C++は、システム開発からゲーム制作、AI開発まで幅広い分野で活用されている非常に強力なプログラミング言語です。
そのC++を学ぶ上で、最も基礎でありながら最も重要な要素の一つが「変数」です。
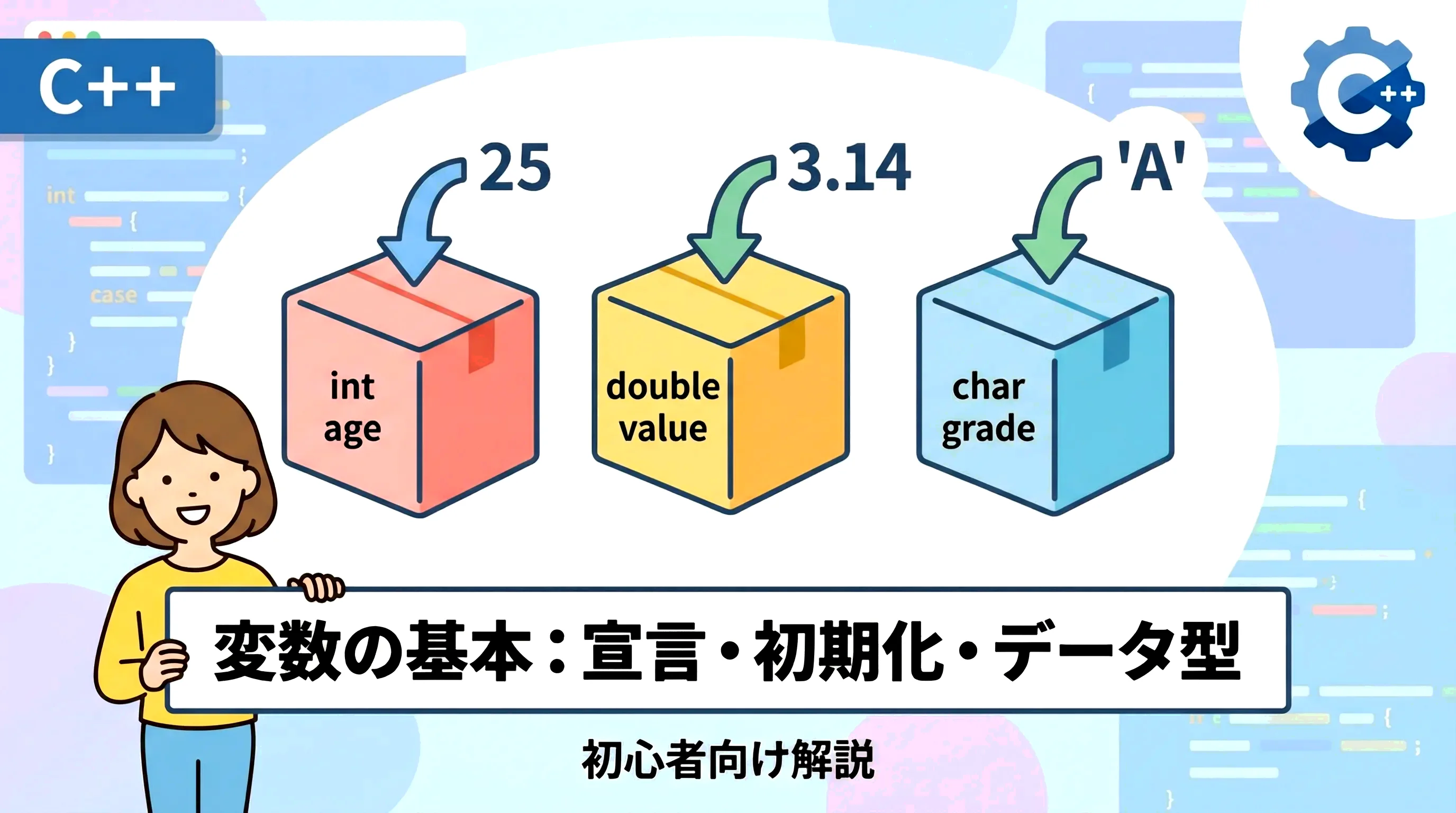
プログラムはデータを処理するために存在しますが、そのデータを一時的に格納しておくための「箱」のような役割を果たすのが変数です。
変数を正しく理解し、適切なデータ型を選択できるようになることは、効率的でバグの少ないコードを書くための第一歩です。
本記事では、C++における変数の宣言方法、初期化の手法、そして多岐にわたるデータ型の種類について、初心者の方でも理解できるよう体系的に解説していきます。
最新のC++標準(C++11以降からC++23を見据えた内容)に基づいた最適な書き方も紹介しますので、ぜひ最後まで読み進めてください。
変数とは何か
プログラミングにおける変数とは、コンピュータのメモリ上に確保されたデータの保存場所に名前を付けたものです。
私たちはこの「名前(識別子)」を通じて、メモリ内のデータにアクセスしたり、値を書き換えたりすることができます。
変数を理解する際によく使われる例えが「ラベルを貼った箱」です。
箱の中には数値や文字などのデータを入れることができ、中身を入れ替えたり、後で取り出して計算に使ったりすることが可能です。
C++は「静的型付け言語」と呼ばれる特性を持っており、変数を使用する前に、その箱にどのような種類のデータを入れるのかをあらかじめ宣言しなければならないというルールがあります。
変数の宣言と代入の基本
C++で変数を使用するには、まず「どのような種類のデータを扱うか(型)」と「変数の名前(識別子)」を指定する「宣言」を行う必要があります。
変数の宣言
変数の宣言は、以下の構文で行います。
型名 変数名;例えば、整数を扱うための int 型の変数 score を宣言する場合は、次のように記述します。
#include <iostream>
int main() {
// 変数の宣言
int score;
return 0;
}この時点では、メモリ上に整数を格納するための領域が確保されただけで、中身は確定していません(未初期化の状態)。
値の代入
宣言した変数に値を入れることを「代入」と呼びます。
代入には = 演算子を使用します。
#include <iostream>
int main() {
int score; // 宣言
score = 100; // 代入
std::cout << "スコアは " << score << " です。" << std::endl;
return 0;
}スコアは 100 です。未初期化の変数(値を一度も代入していない変数)を読み取ろうとすると、実行時に予期しない動作(不定値の出力やクラッシュ)を引き起こす可能性があるため、注意が必要です。
変数の初期化手法
C++には、変数の宣言と同時に最初の値を設定する「初期化」の方法が複数存在します。
現代的なC++開発では、状況に応じて最適な初期化方法を選択することが推奨されています。
コピー初期化
最も伝統的な初期化方法で、他のプログラミング言語でもよく見られる形式です。
int age = 25;直接初期化
丸括弧 () を使用した初期化方法です。
int count(10);リスト初期化(一様初期化)
C++11から導入された、波括弧 {} を使用する方法です。
現代のC++において最も推奨される初期化方法の一つです。
int price{500};
int quantity{5};リスト初期化のメリットは、「ナローイング変換(情報の欠落を伴う型変換)」を防止できることにあります。
例えば、整数型の変数に小数を含む値を代入しようとすると、他の初期化方法では端数が切り捨てられて実行されますが、リスト初期化ではコンパイルエラーとして検知してくれます。
int x = 3.14; // コンパイルは通るが、xは3になる(危険)
int y{3.14}; // コンパイルエラー(安全)C++の主要なデータ型
C++には、扱うデータの性質に合わせて多くのデータ型が用意されています。
ここでは、初心者がまず覚えるべき基本的なデータ型を分類して解説します。
整数型(Integer types)
整数を扱うための型です。
扱う数値の大きさに応じて使い分けます。
| 型名 | 用途 | 一般的なサイズ |
|---|---|---|
int | 一般的な整数 | 4バイト |
short | 小さな整数 | 2バイト |
long | 大きな整数 | 4バイト以上 |
long long | 非常に大きな整数 | 8バイト |
通常は int を使用すれば問題ありませんが、非常に大きな数値を扱う場合は long long を選択します。
浮動小数点型(Floating-point types)
小数点を含む数値を扱うための型です。
| 型名 | 用途 | 精度 |
|---|---|---|
float | 単精度浮動小数点数 | 約7桁 |
double | 倍精度浮動小数点数 | 約15桁 |
long double | 高精度浮動小数点数 | double以上 |
C++では、特に理由がない限り精度が高い double 型を使用するのが一般的です。
文字型・文字列型(Character and String types)
一文字、または文章を扱うための型です。
- char型: 半角英数字一文字を扱います。シングルクォーテーション
''で囲みます。 - std::string型: 文字列(文章)を扱います。ダブルクォーテーション
""で囲みます。
※ std::string を使用するには #include <string> が必要です。
論理型(Boolean type)
真(true)か偽(false)の二値のみを扱う型です。
条件分岐などで頻繁に利用されます。
bool isVisible = true;
bool hasError = false;各データ型の使用例
以下のプログラムは、様々なデータ型を組み合わせて使用した例です。
#include <iostream>
#include <string>
int main() {
// 整数型
int appleCount{5};
// 浮動小数点型
double pi{3.14159};
// 文字型
char grade{'A'};
// 文字列型
std::string message{"Hello, C++!"};
// 論理型
bool isHappy{true};
std::cout << "個数: " << appleCount << std::endl;
std::cout << "円周率: " << pi << std::endl;
std::cout << "成績: " << grade << std::endl;
std::cout << "メッセージ: " << message << std::endl;
std::cout << "状態: " << std::boolalpha << isHappy << std::endl;
return 0;
}個数: 5
円周率: 3.14159
成績: A
メッセージ: Hello, C++!
状態: true型修飾子によるカスタマイズ
基本データ型に「型修飾子」を付けることで、その性質を細かく変更することができます。
signed と unsigned
整数型に対して、符号(プラス・マイナス)の有無を指定します。
- signed: 負の数と正の数の両方を扱います(デフォルト)。
- unsigned: 正の数のみを扱います。 その分、表現できる正の最大値が約2倍になります。
unsigned int positiveOnly{4000000000}; // 大きな正の数const 修飾子
変数の値を後から変更できないように固定します。
これを「定数」と呼びます。
const double TaxRate{0.1};
// TaxRate = 0.08; // エラーになるため、意図しない書き換えを防げるプログラム内で値が変わることがないもの(円周率、消費税率、設定値など)には、積極的に const を付けることが推奨されます。
これにより、コードの意図が明確になり、バグの混入を防ぐことができます。
モダンC++の便利な機能:型推論 auto
C++11から導入された auto キーワードを使用すると、コンパイラが初期化子の値から型を自動的に推論してくれます。
これを「型推論」と呼びます。
auto age = 20; // intと推論される
auto price = 150.5; // doubleと推論される
auto name = "Suzuki"; // const char* と推論されるauto を使用する際は、必ず初期化を行う必要があります。
型名が非常に長くなる場合(イテレータなど)や、テンプレートを扱う際に非常に便利ですが、乱用するとコードの可読性が下がることもあるため、注意が必要です。
変数の命名規則(識別子)
変数に名前を付ける際、C++ではいくつかのルールと慣習があります。
命名のルール(必須)
- 英大文字、英小文字、数字、アンダースコア
_が使用可能。 - 数字から始めることはできない。
- C++の予約語(
int,if,whileなど)は使用できない。 - 大文字と小文字は区別される(
countとCountは別の変数)。
良い名前を付けるための慣習
- 意味が伝わる名前にする:
aやbではなく、userAgeやtotalPriceのように役割がわかる名前にします。 - キャメルケース(camelCase):
itemPriceのように、単語の区切りを大文字にする形式。 - スネークケース(snake_case):
item_priceのように、アンダースコアで繋ぐ形式。
プロジェクトやチームによって採用されるスタイルは異なりますが、一つのプログラム内では命名スタイルを統一することが大切です。
変数のスコープ(有効範囲)
変数には、それが「どこで使えるか」という有効範囲があります。
これを「スコープ」と呼びます。
ローカル変数
関数やブロック {} の中で宣言された変数は、そのブロック内でのみ有効です。
#include <iostream>
void sample() {
int localValue{10}; // ローカル変数
std::cout << localValue << std::endl;
}
int main() {
sample();
// std::cout << localValue << std::endl; // ここでは使えないのでエラー
return 0;
}グローバル変数
関数の外で宣言された変数は、プログラム全体からアクセス可能です。
ただし、どこからでも書き換えられてしまうため、大規模なプログラムでは意図しないバグの原因になりやすく、使用は最小限に抑えるべきです。
型変換(キャスト)
異なるデータ型の間で値を移動させる場合、型変換が発生します。
暗黙の型変換
コンパイラが自動的に行う型変換です。
double d = 10; // int型の10がdouble型の10.0に変換される明示的な型変換(キャスト)
プログラマが明示的に型を指定して変換することです。
C++では static_cast を使用するのが安全で標準的な方法です。
int a = 10;
int b = 3;
double result = static_cast<double>(a) / b; // aを一時的にdoubleとして扱うもし static_cast を使わずに a / b と計算すると、整数同士の計算になり結果は 3 となりますが、キャストを行うことで 3.33333 という正確な結果を得ることができます。
まとめ
C++における変数は、データを管理するための基本単位です。
適切なデータ型を選び、正しく初期化を行い、意味のある名前を付けることは、プログラミングスキルの根幹を成します。
本記事で学んだ重要なポイントを振り返ってみましょう。
- 変数はメモリ上のデータの保存場所であり、名前(識別子)を付けて管理する。
- 宣言と同時に値を決める「初期化」は、安全性の高いリスト初期化
{}を活用するのが現代的。 - 整数なら
int、小数点ならdouble、文字列ならstd::stringなど、適切なデータ型を選択する。 - 値を変更しない場合は
constを付けて定数化し、安全性を高める。 autoによる型推論や、スコープの概念を理解して、効率的なコードを書く。
これらの基礎をしっかりと固めることで、複雑なアルゴリズムや大規模なアプリケーション開発においても、混乱することなくプログラムを構築できるようになります。
まずは自分で様々な型を宣言し、値を表示させる簡単なプログラムを書いてみることから始めてみてください。
C++の世界は奥深いですが、変数のマスターこそがその第一歩となるはずです。