C#の開発において、リスト内のデータ重複を適切に処理することは、メモリ効率の向上や計算精度の維持において非常に重要です。
特に大規模なデータを扱うシステムや、外部APIから取得したリストを加工する際、重複した要素を排除したり、逆に重複しているデータのみを特定してエラーチェックに利用したりする場面は頻繁に発生します。
本記事では、LINQを用いた直感的な手法から、HashSetを活用した高速な手法、さらには.NET 6以降で推奨される最新の記述方法まで、現場で役立つ実践的なテクニックを網羅的に解説します。
1. LINQを使用した基本的な重複削除
C#でリストの重複を削除する最も一般的かつ簡潔な方法は、LINQ(Language Integrated Query)のDistinctメソッドを使用することです。
このメソッドは、コレクション内の要素を評価し、重複を除いた一意の要素のみを含む新しい列挙子を返します。
1.1 Distinctメソッドの基本
Distinctは、数値や文字列などのプリミティブ型(値型および文字列)に対して非常に強力に機能します。
内部的にはデフォルトの比較子(EqualityComparer)を使用して、各要素が同一かどうかを判定しています。
using System;
using System.Collections.Generic;
using System.Linq;
public class Program
{
public static void Main()
{
// 重複を含む数値リスト
List<int> numbers = new List<int> { 1, 2, 2, 3, 4, 4, 4, 5 };
// Distinctを使用して重複を削除
List<int> distinctNumbers = numbers.Distinct().ToList();
Console.WriteLine("元のリスト: " + string.Join(", ", numbers));
Console.WriteLine("重複削除後: " + string.Join(", ", distinctNumbers));
}
}元のリスト: 1, 2, 2, 3, 4, 4, 4, 5
重複削除後: 1, 2, 3, 4, 51.2 Distinct使用時の注意点
Distinctメソッドは「遅延実行」されるという特性があります。
メソッドを呼び出した時点では計算は行われず、foreachで回したりToList()を呼び出したりしたタイミングで初めて処理が実行されます。
そのため、元のリストが非常に巨大な場合、何度も評価を行うとパフォーマンスに影響を与える可能性がある点に注意が必要です。
また、後述するように独自のクラス(参照型)のリストに対してDistinctをそのまま使用しても、期待通りに動作しないケースがあります。
これは、インスタンスの参照先が異なれば、保持している値が同じでも「別物」と判断されるためです。
2. 特定のプロパティで重複を削除する(DistinctBy)
実務では、単なる値の比較ではなく「ユーザーIDが同じなら重複とみなす」といった、オブジェクトの特定のプロパティに基づいた重複削除が必要になります。
かつてはGroupByを組み合わせて実現していましたが、.NET 6以降ではDistinctByという便利なメソッドが追加されました。
2.1 DistinctByの活用例
DistinctByを使用すると、ラムダ式を用いて「どのプロパティを基準にするか」を明示的に指定できます。
using System;
using System.Collections.Generic;
using System.Linq;
public class User
{
public int Id { get; set; }
public string Name { get; set; }
}
public class Program
{
public static void Main()
{
List<User> users = new List<User>
{
new User { Id = 1, Name = "田中" },
new User { Id = 2, Name = "佐藤" },
new User { Id = 1, Name = "田中(重複)" }, // Idが重複
new User { Id = 3, Name = "鈴木" }
};
// Idプロパティを基準に重複を排除
var uniqueUsers = users.DistinctBy(u => u.Id).ToList();
foreach (var user in uniqueUsers)
{
Console.WriteLine($"ID: {user.Id}, Name: {user.Name}");
}
}
}ID: 1, Name: 田中
ID: 2, Name: 佐藤
ID: 3, Name: 鈴木この手法の優れた点は、コードの可読性が極めて高いことです。
従来のGroupBy().Select(g => g.First())という記述に比べて、意図が明確になり、メンテナンス性も向上します。
なお、重複があった場合は「最初に見つかった要素」が保持されます。
3. HashSetを使用した高速な重複削除
パフォーマンスが極めて重要なシナリオでは、HashSet<T>クラスを利用するのが最適です。
HashSet<T>は数学的な集合を表すコレクションであり、重複する要素を保持できないという特性を持っています。
3.1 HashSetによる一意なリストの作成
既存のリストからHashSetを作成するだけで、高速に重複を排除できます。
using System;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
List<string> items = new List<string> { "Apple", "Banana", "Apple", "Orange", "Banana" };
// HashSetのコンストラクタにリストを渡すだけで重複が消える
HashSet<string> set = new HashSet<string>(items);
// 再びListに戻す
List<string> uniqueItems = new List<string>(set);
Console.WriteLine(string.Join(", ", uniqueItems));
}
}Apple, Banana, Orange3.2 HashSetとLINQのパフォーマンス比較
LINQのDistinctも内部的にはHashSetに似た仕組みを使用していますが、HashSetを直接生成する方が、オーバーヘッドが少なくなる場合があります。
特に、大量のデータに対して「すでに追加済みかどうか」を判定しながらループを回すような処理では、HashSet.Add()メソッドがboolを返す(追加に成功したか、すでに存在していたか)特性を活かすと効率的です。
| 手法 | 計算量 | 特徴 |
|---|---|---|
| Distinct() | O(n) | 簡潔に書けるが遅延評価のコストがある |
| DistinctBy() | O(n) | 特定のキーで簡単にフィルタリング可能 |
| HashSet<T> | O(n) | メモリ効率と速度のバランスが良い。順序は保証されない |
注意点として、HashSetは要素の並び順を保証しません。
元のリストの順序を維持したまま重複を除きたい場合は、LINQのDistinctを使用するか、順序を維持するロジックを別途実装する必要があります。
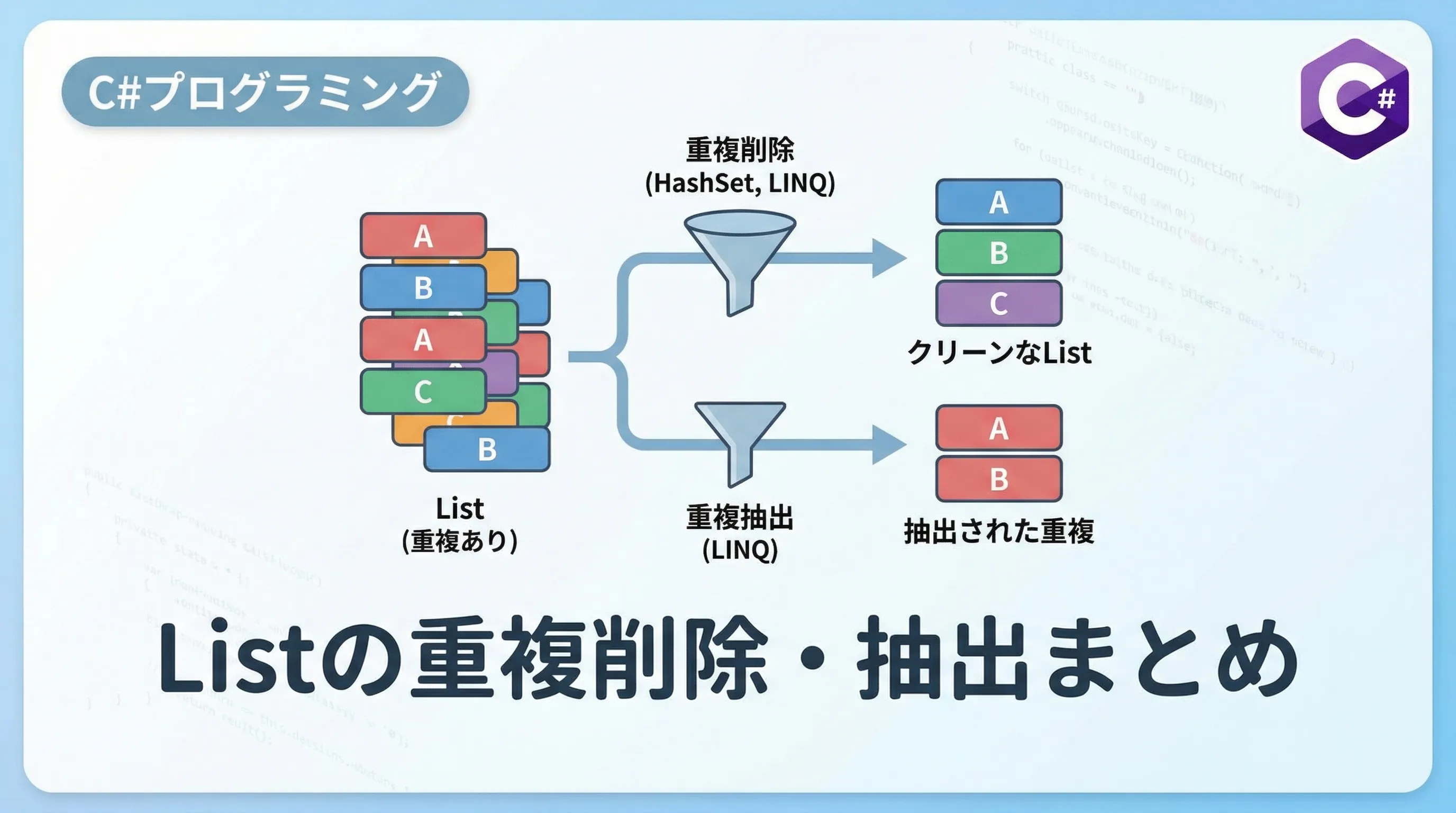
4. リストから重複している要素のみを抽出する
重複を削除するのではなく、「どのデータが重複しているのか」を特定したいケースもあります。
例えば、ユーザー登録時に重複したメールアドレスをエラーとして表示したい場合などです。
4.1 GroupByを使用した重複抽出
重複を抽出するには、GroupByで要素をグループ化し、そのカウントが1より大きいものを選択します。
using System;
using System.Collections.Generic;
using System.Linq;
public class Program
{
public static void Main()
{
List<string> codes = new List<string> { "A101", "B202", "A101", "C303", "B202", "D404" };
// 重複している要素を特定
var duplicates = codes.GroupBy(x => x)
.Where(g => g.Count() > 1)
.Select(g => g.Key)
.ToList();
Console.WriteLine("重複している項目: " + string.Join(", ", duplicates));
}
}重複している項目: A101, B202この手法は非常に汎用的で、オブジェクトに対しても同様に適用可能です。
例えば、社員名簿から同姓同名の人物を探すといった処理も、GroupBy(p => p.Name)とするだけで簡単に実現できます。
5. カスタムオブジェクトでの重複判定(IEqualityComparer)
C#において、自作クラス(参照型)の重複を正しく判定するためには、コンピュータに「何をもって同じとみなすか」を教える必要があります。
これを実現する方法は主に2つあります。
5.1 IEqualityComparer<T>の実装
Distinctメソッドの引数に比較ロジックを渡す方法です。
元のクラスを修正できない場合や、場面によって比較基準を変えたい場合に有効です。
public class Product
{
public string Code { get; set; }
public string Name { get; set; }
}
// 比較用のクラスを定義
public class ProductComparer : IEqualityComparer<Product>
{
public bool Equals(Product x, Product y)
{
if (ReferenceEquals(x, y)) return true;
if (x is null || y is null) return false;
return x.Code == y.Code; // Codeが同じなら同一とみなす
}
public int GetHashCode(Product obj)
{
return obj.Code == null ? 0 : obj.Code.GetHashCode();
}
}この比較用クラスを以下のように使用します。
var uniqueProducts = products.Distinct(new ProductComparer()).ToList();5.2 record型の活用(C# 9.0以降)
現代的なC#開発では、record型の使用が最も推奨されます。
recordは「値ベースの等価性」を標準で備えているため、特別な実装なしでDistinctやHashSetが期待通りに動作します。
public record Member(int Id, string Email);
// 同一の値を持つ別インスタンスでも、重複として正しく処理される
var members = new List<Member>
{
new Member(1, "test@example.com"),
new Member(1, "test@example.com")
};
var distinctMembers = members.Distinct().ToList(); // 1件になるrecord型を採用することで、ボイラープレートコード(定型文)を大幅に削減でき、バグの混入を防ぐことが可能です。
6. まとめ
C#でリストの重複を扱う手法は多岐にわたりますが、状況に応じて最適な選択をすることが重要です。
- 手軽に重複を消したい場合: LINQの
Distinct()を使用。 - 特定のプロパティで判定したい場合: .NET 6以降なら
DistinctBy()を使用。 - 大量のデータを高速に処理したい場合:
HashSet<T>を活用。 - 重複した要素だけを抜き出したい場合:
GroupBy()とWhere()を組み合わせる。 - カスタムオブジェクトを扱う場合:
record型を検討するか、IEqualityComparerを実装する。
特に、最新のC#ではrecord型やDistinctByの登場により、以前よりもはるかに簡潔かつ安全に重複処理を記述できるようになりました。
パフォーマンス、可読性、保守性のバランスを考慮しながら、これらの機能を使い分けていきましょう。