C#は、Microsoftによって開発された強力でモダンなプログラミング言語であり、その設計の根幹には「型安全性」という重要なコンセプトがあります。
私たちが記述するすべての変数や定数、そしてメソッドの戻り値には必ず「データ型」が存在し、これらを正しく理解して使い分けることは、バグの少ない堅牢なアプリケーションを構築するための第一歩です。
本記事では、C#におけるデータ型の全体像を網羅的に解説します。
値型と参照型の根本的な違いから、組み込みの基本型、そしてC#の進化とともに導入された新しい型システムまで、初心者から中級者までが実務で活用できる知識を詳しく紐解いていきましょう。
C#におけるデータ型の分類と基本構造
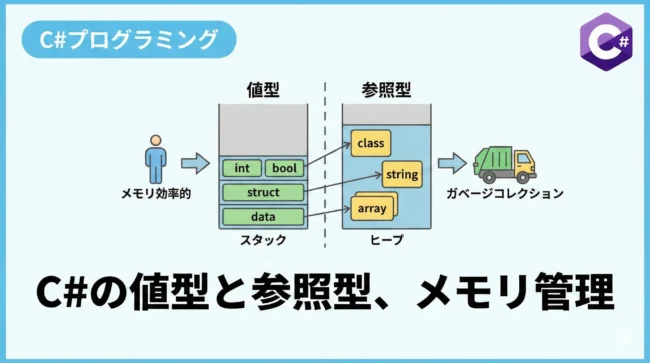
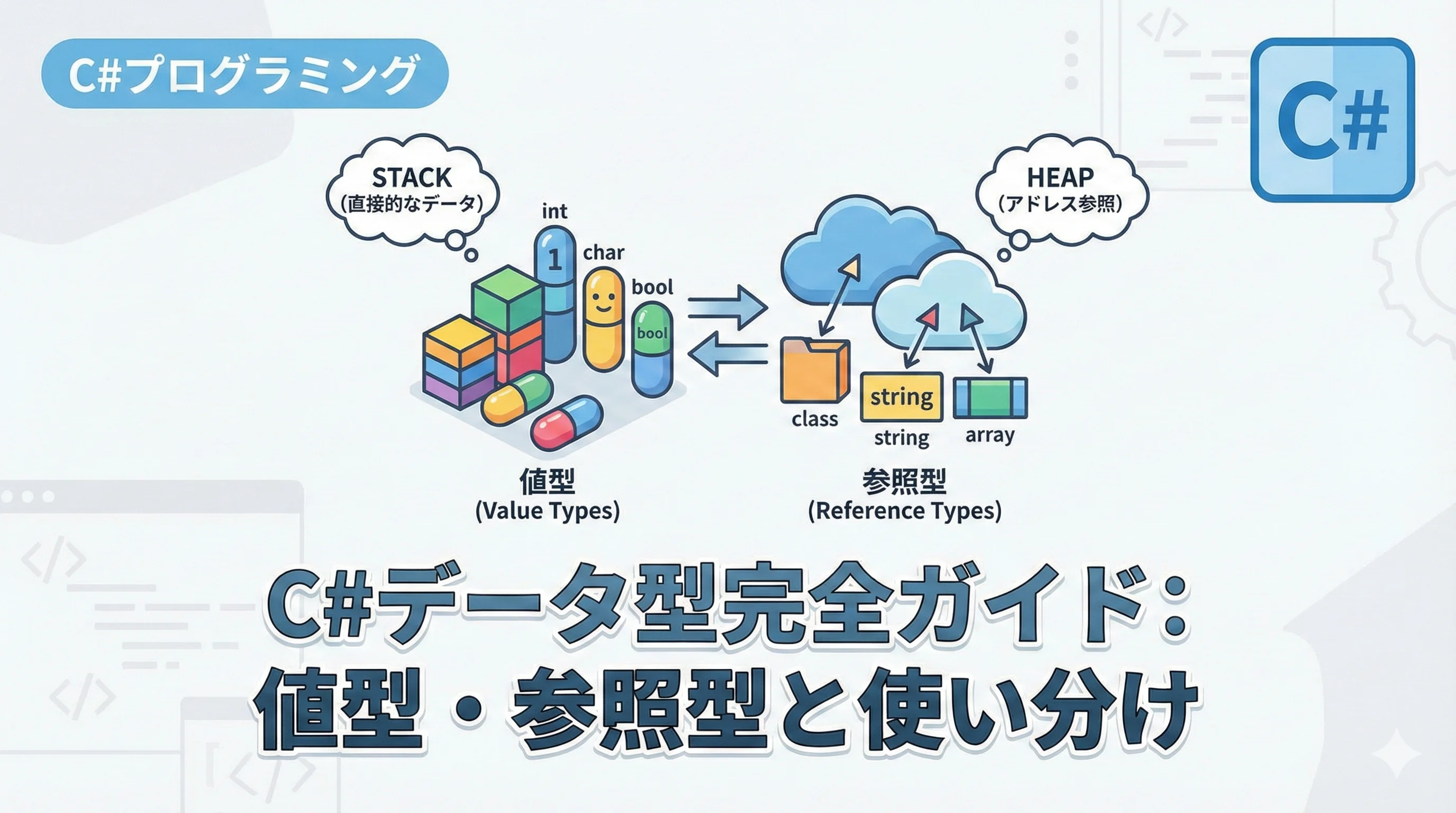
C#のデータ型は、大きく分けて「値型(Value Types)」と「参照型(Reference Types)」の2つのカテゴリーに分類されます。
これらはメモリ上での管理方法やデータのコピーの挙動が全く異なるため、この違いを把握することがC#プログラミングにおいて最も重要です。
C#のすべての型は、最終的には System.Object クラス(キーワードとしての object)から派生しています。
これを「共通型システム(CTS: Common Type System)」と呼び、異なる言語(VB.NETやF#など)との互換性を保つ基盤となっています。
値型と参照型の決定的な違い
値型と参照型の最も大きな違いは、「データがメモリのどこに格納されるか」と「代入時に何がコピーされるか」にあります。
値型は、変数そのものが実際のデータを保持します。
主な格納先はメモリの「スタック領域」です。
一方、参照型は実際のデータ(実体)をメモリの「ヒープ領域」に確保し、変数にはそのデータが存在する場所(アドレス情報)のみを保持します。
| 特徴 | 値型 (Value Type) | 参照型 (Reference Type) |
|---|---|---|
| 格納場所 | 主にスタック領域 | ヒープ領域(変数はアドレスのみ保持) |
| 代入時の挙動 | 値そのものがコピーされる | 参照(アドレス)がコピーされる |
| nullの許容 | 基本的には不可(Nullable型を除く) | 可能 |
| 主な例 | int, bool, struct, enum | string, class, array, delegate |
この違いを意識せずにプログラミングを行うと、意図しないデータの書き換えや、パフォーマンスの低下を招く恐れがあります。
値型の詳細:数値、論理、文字、そして構造体
値型はさらに「組み込み型(プリミティブ型)」と「ユーザー定義型」に分けられます。
これらはメモリ効率が高く、小規模なデータを扱うのに適しています。
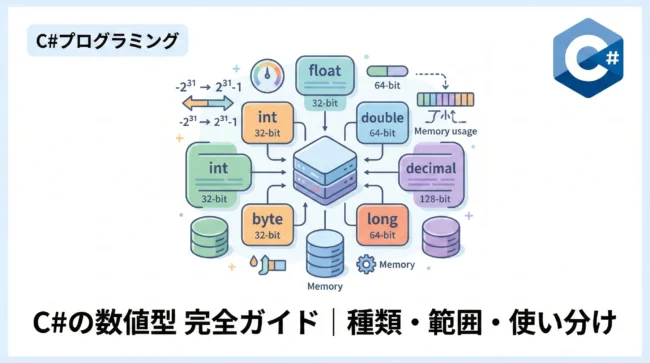
整数型の一覧と選択基準
C#には、扱う数値の大きさに応じて複数の整数型が用意されています。
| 型キーワード | .NET型 | サイズ | 範囲 |
|---|---|---|---|
sbyte | System.SByte | 8ビット | -128 ~ 127 |
byte | System.Byte | 8ビット | 0 ~ 255 |
short | System.Int16 | 16ビット | -32,768 ~ 32,767 |
ushort | System.UInt16 | 16ビット | 0 ~ 65,535 |
int | System.Int32 | 32ビット | 約-21億 ~ 約21億 |
uint | System.UInt32 | 32ビット | 0 ~ 約42億 |
long | System.Int64 | 64ビット | 非常に広範な負数 ~ 正数 |
ulong | System.UInt64 | 64ビット | 0 ~ 非常に広範な正数 |
通常、整数の計算にはint型を使用するのが一般的です。
現代のCPUにおいて最も効率的に処理されるサイズであり、多くのライブラリも int を標準としています。
ただし、巨大なデータを扱う場合や、バイナリデータを直接操作する場合は、long や byte を適切に選択する必要があります。
浮動小数点型と高精度な計算
実数を扱うための型には、float、double、そして decimal があります。
- float (単精度浮動小数点数): 32ビット。精度は低いがメモリ消費が少ない。グラフィックス処理などで使われます。
- double (倍精度浮動小数点数): 64ビット。標準的な実数型。科学技術計算などに適しています。
- decimal (128ビット十進浮動小数点数): 非常に高い精度を持ちますが、処理速度は他の浮動小数点型に比べて低速です。
金融計算(お金の計算)においては、絶対に float や double を使用してはいけません。
これらは2進数で計算を行うため、0.1などの数値を正確に表現できず、丸め誤差が発生します。
お金の計算には、必ずdecimal型を使用してください。
論理型 (bool) と 文字型 (char)
- bool:
trueまたはfalseのいずれかの値を保持します。条件分岐やループの制御に不可欠です。 - char: 1つのUnicode文字を保持します。16ビットのサイズを持ち、
'A'のようにシングルクォーテーションで囲んで記述します。
ユーザー定義の値型:構造体 (struct) と 列挙型 (enum)
C#では、組み込み型以外にも独自の値型を定義できます。
構造体 (struct)
クラスと似ていますが、値型として振る舞います。
軽量なオブジェクトを定義する際に使用されます。
using System;
// 構造体の定義
public struct Point
{
public int X;
public int Y;
public Point(int x, int y)
{
X = x;
Y = y;
}
public void Display()
{
Console.WriteLine($"座標: ({X}, {Y})");
}
}
class Program
{
static void Main()
{
// 値型なのでコピーされる
Point p1 = new Point(10, 20);
Point p2 = p1; // p1の内容がp2にコピーされる
p2.X = 100;
p1.Display(); // 座標: (10, 20)
p2.Display(); // 座標: (100, 20)
}
}座標: (10, 20)
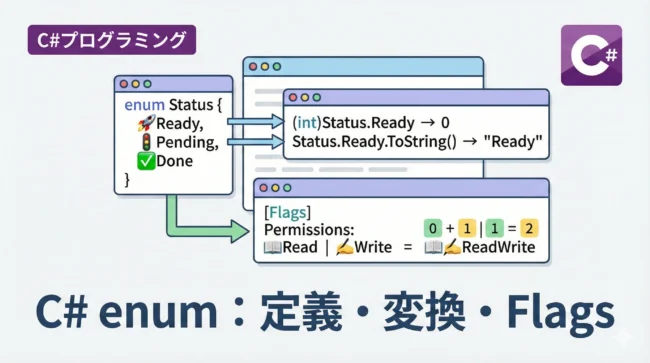
座標: (100, 20)列挙型 (enum)
名前の付いた定数の集合を定義します。
コードの可読性を大幅に向上させます。
public enum DayOfWeek
{
Sunday,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
}参照型の詳細:クラス、配列、そして文字列
参照型は、複雑なデータ構造や大規模なシステムを構築するための主役です。
メモリのヒープ領域を利用するため、柔軟な管理が可能ですが、ガベージコレクション(GC)の対象となる点に注意が必要です。
クラス (class)
C#における最も基本的な参照型です。
データ(フィールド)と振る舞い(メソッド)をカプセル化します。
public class Person
{
public string Name { get; set; }
public void Greet()
{
Console.WriteLine($"こんにちは、{Name}です。");
}
}文字列型 (string)
string は参照型ですが、値型のように直感的に扱える特別な型です。
重要な特徴として「不変性(Immutability)」があります。
一度作成された文字列オブジェクトの内容を変更することはできず、変更を加えるたびに新しい文字列オブジェクトがヒープ上に作成されます。
頻繁に文字列を結合・編集する場合は、パフォーマンス向上のために StringBuilder クラスを利用するのが定石です。
配列 (Array)
同じ型のデータを連続して管理するための型です。
配列そのものが参照型であるため、変数には配列の先頭アドレスが格納されます。
interface, delegate, object
- interface: 実装すべきメソッドの規約を定義します。
- delegate: メソッドを参照するための型(関数ポインタのようなもの)です。
- object: すべての型のルートクラスです。あらゆる値を代入可能ですが、型安全性が失われるため多用は避けるべきです。
メモリ管理と型変換
C#のデータ型を深く理解するためには、メモリ上での動きと、型同士の変換についても知っておく必要があります。
ボックス化とボックス化解除 (Boxing / Unboxing)
値型を object 型などの参照型に変換することを「ボックス化」と呼びます。
逆に、参照型から値型へ戻すことを「ボックス化解除」と呼びます。
ボックス化は、ヒープ領域へのメモリ割り当てが発生するため、大量に行うとパフォーマンスを著しく低下させます。
現代のC#では「ジェネリクス」を使用することで、このボックス化を回避するのが一般的です。
int i = 123;
object o = i; // ボックス化(ヒープにコピーされる)
int j = (int)o; // ボックス化解除暗黙的な変換と明示的な変換(キャスト)
データ型の間で値を移動させる際、情報が失われるリスクがない場合は「暗黙的な変換」が行われます(例:int から long)。
一方、情報の欠落の可能性がある場合は「明示的なキャスト」が必要です。
double d = 123.45;
int i = (int)d; // 小数点以下が切り捨てられるため、明示的なキャストが必要近代的なC#の型:RecordとNullable
C#は進化を続けており、データ管理をより簡潔かつ安全に行うための新しい型が追加されています。
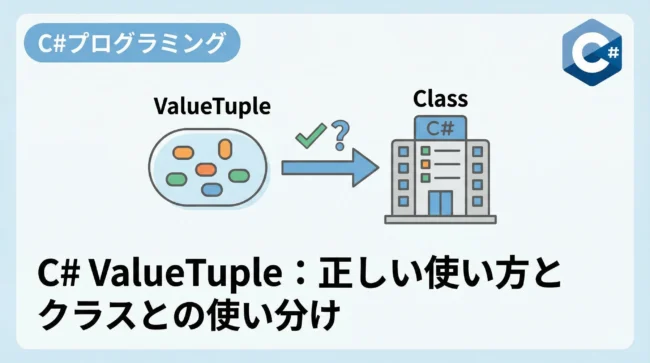
レコード型 (record)
C# 9.0で導入されたレコード型は、「データ中心」の設計に適した型です。
参照型でありながら、値ベースの比較(プロパティの内容が同じなら等しいとみなす)を自動的にサポートします。
// 簡潔な定義(プライマリコンストラクタ)
public record User(string Name, int Age);
var u1 = new User("田中", 25);
var u2 = new User("田中", 25);
Console.WriteLine(u1 == u2); // True (参照が違っても内容が同じならTrue)また、record struct を使用することで、値型としてのレコードを定義することも可能です。
null許容参照型 (Nullable Reference Types)
現代のC#では、参照型でも「nullを許容するかどうか」を明示的に区別する設定が推奨されています。
string: nullを許容しない(デフォルトの設定による)string?: nullを許容する
これにより、開発時の NullReferenceException を劇的に減らすことができます。
データ型の選び方:ベストプラクティス
多くの型がある中で、どのように最適なものを選べばよいでしょうか。
以下の指針を参考にしてください。
- 整数を扱う場合: 基本は
int。21億を超える可能性があるならlong。 - 小数を扱う場合: 通常は
double。ただし、金融・会計関連は必ずdecimal。 - 小さなデータ構造を定義する場合: 変更不要(イミュータブル)で、サイズが小さい(約16〜32バイト以下)なら
structまたはrecord struct。 - 一般的なオブジェクト: 迷わず
class。データの保持が目的ならrecord。 - 真偽値:
boolを使用。0/1で代用しない。 - 文字列操作: 結合が多い場合は
StringBuilderを活用。
補足:動的型付けと型推論
C#は静的型付け言語ですが、利便性のために以下の機能も提供しています。
var キーワード (型推論)
右辺から型が明らかな場合、型名を省略できます。
これは「型が決まっていない」のではなく、コンパイラが自動的に型を決定してくれる機能です。
var message = "Hello World"; // コンパイラが string と判断する
var list = new List<string>(); // 長い型名を省略できて便利dynamic 型
実行時に型が決定される特殊な型です。
型チェックがコンパイル時に行われないため、COM操作や動的言語との連携など、特定の場面以外での使用は推奨されません。
まとめ
C#のデータ型は、単なるデータの入れ物ではなく、「どのようにメモリを使い、どのように動作するか」を決定する設計図です。
- 値型はスタックに格納され、コピーによってデータが渡される。
- 参照型はヒープに格納され、アドレス(参照)によってデータが共有される。
- decimal は精度が求められる金融計算に必須。
- record や Nullable型 などの最新機能を活用して、より安全なコードを書く。
これらの特性を正しく理解し、適切な型を選択できるようになることで、プログラムのパフォーマンスは向上し、予期せぬ挙動に悩まされることも少なくなります。
データ型の習得は、C#マスターへの確かな一歩となるでしょう。