeue を呼び出すと、内部データが破損したり、予期せぬ例外が発生したりする恐れがあります。
マルチスレッド環境(例えば、複数のスレッドが同時にキューにデータを放り込み、別の複数のスレッドがそれを取り出すようなケース)では、System.Collections.Concurrent 名前空間にある ConcurrentQueue<T> を使用する必要があります。
ConcurrentQueueにおける取り出し
ConcurrentQueue<T> には、通常の Dequeue メソッドは存在しません。
代わりに、常に安全な取り出しを行うための TryDequeue メソッドが提供されています。
using System.Collections.Concurrent;
ConcurrentQueue<int> safeQueue = new ConcurrentQueue<int>();
safeQueue.Enqueue(10);
// マルチスレッド環境でも安全
if (safeQueue.TryDequeue(out int result))
{
// 処理
}ConcurrentQueue<T> の TryDequeue は、内部でロックフリーなアルゴリズムや適切な同期処理が行われているため、開発者が自分で lock 文を書く手間を省きつつ、高いパフォーマンスを維持できます。
Dequeueを使いこなすためのベストプラクティス
これまでの内容を踏まえ、C#でキューの取り出し処理を実装する際のベストプラクティスをまとめます。
- 原則として TryDequeue を使用する
特別な理由がない限り、例外リスクを伴う
Dequeueよりも、安全なTryDequeueを選択しましょう。これによりコードが簡潔になり、意図しないクラッシュを防げます。
- 空チェックと取り出しの「アトミック性」を意識する
if (Count > 0) { Dequeue(); }のような書き方はシングルスレッドでは問題ありませんが、マルチスレッド環境では「Countチェックと Dequeue の間」に他のスレッドが要素を奪う可能性があります。このため操作を一気に完結させる
TryDequeueの使用が推奨されます。- 値型と参照型のデフォルト値に注意する
TryDequeueが失敗した際、out引数にはデフォルト値が入ります。参照型は
null、値型(例:intや構造体)は 0 や初期値になります。戻り値の
boolを確認せずにout引数だけを参照すると、キューから取得した値なのか失敗によるデフォルト値なのか判別できなくなるため注意してください。- インターフェースによる抽象化
メソッドの引数などでキューを受け取る際は、具体的な
Queue<T>クラスではなく、IEnumerable<T>や読み取り専用のコレクションとして公開することを検討してください。ただし FIFO の取り出し(
Dequeue)などキュー特有の操作が必要な場合は、適切にカプセル化して明確なインターフェースを提供しましょう。
まとめ
C#の Queue<T>.Dequeue メソッドは、FIFOアルゴリズムを実装する上での基本となる操作です。
しかし、空のキューに対する操作が例外を引き起こすという性質上、事前のチェックや適切な例外ハンドリングが欠かせません。
現代のC#開発においては、より安全で効率的な TryDequeue メソッドを活用することが、堅牢なコードを書くための近道です。
特に .NET Core 以降の環境では、このメソッド一つで「存在確認」と「取得」を安全に行えるため、積極的に採用すべきでしょう。
また、単一スレッドでの利用か、あるいはマルチスレッド環境での利用かに応じて、標準の Queue<T> と ConcurrentQueue<T> を適切に使い分けることも重要です。
これらの知識を正しく組み合わせることで、データの整合性を保ちつつ、高いパフォーマンスを発揮するアプリケーションを構築できるようになります。
キューの操作をマスターすることは、データ構造の理解を深めるだけでなく、実務におけるメッセージ処理や非同期タスク管理など、幅広い分野での応用力に繋がります。
ぜひ本記事で紹介したテクニックを、日々のコーディングに役立ててください。