C#において、変数が値を持っていない状態を示す「null」は、開発者にとって非常に身近であると同時に、常に注意を払うべき存在です。
かつては参照型のみがnullを許容し、値型はnullを持てないという制約がありましたが、言語の進化と共にその境界は変化しました。
現代のC#開発では、「Nullable(プログラムにおける無効な状態)」をいかに安全かつ効率的に扱うかが、アプリケーションの堅牢性を左右する重要な要素となっています。
本記事では、値型と参照型それぞれにおけるNullableの記述法から、最新のC#で推奨されるNull安全のポイントまでを詳しく解説します。
C#におけるNullable(追加可能な型)の概念
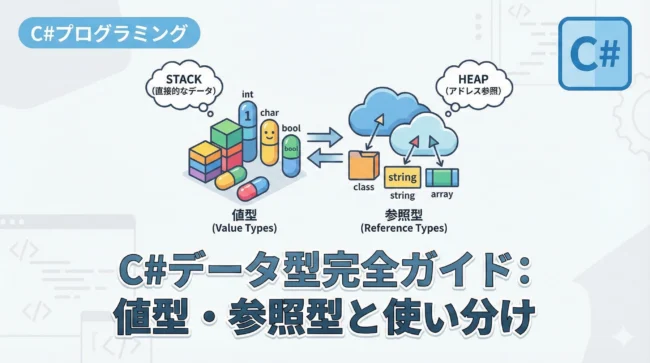
C#の型システムは、大きく分けて「値型(Value Types)」と「参照型(Reference Types)」の2種類に分類されます。
初期のC#では、構造体(struct)や数値型(int, doubleなど)といった値型は常に何らかの値を保持する必要があり、nullを代入することは不可能でした。
一方、クラス(class)などの参照型は、インスタンスが生成されていない状態としてnullをデフォルトで許容していました。
しかし、データベースの操作やAPIとの通信においては、数値データであっても「未入力(null)」を表現したいケースが多々あります。
また、参照型においても、予期せぬnullへのアクセスによるNullReferenceExceptionの発生は、多くのバグの原因となってきました。
これらの課題を解決するために導入されたのが、Nullable Value Types(null許容値型)とNullable Reference Types(null許容参照型)です。
これら二つのNullableは、名前こそ似ていますが、その仕組みや挙動は大きく異なります。
値型の場合は「nullを持てるように拡張する」仕組みであり、参照型の場合は「nullの可能性を明示し、コンパイラが警告を出す」仕組みです。
この違いを正しく理解することが、モダンなC#プログラミングの第一歩となります。
null許容値型(Nullable Value Types)の使い方
null許容値型は、本来nullを保持できない値型に対して、System.Nullable<T> 構造体を使用することでnullを扱えるようにしたものです。
C#では、型名の後ろに ? を付ける簡略表記が一般的に用いられます。
基本的な宣言と代入
例えば、整数の int 型をnull許容にするには、int? と記述します。
これにより、通常の数値に加えてnullを代入することが可能になります。
using System;
class Program
{
static void Main()
{
// null許容値型の宣言
int? nullableInt = null;
double? nullableDouble = 3.14;
// 値の確認
if (nullableInt.HasValue)
{
Console.WriteLine($"nullableIntの値: {nullableInt.Value}");
}
else
{
Console.WriteLine("nullableIntはnullです。");
}
if (nullableDouble.HasValue)
{
Console.WriteLine($"nullableDoubleの値: {nullableDouble.Value}");
}
}
}nullableIntはnullです。
nullableDoubleの値: 3.14HasValueプロパティとValueプロパティ
null許容値型は、HasValue プロパティによって「値が存在するかどうか」を判定できます。
値が存在する場合のみ、Value プロパティから実際のデータを取り出すことができます。
もし、HasValue が false の状態で Value にアクセスすると、InvalidOperationException が発生するため注意が必要です。
現代のC#では、後述するパターンマッチング(is 演算子)を用いることで、より安全かつ直感的に値を取り出す手法が推奨されています。
値型Nullableの内部構造
int? は内部的に Nullable<int> という構造体として実装されています。
この構造体は、元の値を保持するフィールドと、値が有効かどうかを示すブール値のフィールドを組み合わせて持っています。
そのため、参照型のようにヒープ領域にメモリを確保するのではなく、スタック領域で管理されるため、パフォーマンスへの影響が極めて少ないという特徴があります。
null許容参照型(Nullable Reference Types)の導入
C# 8.0から導入された「null許容参照型」は、値型とは全く異なるアプローチでnull安全を実現します。
これは、実行時の挙動を変えるものではなく、コンパイル時の静的解析によってnullによるエラーを未然に防ぐ機能です。
参照型Nullableを有効にする設定
この機能を利用するには、プロジェクト全体で「Nullable Context」を有効にする必要があります。
プロジェクトファイル(.csproj)に以下の記述を追加します。
<PropertyGroup>
<Nullable>enable</Nullable>
</PropertyGroup>この設定が有効な場合、通常の参照型(例:string)は「nullを許容しない型」として扱われるようになります。
構文とコンパイラの警告
nullを許容したい場合は、値型と同様に型名の後ろに ? を付与します。
#nullable enable
using System;
public class User
{
// nullを許容しない(警告の対象)
public string Name { get; set; } = string.Empty;
// nullを許容する
public string? Description { get; set; }
}
class Program
{
static void Main()
{
User user = new User { Name = "Alice" };
// Descriptionはnullの可能性があるため、直接メソッドを呼ぶと警告が出る
// Console.WriteLine(user.Description.Length); // CS8602警告
if (user.Description != null)
{
// ここではnullでないことが保証されるため、警告は出ない
Console.WriteLine(user.Description.Length);
}
}
}この機能の素晴らしい点は、コードを書いている最中にIDE(Visual Studioなど)がnullの危険性を指摘してくれることにあります。
開発者は実行してエラーが出るまで待つ必要がなく、コーディング段階で適切なnullチェックを組み込むことができます。
Nullableを扱う便利な演算子
C#には、Nullableな変数を簡潔かつ安全に操作するための演算子が多数用意されています。
これらを使いこなすことで、コードの可読性は飛躍的に向上します。
null条件演算子 (?.)
?. は、変数がnullでない場合にのみ右側のメンバにアクセスし、nullの場合は処理を行わずにnullを返す演算子です。
string? message = null;
int? length = message?.Length; // messageがnullなので、lengthにはnullが入るこれを使わずに書くと、冗長なif文が必要になりますが、null条件演算子を使えば1行で安全に記述できます。
null合体演算子 (??)
?? は、変数がnullだった場合のデフォルト値を指定するために使用します。
string? input = null;
string displayName = input ?? "名無しユーザー";上記の例では、input がnullであれば「名無しユーザー」が代入されます。
これは、UIに表示する文字列の制御や、設定値の初期化などで非常に役立ちます。
null合体代入演算子 (??=)
C# 8.0で追加されたこの演算子は、変数がnullである場合のみ、右辺の値を代入します。
List<string>? items = null;
// itemsがnullなら、新しいインスタンスを作成して代入する
items ??= new List<string>();
items.Add("C#");変数の「遅延初期化(Lazy Initialization)」を簡潔に行いたい場合に適しています。
null免除演算子(! / null-forgiving operator)
開発者が「この変数はここでは絶対にnullではない」と確信しているものの、コンパイラが警告を出してしまう場合に、コンパイラを黙らせるために使用するのが ! 演算子です。
string? maybeNull = GetValue();
// 開発者がnullでないことを保証する
string data = maybeNull!;ただし、これは実行時のnullチェックをスキップするものではないため、使いどころを誤ると実行時に例外が発生します。
可能な限り、パターンマッチングなどで安全に処理することが推奨されます。
パターンマッチングによる高度なNull制御
モダンなC#(特にC# 9.0以降)では、パターンマッチングを用いたNullチェックが主流となっています。
従来の == null よりも安全で読みやすい記述が可能です。
is null と is not null
比較演算子 == は、クラス側でオーバーロード(挙動の変更)されている可能性があります。
しかし、is 演算子を用いたパターンマッチングはオーバーロードの影響を受けず、純粋にオブジェクトがnullかどうかを判定します。
object? obj = null;
if (obj is null)
{
Console.WriteLine("オブジェクトは空です。");
}
if (obj is not null)
{
Console.WriteLine("オブジェクトは存在します。");
}is not null は非常に可読性が高く、条件分岐の中で否定演算子 ! を使うよりも直感的です。
プロパティパターンを用いた判定
オブジェクトが特定の条件を満たしつつ、nullでないことを確認する場合にもパターンマッチングが威力を発揮します。
public class Employee
{
public string? Name { get; set; }
}
Employee? emp = new Employee { Name = "田中" };
if (emp is { Name: "田中" })
{
Console.WriteLine("田中さんを確認しました。");
}この記法では、emp 自体のnullチェックと、そのプロパティの比較を同時に行っています。
値型Nullableと参照型Nullableの比較
ここで、両者の違いを表にまとめます。
混同しやすいポイントですので、整理しておきましょう。
| 特徴 | null許容値型 (Nullable Value Types) | null許容参照型 (Nullable Reference Types) |
|---|---|---|
| 対象 | 構造体 (int, double, bool, etc.) | クラス (string, 自作クラス, etc.) |
| 実体 | Nullable<T> 構造体 | 型システム上のアノテーション(修飾) |
| 実行時の挙動 | 型自体が変化し、nullを保持できる | コンパイル後のILレベルでは通常の参照型と同じ |
| 主な目的 | 無効な値の状態をデータとして表現する | null参照例外を静的解析で防止する |
| デフォルト | 非許容 (intなどはnull不可) | プロジェクト設定による (基本は非許容推奨) |
値型Nullableは「箱の中にデータが入っているか」を管理する新しいデータ型を作るイメージですが、参照型Nullableは「この変数にはnullを入れないように注意しよう」というコンパイラへのヒントのようなものです。
ジェネリクスにおけるNullableの制約
ジェネリクス(<T>)を使用する場合、Nullableの扱いは少し複雑になります。
なぜなら、T が値型なのか参照型なのかによって、Nullableの仕組みが異なるからです。
C# 8.0以降では、where T : notnull という制約を付けることで、そのジェネリクス型がnullを許容しないことを強制できます。
public class DataHandler<T> where T : notnull
{
public void Process(T item)
{
// itemはnullではないことが保証される
Console.WriteLine(item.ToString());
}
}逆に、どのような型でも受け入れつつnullを許容したい場合は、特定の制約を組み合わせるか、C# 9.0以降の T? の挙動(型パラメータに適用されるNullable)を利用します。
実践的なNull安全のポイント
Nullableを使いこなし、Null安全なコードを書くためのベストプラクティスをいくつか紹介します。
1. 公開APIでは早期に例外を投げる(ガード句)
null許容参照型を有効にしていても、外部ライブラリや設定の不備でnullが渡ってくる可能性はゼロではありません。
メソッドの入り口でチェックを行う「ガード句」を記述しましょう。
public void RegisterUser(string name)
{
// C# 11以降の便利なnullチェック(ArgumentNullException.ThrowIfNull)
ArgumentNullException.ThrowIfNull(name);
// 処理の継続
}2. 空のコレクションにはnullではなく空リストを返す
リストや配列を返すメソッドにおいて、データがない場合にnullを返すと、呼び出し側ですべてnullチェックが必要になります。
基本的には、Enumerable.Empty<T>() や [](コレクション式)を用いて空のインスタンスを返すのが定石です。
3. デフォルト値を意識した設計
クラスのプロパティを定義する際、コンストラクタで初期化するか、デフォルト値を設定することで、不必要なNullableの使用を避けることができます。
Nullableな変数が多すぎるコードは、それだけ複雑性が増しているサインでもあります。
まとめ
C#におけるNullableの扱いは、単なる「nullを許容する」という機能を超え、ソフトウェアの品質と安全性を高めるための強力な武器へと進化しました。
値型における Nullable<T> はデータの不在を明確に表現し、参照型におけるNullableアノテーションは実行前のバグ発見を劇的に容易にします。
また、?. や ?? などの演算子、そしてパターンマッチングを適切に組み合わせることで、冗長なチェックを排除したスマートなコードを記述できます。
Null安全は、一朝一夕で身につくものではありませんが、プロジェクトの開始時に <Nullable>enable</Nullable> を設定し、コンパイラの警告一つひとつに向き合うことから始まります。
今回解説したテクニックを活用し、NullReferenceException に悩まされない、堅牢なC#アプリケーションの開発を目指してください。