C#という言語を深く理解し、高品質なプログラムを構築するためには、「参照型(Reference Types)」の仕組みを正しく把握することが欠かせません。
C#の型システムは大きく分けて「値型」と「参照型」の2つに分類されますが、これらはメモリ上での扱いやデータの受け渡し方法が根本的に異なります。
特に、大規模なアプリケーションの開発やパフォーマンス最適化が必要な場面では、参照型がどのようにメモリを消費し、ガベージコレクション(GC)とどのように関わるのかを知っておくことが、実行効率の向上や予期せぬバグの回避に直結します。
本記事では、C#における参照型の定義から、値型との決定的な違い、メモリ管理の内部構造、そして最新のC#におけるベストプラクティスまでを網羅的に解説します。
C#における参照型の基本概念
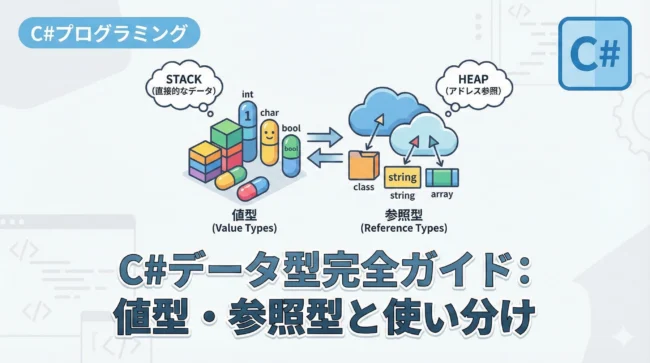
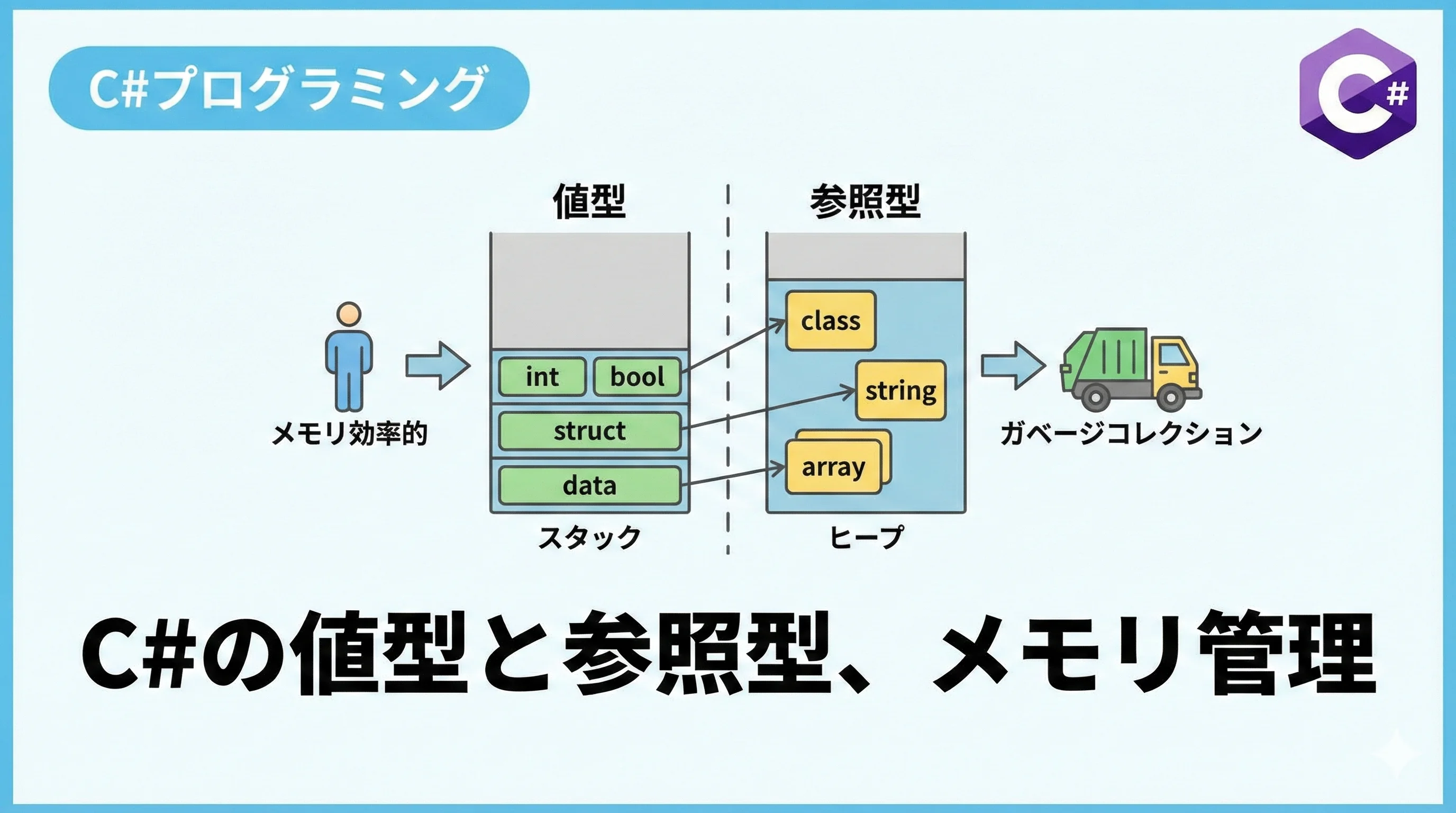
C#の参照型とは、データそのものを変数に格納するのではなく、データが格納されているメモリ上の場所(アドレス)を保持する型のことです。
この仕組みを理解するために、まずは参照型の基本的な性質について詳しく見ていきましょう。
参照型とは何か
値型(intやboolなど)が変数の宣言場所に直接値を書き込むのに対し、参照型は実際のデータ本体を「ヒープ」と呼ばれるメモリ領域に配置し、変数にはそのヒープへの「ポインタ(参照)」を格納します。
例えば、クラスのインスタンスを生成する場合を考えてみます。
// クラス(参照型)の定義
public class User
{
public string Name { get; set; }
}
// インスタンスの生成
User user1 = new User();
user1.Name = "田中";このコードにおいて、user1という変数自体には「田中」という文字列やUserオブジェクトのデータそのものは入っていません。
変数user1に格納されているのは、「ヒープ領域のどこにUserオブジェクトが存在するか」を示すメモリ番地です。
参照型の主な種類
C#には多種多様な参照型が存在します。
主要なものは以下の通りです。
- クラス (class)
最も一般的な 参照型。
インスタンスを生成してフィールド・メソッド・プロパティ・コンストラクタ・継承などを持てる。
定義は
classを使い、オブジェクト指向の基本単位として利用される。- インターフェース (interface)
実装を持たない定義で、メソッドシグネチャやプロパティの契約だけを定義する(実装は提供しない)。
クラスや構造体がこれを実装して振る舞いを提供する。
定義は
interface。- デリゲート (delegate)
特定のシグネチャを持つメソッドへの参照を表す型。
関数ポインタのようにメソッドを格納・渡用・呼び出しでき、イベント処理によく使われる。
定義は
delegate。- 配列 (array)
同じ型の要素の集合体。
要素が値型であっても配列自体は 参照型 であり、参照を通じて共有される。
長さは基本的に固定(可変長は別のコレクションを使用)。
表記例:
T[]。- string
文字列型。
一般にイミュータブル(不変)で、特殊な最適化や操作が用意されているため言語上で特別扱いされる参照型。
型名は
string(C# 等)。- object
すべての型のルートとなる基底クラス。
任意の型を格納でき、共通の操作(例:
ToString,GetHashCode)が定義されている。- dynamic
実行時に型が決まる特殊な参照型。
コンパイル時の型チェックを行わず、実行時バインディングでメンバアクセスが解決されるため柔軟だがランタイムエラーのリスクがある。
型名は
dynamic。
これらの型はすべて、後述する「ヒープ領域」に実体が作成され、ガベージコレクタによって管理されます。
参照型と値型の決定的な違い
C#を学ぶ上で最も混乱しやすいのが、値型と参照型の動作の違いです。
これらを正しく使い分けるためには、「代入」と「引数の受け渡し」における挙動の差を理解する必要があります。
メモリ配置の場所(スタック vs ヒープ)
コンピュータのメモリには「スタック」と「ヒープ」という2つの主要な領域があります。
| 特徴 | 値型 (Value Type) | 参照型 (Reference Type) |
|---|---|---|
| 格納場所 | スタック領域 | ヒープ領域 |
| 参照方法 | 直接アクセス | 参照(アドレス)経由でアクセス |
| 生存期間 | 定義されたスコープを抜けるまで | ガベージコレクタが不要と判断するまで |
| メモリ解放 | 高速(自動的) | ガベージコレクション(GC)による負荷あり |
代入時の挙動
値型を別の変数に代入すると、データの「コピー」が作成されます。
一方、参照型を代入すると、データの場所を示す「参照(アドレス)」だけがコピーされます。
以下のコードで、その違いを確認してみましょう。
using System;
public class Program
{
// 参照型の定義
public class Person { public int Age; }
public static void Main()
{
// --- 値型の挙動 ---
int a = 10;
int b = a; // aの値がコピーされる
b = 20; // bを変更してもaには影響しない
Console.WriteLine($"値型: a={a}, b={b}");
// --- 参照型の挙動 ---
Person p1 = new Person { Age = 10 };
Person p2 = p1; // p1の「参照(アドレス)」がコピーされる
p2.Age = 20; // p2を通じてヒープ上の実体を変更すると、p1も影響を受ける
Console.WriteLine($"参照型: p1.Age={p1.Age}, p2.Age={p2.Age}");
}
}値型: a=10, b=20
参照型: p1.Age=20, p2.Age=20この結果からわかる通り、参照型では複数の変数が同じ実体を指し示すことができるため、意図しないデータの書き換え(副作用)に注意が必要です。
参照型のメモリ管理:ヒープとGCの仕組み
参照型を理解する上で避けて通れないのが、「ガベージコレクション(Garbage Collection, GC)」の存在です。
C#において参照型のオブジェクトがどのように生成され、どのように消滅するのか、そのライフサイクルを探ります。
ヒープ領域への割り当て
newキーワードを使用して参照型のインスタンスを作成すると、ランタイム(CLR)はマネージド・ヒープと呼ばれるメモリ領域から必要なサイズを確保します。
このとき、オブジェクトにはデータ本体だけでなく、型情報へのポインタ(Type Object Pointer)や同期ブロックインデックスなどの「オーバーヘッド情報」も付加されます。
ガベージコレクションの役割
スタック領域にある値型は、メソッドの実行が終われば即座にメモリから消去されますが、ヒープ領域にある参照型は即座には消えません。
誰からも参照されなくなった(=どの変数もそのアドレスを保持しなくなった)タイミングで、ガベージコレクタが定期的にメモリをスキャンし、不要になったオブジェクトを回収します。
GCの主なステップは以下の通りです。
- マーキング: ルート(静的変数、スタック上の変数など)から辿れるオブジェクトに印を付ける。
- スイープ: 印が付かなかった(参照されていない)オブジェクトをメモリから解放する。
- コンパクション: メモリの断片化を防ぐため、生き残ったオブジェクトを詰めて配置し直す。
世代別管理(Generation)
C#のGCは効率化のために「世代」という概念を持っています。
- 第0世代: 生成されたばかりの新しいオブジェクト。頻繁に回収される。
- 第1世代: 第0世代の回収を生き延びたオブジェクト。
- 第2世代: 長期間生存しているオブジェクト(静的変数やアプリケーションの寿命に近いもの)。
参照型を多用しすぎると、このGCの負荷が高まり、アプリケーションの一時的な停止(Stop The World)を招く原因となるため、パフォーマンスが重要な場面では参照型の生成頻度を抑える工夫が求められます。
C#における主要な参照型の詳細
ここでは、実務で頻繁に使用する代表的な参照型について、それぞれの特徴と注意点を詳しく解説します。
1. クラス (class)
C#における参照型の代表格です。
データと振る舞い(メソッド)をカプセル化し、継承やポリモーフィズムといったオブジェクト指向の機能をフルに活用できます。
2. string型
stringは参照型ですが、他の参照型とは異なる「不変性(Immutability)」という特徴を持ちます。
一度作成された文字列オブジェクトの内容を書き換えることはできません。
文字列を変更する操作(連結など)を行うと、実際にはヒープ上に新しい文字列オブジェクトが作成されます。
string s1 = "Hello";
s1 += " World"; // 新しい文字列オブジェクトが生成され、s1の参照先が切り替わる大量の文字列連結を行う場合に StringBuilder クラスが推奨されるのは、この参照型の生成(およびGC負荷)を抑えるためです。
3. 配列 (Array)
配列は、要素が値型であっても、配列自体は必ず参照型となります。
int[] numbers = new int[5]; // numbers自体は参照型このため、メソッドの引数に配列を渡すと、配列の中身がコピーされるのではなく、配列への参照が渡されます。
メソッド内で配列の要素を書き換えると、呼び出し元の配列も書き換わる点に注意してください。
4. object型
すべての型の究極の基底クラスです。
値型であっても参照型であっても、最終的には object 型に代入することができます。
ただし、値型を object 型(参照型)に変換することを「ボックス化(Boxing)」と呼び、ヒープへのメモリ割り当てが発生するため、パフォーマンス上のオーバーヘッドが生じます。
参照型とNull(ヌル)の扱い
参照型の最大の特徴であり、同時に最大の課題でもあるのが「null(何も参照していない状態)」を許容することです。
NullReferenceException のリスク
参照型の変数に null が代入されている状態で、そのメンバにアクセスしようとすると、悪名高い NullReferenceException が発生します。
User user = null;
// Console.WriteLine(user.Name); // ここで例外が発生してプログラムが停止する現代的な解決策:Null許容参照型
C# 8.0以降、「Nullable Reference Types(null許容参照型)」という機能が導入されました。
これにより、参照型であっても「nullになる可能性があるかどうか」をコンパイラに伝えることができるようになりました。
string: nullを許容しない(デフォルトの設定による)string?: nullを許容する
#nullable enable
string name = null; // 警告:非null型の変数にnullを代入しようとしています
string? nullableName = null; // OK
#nullable disableこの機能を活用することで、実行時ではなくビルド時に潜在的なnull参照バグを見つけ出すことが可能になります。
参照型をいつ使うべきか:値型との使い分け指針
開発において、自作の型を class(参照型)にするか struct(値型)にするかは非常に重要な判断です。
以下のガイドラインを参考にしてください。
参照型 (class) を選ぶべきケース
- オブジェクトのサイズが大きい場合: 値型は代入のたびに全データがコピーされるため、大きな構造体はパフォーマンスを悪化させます。
- 状態を共有したい場合: 複数の場所から同じインスタンスを操作し、変更を同期させる必要がある場合。
- 継承を利用したい場合: 基底クラスを作ったり、多態性(ポリモーフィズム)を利用したりする場合。
- 寿命を管理したい場合: メソッドを抜けた後もデータを保持し続け、複数のクラス間で受け渡したい場合。
値型 (struct) を検討すべきケース
- データサイズが小さい(目安として16バイト以下): 座標(Point)、色(Color)、複素数などの単純なデータ構造。
- 不変(Immutable)なデータ: 作成後に値が変わることがないデータ。
- 大量のインスタンスを生成する場合: 数万個のオブジェクトを生成する場合、ヒープへの割り当てとGCの負荷を避けるために値型が有利になることがあります。
実践的なコード例:参照型の性質を利用したプログラミング
参照型の性質を活かした、実践的なコード例を紹介します。
ここでは「参照渡し」の効果を確認します。
using System;
public class Product
{
public string Name { get; set; }
public int Price { get; set; }
}
public class Program
{
public static void Main()
{
Product laptop = new Product { Name = "ノートPC", Price = 100000 };
Console.WriteLine($"適用前: {laptop.Name} - {laptop.Price}円");
// 参照型のオブジェクトをメソッドに渡す
ApplyDiscount(laptop);
// メソッド内での変更が、呼び出し元のオブジェクトにも反映されている
Console.WriteLine($"適用後: {laptop.Name} - {laptop.Price}円");
}
public static void ApplyDiscount(Product product)
{
// productは呼び出し元のlaptopと同じヒープ上の実体を参照している
if (product.Price >= 50000)
{
product.Price -= 10000; // 1万円引き
Console.WriteLine("--- 割引を適用しました ---");
}
}
}適用前: ノートPC - 100000円
--- 割引を適用しました ---
適用後: ノートPC - 90000円このように、参照型を使用することで、メソッド間でオブジェクトの状態を効率よく共有・更新することができます。
一方で、不用意に値を書き換えてしまうリスクもあるため、意図しない変更を防ぎたい場合は「読み取り専用(readonly)」の活用や、新しいインスタンスを返却する設計を検討することがプロのテクニックです。
パフォーマンスへの影響と最適化のヒント
参照型は非常に便利ですが、乱用するとアプリケーションの動作が重くなる原因になります。
以下の点に留意して最適化を図りましょう。
1. アロケーション(割り当て)の抑制
ループの中で頻繁に new を行うと、短寿命なオブジェクトが大量に生成され、第0世代GCが頻発します。
オブジェクトプールなどを利用して、一度作ったインスタンスを再利用する手法が有効です。
2. キャッシュ局所性の意識
参照型はヒープ上のあちこちにデータが散らばるため、CPUキャッシュのヒット率が低下しやすくなります。
データ集約的な処理を行う場合、あえて値型の配列(スタックに近いメモリ配置)を使用することで劇的に高速化できるケースがあります。
3. string型の最適化
前述の通り、文字列操作はアロケーションの温床です。
C#の最新機能である Span<T> や Memory<T> を活用することで、文字列のコピーを発生させずに部分文字列を扱うといった、高度なメモリ最適化が可能になります。
まとめ
C#の参照型は、現代的なアプリケーション開発における柔軟性と表現力の源泉です。
その本質は「データそのものではなく、データの場所を管理する」という点にあり、この特性を理解することで、メモリ効率の良い、バグの少ないコードが書けるようになります。
本記事のポイントを振り返ります:
- 参照型はヒープ領域に実体を持ち、変数にはそのアドレスが格納される。
- 代入や引数渡しでは「参照(コピーされたアドレス)」が渡されるため、同じ実体を共有できる。
- 不要になった参照型はガベージコレクタ(GC)によって自動的に回収される。
- nullを許容するため、NullReferenceExceptionへの対策(null許容参照型の活用など)が不可欠である。
- クラス、文字列、配列、インターフェースなどが代表的な参照型である。
値型との違いを明確に意識し、適切に使い分けることは、C#エンジニアとしてステップアップするための重要なマイルストーンです。
メモリの裏側で何が起きているのかを想像しながらコーディングする習慣をつけることで、より堅牢でスケーラブルなシステムを構築できるでしょう。