Javaアプリケーションの開発において、ログ出力はシステムの動作状況を把握し、トラブルシューティングを迅速に行うための極めて重要な要素です。
開発初期段階では System.out.println を利用してデバッグを行うこともありますが、商用環境での運用を想定した場合、出力先の切り替え、ログレベルの制御、パフォーマンスの最適化などが求められます。
現在、Javaのエコシステムでは、抽象化レイヤーである SLF4J と、その実装体である Logback や Log4j 2 を組み合わせる手法が標準となっています。
本記事では、これらのライブラリの比較から具体的な導入方法、運用におけるベストプラクティスまでを詳しく解説します。
Javaにおけるログ出力の基本構成
Javaのログ出力ライブラリを理解する上で最も重要な概念は、「ロギング・ファサード」と「ロギング・フレームワーク(実装体)」の分離です。
かつてのJava開発では、特定のログライブラリを直接コード内で呼び出していましたが、これではライブラリを移行する際にすべてのソースコードを書き直す必要がありました。
この問題を解決するために登場したのが、インターフェースのみを提供するファサードです。
ロギング・ファサードの役割
ロギング・ファサードは、アプリケーションコードと実際のログ出力処理の間に立ち、共通のAPIを提供します。
代表的なものに SLF4J (Simple Logging Facade for Java) があります。
開発者は SLF4J のメソッドを呼び出すだけでよく、背後で動く具体的なライブラリが何であるかを意識する必要がありません。
ロギング・フレームワーク(実装体)の役割
実際にログをファイルに書き込んだり、コンソールに表示したりする処理を担うのが実装体です。
代表的なものには以下の3つがあります。
- Logback
SLF4J の開発者によって作られた、Log4j の後継となるライブラリです。
Spring Boot のデフォルトとして採用されています。
- Log4j 2
Apache ソフトウェア財団によって開発されている高機能なライブラリです。
LMAX Disruptorを利用した非同期ログ出力による圧倒的なパフォーマンスが特徴です。- java.util.logging (JUL)
Java 標準のログ機能ですが、柔軟性やパフォーマンスの観点から、サードパーティ製のライブラリが好まれる傾向にあります。
SLF4J:デファクトスタンダードの抽象化レイヤー
現代のJava開発で SLF4J を使用しない理由はほとんどありません。
SLF4J を導入することで、ライブラリの依存関係に起因するログの競合問題を回避し、柔軟な設計が可能になります。
SLF4J の主なメリット
SLF4J を利用する最大のメリットは、「プレースホルダ機能」によるパフォーマンス向上です。
従来の方式では、ログレベルを判定する前に文字列の結合が行われ、無駄なメモリ消費が発生することがありました。
// 従来の方式(ログレベルがINFOでも、文字列結合が実行されてしまう)
logger.debug("ユーザーID: " + userId + " がログインしました。");
// SLF4J の方式(DEBUGレベルでない場合、結合処理自体が行われない)
logger.debug("ユーザーID: {} がログインしました。", userId);このように、{} を使用した記述により、ログが出力されないレベルの場合に余計な計算コストを支払わずに済みます。
Logback:Spring Boot 開発の標準選択
Logback は、SLF4J をネイティブに実装しているため、変換レイヤーを介さず高速に動作します。
特に Spring Boot プロジェクトでは標準構成として組み込まれており、最も普及しているライブラリの一つです。
Logback の特徴
- 自動リロード機能
設定ファイル (
logback.xml) を変更した際、アプリケーションを再起動せずに反映させることが可能です。- 柔軟なフィルタリング
特定の条件に合致するログだけを出力したり、特定のクラスだけレベルを変更したりする設定が容易です。
- I/O パフォーマンス
従来の Log4j 1.x と比較して、ファイル出力の書き込み速度が大幅に改善されています。
Logback の設定例
Maven を利用する場合、以下の依存関係を pom.xml に追加します(Spring Boot の場合は spring-boot-starter-logging に含まれています)。
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.16</version>
</dependency>設定ファイル src/main/resources/logback.xml の基本例は以下の通りです。
<configuration>
<!-- コンソール出力の設定 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<!-- ログレベルの設定 -->
<root level="info">
<appender-ref ref="STDOUT" />
</root>
</configuration>Log4j 2:大規模・高負荷システム向けの最適解
Log4j 2 は、Log4j 1.x の設計を根本から見直し、最新の Java 機能を活用して再構築されたライブラリです。
特に 超低遅延・高スループット が要求される金融系システムや大規模Webサービスで威力を発揮します。
Log4j 2 の圧倒的なパフォーマンス
Log4j 2 の最大の特徴は、Async Loggers(非同期ロガー) です。
これは内部で LMAX Disruptor というロックフリーなデータ構造を利用しており、マルチスレッド環境下での競合を最小限に抑えます。
ログ出力処理がメインのスレッドをブロックしないため、アプリケーションの応答性能を劇的に向上させることができます。
Log4j 2 の導入
Maven での依存関係定義は以下の通りです。
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j2-impl</artifactId>
<version>2.24.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.24.1</version>
</dependency>設定ファイル log4j2.xml の例です。
非同期設定を有効にするには、システムプロパティの指定が必要です。
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
<!-- ローリングファイルの設定 -->
<RollingFile name="RollingFile" fileName="logs/app.log"
filePattern="logs/app-%d{yyyy-MM-dd}.log.gz">
<PatternLayout pattern="%d %p %c{1.} [%t] %m%n"/>
<Policies>
<TimeBasedTriggeringPolicy />
</Policies>
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
<AppenderRef ref="RollingFile"/>
</Root>
</Loggers>
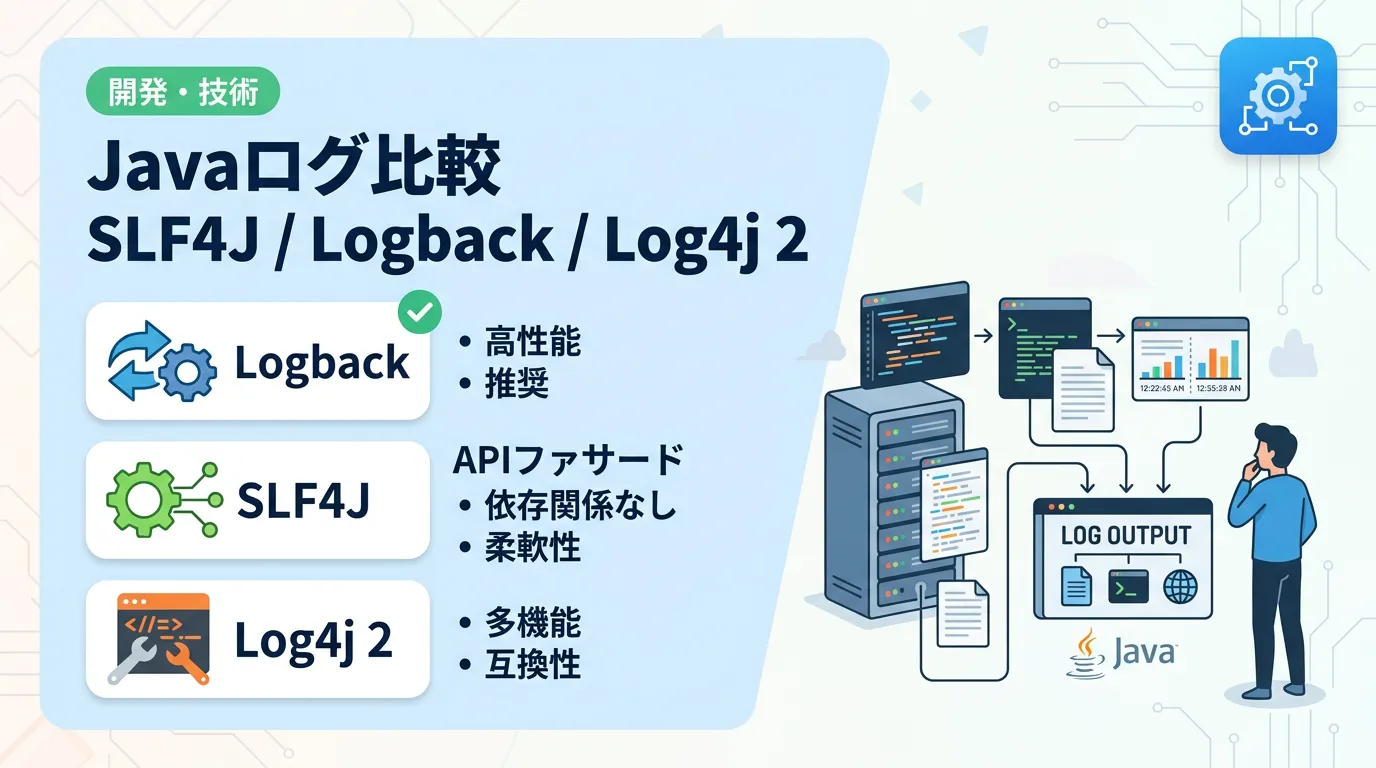
</Configuration>SLF4J・Logback・Log4j 2 の比較
それぞれのライブラリの特性を比較表にまとめました。
| 項目 | SLF4J | Logback | Log4j 2 |
|---|---|---|---|
| 役割 | ファサード (API) | 実装体 | 実装体 |
| 主な特徴 | 抽象化による疎結合 | Spring Boot標準、バランスが良い | 非同期ログによる圧倒的性能 |
| パフォーマンス | – | 高速 | 最高速 |
| 設定の容易さ | 不要 | 容易 (XML, Groovy) | 普通 (XML, JSON, YAML) |
| 推奨シーン | 全てのプロジェクト | 一般的なWebアプリ、Spring Boot | 大規模、高トラフィックシステム |
一般的には、Spring Boot を使用しているなら Logback、極限のパフォーマンスを求めるなら Log4j 2 を選択するのが現在のトレンドです。
実装ガイド:SLF4J を使ったログ出力コード
実際に Java コードでログを出力する際の標準的な実装例を紹介します。
どの実装体(Logback や Log4j 2)を選んでも、ソースコードの記述方法は SLF4J を通じて共通化されます。
package com.example.logging;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
ログ出力のデモンストレーションクラス
*/
public class LogDemo {
// クラスごとにロガーのインスタンスを生成する
private static final Logger logger = LoggerFactory.getLogger(LogDemo.class);
public void processOrder(String orderId, int amount) {
// 1. デバッグレベル:詳細な開発用情報
logger.debug("注文処理を開始します。Order ID: {}", orderId);
try {
if (amount < 0) {
throw new IllegalArgumentException("金額が不正です。");
}
// 2. 情報レベル:正常な動作の記録
logger.info("注文が正常に受理されました。ID: {}, 金額: {}", orderId, amount);
} catch (Exception e) {
// 3. エラーレベル:異常事態の記録(例外オブジェクトを渡す)
logger.error("注文処理中にエラーが発生しました。Order ID: {}", orderId, e);
}
}
public static void main(String[] args) {
LogDemo demo = new LogDemo();
demo.processOrder("ORD-1001", 5000); // 正常系
demo.processOrder("ORD-1002", -100); // 異常系
}
}実行結果のイメージ
設定したレイアウトに基づき、以下のようなログが出力されます。
2026-03-20 10:00:01 [main] DEBUG com.example.logging.LogDemo - 注文処理を開始します。Order ID: ORD-1001
2026-03-20 10:00:01 [main] INFO com.example.logging.LogDemo - 注文が正常に受理されました。ID: ORD-1001, 金額: 5000
2026-03-20 10:00:02 [main] DEBUG com.example.logging.LogDemo - 注文処理を開始します。Order ID: ORD-1002
2026-03-20 10:00:02 [main] ERROR com.example.logging.LogDemo - 注文処理中にエラーが発生しました。Order ID: ORD-1002
java.lang.IllegalArgumentException: 金額が不正です。
at com.example.logging.LogDemo.processOrder(LogDemo.java:21)
...ログ出力のベストプラクティス
ログは単に出せば良いというものではありません。
運用に役立つ「価値のあるログ」を出力するために、以下のポイントを意識してください。
1. 適切なログレベルの使い分け
ログレベルを混同すると、監視アラートが鳴り止まなかったり、逆に重要な予兆を見逃したりします。
- TRACE
メソッドの開始・終了など、極めて詳細なステップ。
通常は無効化。
- DEBUG
開発時の調査に必要な情報。
- INFO
システムの主要なイベント(サービスの起動、ユーザーログイン、バッチ完了など)。
- WARN
継続は可能だが、注意が必要な状態(非推奨APIの使用、一時的な通信エラーなど)。
- ERROR
処理が継続できない異常事態。
管理者に通知すべき状態。
2. 構造化ロギング(JSON形式)の検討
クラウド環境やログ管理ツール(ELK Stack, Datadog, CloudWatch Logs など)を利用する場合、テキスト形式よりも JSON形式での出力 が推奨されます。
JSON形式にすることで、ログのパースが容易になり、「特定のユーザーIDのログだけをフィルタリングする」といった操作が高速かつ確実に行えます。
3. 個人情報・機密情報の除外
ログには クレジットカード番号、パスワード、個人を特定できる情報 (PII) を絶対に出力してはいけません。
セキュリティインシデントに繋がるだけでなく、コンプライアンス違反のリスクがあります。
4. MDC (Mapped Diagnostic Context) の活用
マルチスレッド環境やマイクロサービスでは、複数のリクエストが混在して出力されます。
SLF4J の MDC を使用すると、スレッドごとに「リクエストID」などを保持させ、すべてのログにそのIDを自動的に付与できます。
import org.slf4j.MDC;
MDC.put("requestId", "REQ-12345");
logger.info("処理を開始します。"); // ログに自動で [requestId=REQ-12345] が含まれる
MDC.clear();5. 例外スタックトレースの正しい出力
例外をキャッチした際、e.getMessage() だけをログに出力するのは不十分です。
原因となった箇所を特定するために、必ず 例外オブジェクトそのもの を最後に渡してスタックトレースを出力させてください。
まとめ
Javaにおけるログ出力は、単なるテキストの書き出しではなく、システムの「可観測性 (Observability)」を支える基盤技術です。
現代のプロジェクトにおいては、まず SLF4J をファサードとして採用し、実装体には運用要件に合わせて Logback(汎用・Spring Boot標準)か Log4j 2(高負荷・高性能)を選択するのがベストな構成です。
適切なログレベルの設定、構造化ロギングの導入、そして MDC によるトレーサビリティの確保といったベストプラクティスを実践することで、障害発生時の復旧時間を大幅に短縮し、より安定したシステム運用が可能になります。
この記事を参考に、自社のプロジェクトに最適なロギング戦略を構築してください。