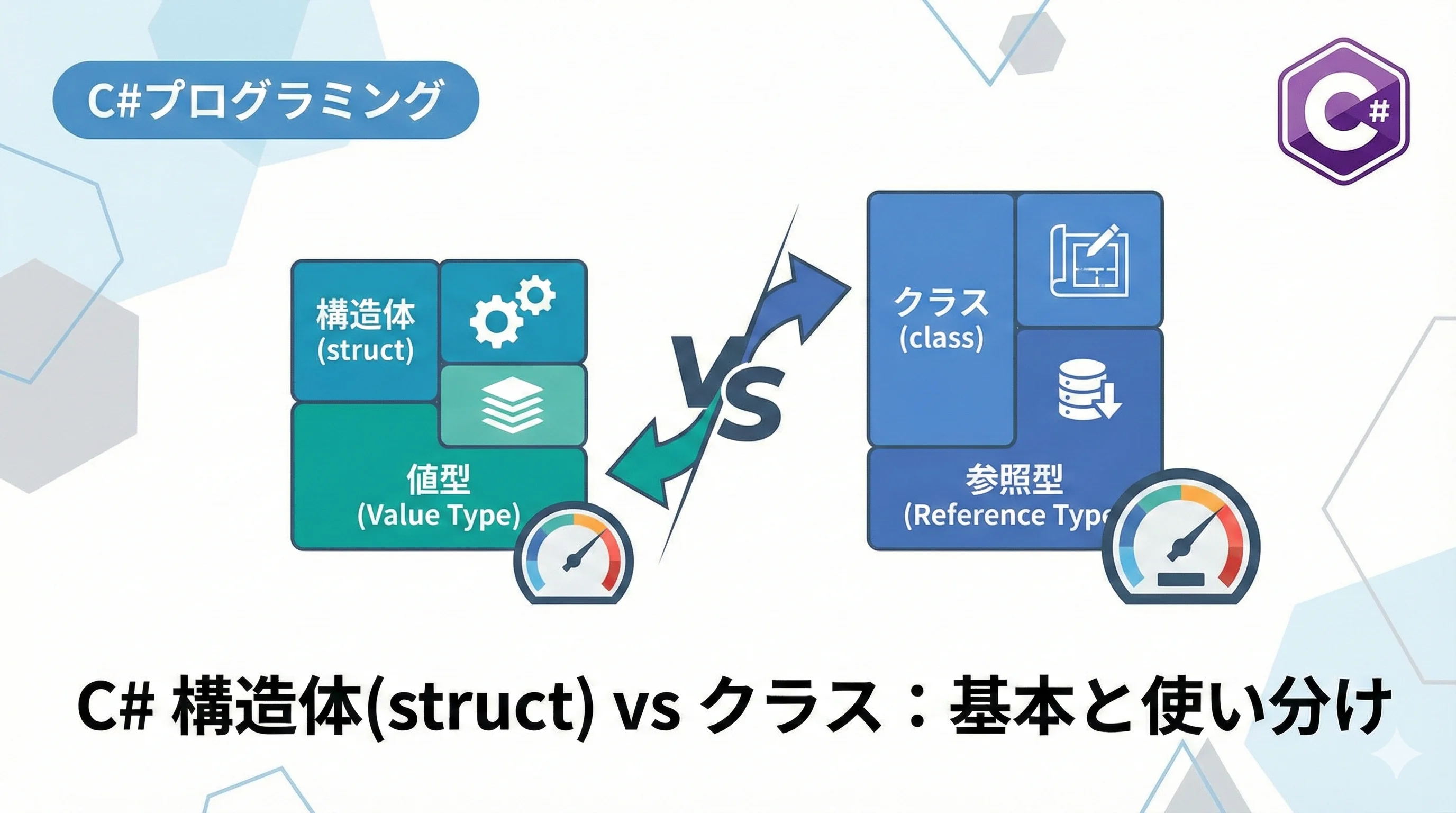
C#において、データの保持や操作を行うための主要な手段として「クラス(class)」と「構造体(struct)」があります。
多くの開発者がクラスを多用する傾向にありますが、パフォーマンスの最適化やメモリ管理の効率化を追求する上で、構造体の正しい理解は欠かせません。
構造体は単なる「小さなクラス」ではなく、メモリ上での振る舞いやライフサイクルが根本的に異なります。
本記事では、構造体の基本概念からクラスとの詳細な比較、さらには現代的なC#開発における高度な活用方法までを網羅的に解説します。
構造体(struct)の基本概念
C#における構造体は、値型(Value Type)として定義されるデータ構造です。
クラスが参照型であるのに対し、構造体はデータそのものをスタック領域や親オブジェクトのメモリ内に直接保持します。
これにより、メモリの割り当てと解放にかかるオーバーヘッドを最小限に抑えることが可能です。
構造体の定義方法
構造体の定義はクラスと非常に似ていますが、structキーワードを使用します。
以下のコードは、二次元座標を表す単純な構造体の例です。
using System;
namespace StructExample
{
// 構造体の定義
public struct Point
{
// フィールド
public int X;
public int Y;
// コンストラクタ
public Point(int x, int y)
{
X = x;
Y = y;
}
// メソッド
public void Display()
{
Console.WriteLine($"X: {X}, Y: {Y}");
}
}
class Program
{
static void Main()
{
// インスタンス化
Point p1 = new Point(10, 20);
p1.Display();
// newを使用しない初期化も可能(ただし全フィールドの初期化が必要)
Point p2;
p2.X = 30;
p2.Y = 40;
p2.Display();
}
}
}X: 10, Y: 20
X: 30, Y: 40構造体の主な特徴
構造体には、クラスとは異なるいくつかの制約と特徴があります。
- 継承の禁止:構造体は他のクラスや構造体を継承することはできず、また他のクラスの基底になることもできません(ただし、インターフェースの実装は可能です)。
- 既定のコンストラクタ:C# 10以前では引数なしのコンストラクタを明示的に定義できませんでしたが、最新のC#では定義が可能になっています。
- 値のコピー:変数に代入したり引数として渡したりする際、参照ではなく「データそのもの」がコピーされます。
クラス(class)と構造体(struct)の決定的な違い
構造体とクラスの最大の違いは、「メモリ上での管理方法(値型か参照型か)」にあります。
この違いを理解することが、適切な設計を行うための第一歩となります。
メモリ配置:スタックとヒープ
クラスのインスタンスはManaged Heap(マネージドヒープ)に配置され、変数にはそのメモリ番地(参照)が格納されます。
一方、構造体は通常Stack(スタック)に配置されるか、あるいは別のクラスのフィールドとして定義されている場合はそのクラスの一部としてヒープ内に配置されます。
スタックは非常に高速にアクセス可能で、スコープを抜けると即座にメモリが解放されるため、ガベージコレクション(GC)の負荷を軽減できるという利点があります。
代入時の挙動
以下のコードで、クラスと構造体の代入時の挙動の差を確認してみましょう。
using System;
public class ClassPoint { public int X; }
public struct StructPoint { public int X; }
class Program
{
static void Main()
{
// クラスの場合(参照のコピー)
ClassPoint c1 = new ClassPoint { X = 10 };
ClassPoint c2 = c1;
c2.X = 99;
Console.WriteLine($"Class c1.X: {c1.X}"); // c1も変更される
// 構造体の場合(値のコピー)
StructPoint s1 = new StructPoint { X = 10 };
StructPoint s2 = s1;
s2.X = 99;
Console.WriteLine($"Struct s1.X: {s1.X}"); // s1は変更されない
}
}Class c1.X: 99
Struct s1.X: 10クラスでは c2 = c1 とした際に「同じ場所」を指すようになりますが、構造体では s2 = s1 とした瞬間に中身の全データが新しいメモリ領域に複製されます。
そのため、s2 を書き換えても s1 には影響しません。
比較表:クラス vs 構造体
| 特徴 | クラス (class) | 構造体 (struct) |
|---|---|---|
| 型の種類 | 参照型 | 値型 |
| メモリ割り当て | ヒープ領域 | スタック領域(原則) |
| 継承 | 可能 | 不可(インターフェースのみ可) |
| 既定値 | null | 各フィールドの初期値(0など) |
| メモリ解放 | GCによる回収 | スコープ終了時に即座に解放 |
| パフォーマンス | オブジェクト生成にコストがかかる | 小さなデータなら非常に高速 |
構造体のパフォーマンス設計と注意点
構造体は高速であると言われますが、誤った使い方をすると逆にパフォーマンスを著しく低下させる原因となります。
ここでは、構造体を設計する際に考慮すべき重要なポイントを解説します。
ボクシング(Boxing)とアンボクシング
構造体を object 型やインターフェース型の変数に代入すると、ボクシングと呼ばれる現象が発生します。
これは、値型のデータをヒープ領域にラップして参照型として扱う処理です。
int i = 123;
object obj = i; // ボクシング発生(ヒープ割り当てが発生)ボクシングが発生すると、構造体の利点である「スタック利用による高速化」が失われ、GCの対象となってしまいます。
大量のデータを処理するループ内で意図せずボクシングが発生していないか注意が必要です。
コピーコストの増大
構造体は代入や引数の受け渡しのたびに全データがコピーされます。
そのため、サイズが大きすぎる構造体はコピーのオーバーヘッドが無視できなくなります。
Microsoftのガイドラインでは、構造体のサイズは一般的に16バイト以下に抑えることが推奨されています。
これを超える場合は、クラスの使用を検討するか、後述する参照渡しの活用を検討すべきです。
参照渡し(ref, in, out)による最適化
大きな構造体をコピーせずに渡したい場合は、引数に ref や in キーワードを使用します。
特に in 修飾子は「読み取り専用の参照渡し」を意味し、コピーを防ぎつつ安全にデータを渡すことができます。
// 大きな構造体
public struct LargeStruct
{
public decimal V1, V2, V3, V4; // 64バイト
}
// in修飾子でコピーを防止
public void ProcessData(in LargeStruct data)
{
// data.V1 = 10; // コンパイルエラー(読み取り専用)
Console.WriteLine(data.V1);
}現代的なC#における高度な構造体
C# 7.0以降、パフォーマンスを極限まで高めるための新しい構造体の機能が次々と追加されました。
これらを活用することで、低レイヤーな制御を安全に行うことができます。
readonly struct(不変構造体)
構造体は不変(Immutable)であることが推奨されます。
readonly struct と宣言することで、その構造体のフィールドがすべて読み取り専用であることをコンパイラが保証します。
public readonly struct ReadOnlyPoint
{
public double X { get; }
public double Y { get; }
public ReadOnlyPoint(double x, double y) => (X, Y) = (x, y);
}不変にすることで、予期せぬ副作用を防ぐだけでなく、コンパイラによる最適化(不要なコピーの削減など)が効きやすくなるメリットがあります。
ref struct
ref struct は、常にスタック上に配置されることを強制する特殊な構造体です。
ヒープへの割り当てが一切禁止されるため、Span<T> などの高効率なメモリ操作を実現するために使われます。
ただし、フィールドとして持てない、非同期メソッド(async)で使用できないといった強力な制約があります。
record struct
C# 10で導入された record struct は、データの保持に特化した構造体です。
public record struct Person(string Name, int Age);これだけで、値に基づいた等価性比較(Equals)や、プロパティの非破壊的変更(with式)が自動的に実装されます。
DTO(Data Transfer Object)のような軽量なデータ保持クラスを構造体で実現したい場合に最適です。
構造体を採用すべき判断基準
「いつ構造体を使うべきか」という問いに対しては、以下のチェックリストが指針となります。
構造体が適しているケース
- 論理的に単一の値を表す(例:複素数、座標、色、金額など)。
- インスタンスのサイズが小さい(16バイト程度が目安)。
- 不変(Immutable)である。
- 大量に生成され、GCの負荷が懸念される。
- 他のオブジェクトから頻繁に参照されない(独立したデータである)。
クラスが適しているケース
- データのサイズが大きい。
- 継承を利用したポリモーフィズムが必要。
- インスタンスの状態が頻繁に変化する。
- ライフサイクルを細かく制御する必要がある。
- 参照の同一性が重要である(「同じ中身」ではなく「同じモノ」である必要がある場合)。
実践例:ゲーム開発や数値計算での活用
構造体が最も真価を発揮するのは、数万から数百万のパーティクルを処理するゲームエンジンや、大量の行列演算を行う数値計算ライブラリです。
using System;
using System.Diagnostics;
public struct Vector3
{
public float X, Y, Z;
public Vector3(float x, float y, float z) => (X, Y, Z) = (x, y, z);
public static Vector3 operator +(Vector3 a, Vector3 b)
=> new Vector3(a.X + b.X, a.Y + b.Y, a.Z + b.Z);
}
class Program
{
static void Main()
{
const int count = 10_000_000;
Vector3[] particles = new Vector3[count];
Vector3 gravity = new Vector3(0, -9.8f, 0);
Stopwatch sw = Stopwatch.StartNew();
for (int i = 0; i < count; i++)
{
particles[i] = particles[i] + gravity;
}
sw.Stop();
Console.WriteLine($"1000万個の演算にかかった時間: {sw.ElapsedMilliseconds} ms");
}
}この例では、1000万個のベクトル演算を行っていますが、構造体配列として確保することでメモリは連続した領域に配置されます。
これにより、CPUキャッシュのヒット率が向上し、クラスの配列(参照の配列)を使用した場合と比べて圧倒的な実行速度を実現できます。
まとめ
C#の構造体は、適切に使用することでアプリケーションのパフォーマンスを飛躍的に向上させる強力なツールです。
クラスとの最大の違いである「値型としての性質」を理解し、メモリ配置やコピーコストを意識した設計を行うことが、プロフェッショナルなC#開発者への近道となります。
今回のポイントを振り返ると、構造体は「小さく、不変で、頻繁に生成・破棄されるデータ」に最適です。
一方で、継承が必要な場合や大きなデータを扱う場合はクラスを選択すべきです。
また、現代的なC#では readonly struct や record struct などの便利な機能も揃っています。
これからは、単に「データをまとめたいからクラスを作る」のではなく、「このデータのライフサイクルとメモリ効率はどうあるべきか」を考え、構造体という選択肢を積極的に検討してみてください。
適切な使い分けこそが、堅牢で高効率なシステムを構築するための鍵となります。