C++におけるプログラミングにおいて、数値データ、特に「整数」をどのように扱うかは、プログラムのメモリ効率、処理速度、そしてバグの少なさに直結する極めて重要な要素です。
整数型は、単に数値を格納するだけの箱ではなく、プログラムがコンピュータのハードウェア(CPUやメモリ)とどのように対話するかを決定する基本的なインターフェースでもあります。
C++には多くの整数型が存在し、それぞれが異なるサイズや範囲を持っています。
また、実行環境(プラットフォーム)によってサイズが変動する場合があるなど、初心者から上級者まで注意深く扱う必要があります。
本記事では、C++における整数型の種類、サイズ、範囲の基礎知識から、現代的な開発において推奨される「適切な使い分け」の基準まで、プロフェッショナルな視点で詳しく解説します。
整数型の基本概念
C++の整数型を理解する上でまず押さえておくべきなのは、整数型が「符号(プラス・マイナス)の有無」と「ビット数(情報の大きさ)」の組み合わせで構成されているという点です。
符号付き整数と符号なし整数
整数型には、正の数と負の数の両方を扱える符号付き整数(signed)と、0以上の正の数のみを扱う符号なし整数(unsigned)の2種類があります。
- 符号付き整数 (signed): 通常、最上位ビット(MSB)を「符号ビット」として使用し、負の数を表現するために「2の補数(Two’s Complement)」形式が用いられます。
- 符号なし整数 (unsigned): 全てのビットを数値の表現に使用するため、符号付き整数と同じビット数であれば、扱える正の数の最大値は約2倍になります。
整数型の階層構造
C++の標準規格では、整数型のサイズについて「具体的なバイト数」を厳密に規定しているわけではありません。
代わりに、「各型の最小サイズ」と「型同士のサイズの大小関係」を定義しています。
char<=short<=int<=long<=long long
この柔軟性があるため、同じプログラムでも32ビットOSと64ビットOS、あるいは異なるコンパイラによって型のサイズが変わることがあります。
これが、C++における整数型を扱う上での難しさであり、面白さでもあります。
整数型の種類・サイズ・範囲の一覧
ここでは、一般的に利用される主要な整数型を一覧表にまとめます。
なお、数値は現代の標準的な64ビット環境(LP64モデルなど)を想定した一般的な値です。
| 型名 | サイズ(目安) | 最小値 | 最大値 |
|---|---|---|---|
signed char | 1 byte (8 bit) | -128 | 127 |
unsigned char | 1 byte (8 bit) | 0 | 255 |
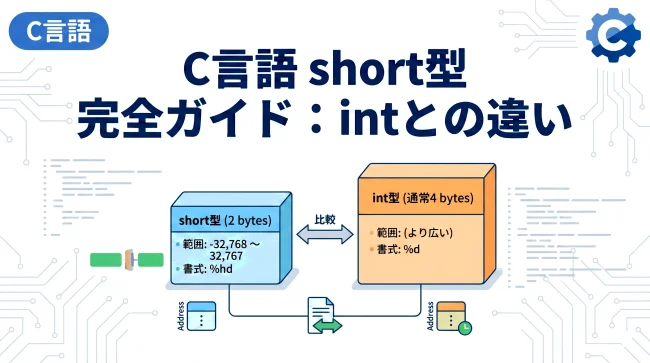
short | 2 byte (16 bit) | -32,768 | 32,767 |
unsigned short | 2 byte (16 bit) | 0 | 65,535 |
int | 4 byte (32 bit) | -2,147,483,648 | 2,147,483,647 |
unsigned int | 4 byte (32 bit) | 0 | 4,294,967,295 |
long | 4 or 8 byte | 環境に依存 | 環境に依存 |
long long | 8 byte (64 bit) | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
unsigned long long | 8 byte (64 bit) | 0 | 18,446,744,073,709,551,615 |
各型の詳細な特徴
1. char型
charは文字を表現するために使われますが、内部的には1バイト(通常8ビット)の整数です。
特殊な点として、charがsignedかunsignedかは処理系(コンパイラやOS)に依存するため、数値を扱う場合は明示的にsigned charまたはunsigned charと記述するのが安全です。
2. int型
最も汎用的に使用される整数型です。
多くの現代的な環境では32ビットですが、古い環境や組み込みシステムでは16ビットであることもあります。
CPUの計算効率が最も高くなるサイズとして定義されることが多いです。
3. long型とlong long型
longは、歴史的に「int以上のサイズ」として扱われてきました。
Windowsでは32ビット、Linux(64bit)では64ビットとなることが多いため、移植性の高いプログラムを書く際には注意が必要です。
一方、long longはC++11から標準化された型で、少なくとも64ビットであることが保証されています。
固定幅整数型(std::intN_t)の活用
前述の通り、標準の整数型は環境によってサイズが変わるリスクがあります。
この問題を解決するために導入されたのが、<cstdint>ヘッダーで定義されている固定幅整数型です。
主要な固定幅整数型
現代のC++開発、特に通信プロトコル、バイナリファイル入出力、ハードウェア制御などでは、これらの型を使用することが推奨されます。
std::int8_t/std::uint8_t(8ビット)std::int16_t/std::uint16_t(16ビット)std::int32_t/std::uint32_t(32ビット)std::int64_t/std::uint64_t(64ビット)
固定幅整数型を使用したプログラム例
以下のコードは、各型のサイズと、その最大値・最小値を表示するプログラムです。
#include <iostream>
#include <cstdint> // 固定幅整数型のために必要
#include <limits> // 最大値・最小値の取得に必要
int main() {
// std::int32_t の情報を出力
std::cout << "int32_t size: " << sizeof(std::int32_t) << " bytes" << std::endl;
std::cout << "int32_t min: " << std::numeric_limits<std::int32_t>::min() << std::endl;
std::cout << "int32_t max: " << std::numeric_limits<std::int32_t>::max() << std::endl;
// std::uint64_t の情報を出力
std::cout << "\nuint64_t size: " << sizeof(std::uint64_t) << " bytes" << std::endl;
std::cout << "uint64_t min: " << std::numeric_limits<std::uint64_t>::min() << std::endl;
std::cout << "uint64_t max: " << std::numeric_limits<std::uint64_t>::max() << std::endl;
return 0;
}int32_t size: 4 bytes
int32_t min: -2147483648
int32_t max: 2147483647
uint64_t size: 8 bytes
uint64_t min: 0
uint64_t max: 18446744073709551615このように、std::numeric_limitsを使用することで、プログラム内で動的に型の限界値を取得することが可能です。
適切な使い分けのガイドライン
多くの型がある中で、どのように型を選ぶべきでしょうか。
ここでは実践的な判断基準を紹介します。
1. 原則として「int」を使用する
通常の計算、ループカウンタ、関数の戻り値など、特別な理由がない限りはintを使用するのが最も一般的です。
これは、そのCPUにおいて最も処理効率が良いサイズとして設計されているためです。
ただし、数値が20億を超える可能性がある場合はlong longを選択します。
2. 配列のサイズやインデックスには「std::size_t」
配列の要素数や、メモリ上のサイズを表す場合には、符号なし整数型のstd::size_tを使用します。
これは、そのプラットフォームが扱える最大メモリサイズに対応するように定義されており、64ビット環境では通常64ビットになります。
3. 明確なデータ仕様がある場合は「固定幅整数型」
ファイルフォーマットの定義や、ネットワーク経由でのデータ送受信を行う場合、送信側と受信側で型のサイズが異なるとデータが壊れてしまいます。
このようなケースでは、必ずstd::int32_tなどの固定幅型を使用してください。
4. 符号なし型(unsigned)の使用は慎重に
「負の数にならないから」という理由だけでunsignedを多用するのは避けるべきです。
C++の型変換ルールにより、符号付きと符号なしを混ぜて計算すると、予期せぬ大きな値(ラップアラウンド)が発生し、バグの原因になります。
整数オーバーフローの危険性
整数型には扱える範囲の限界があり、それを超える計算をしようとすることを「整数オーバーフロー」と呼びます。
オーバーフローの挙動
C++の規格では、以下のように定められています。
- 符号なし整数のオーバーフロー: 最大値を超えると0に戻る(定義された挙動)。これをラップアラウンドと呼びます。
- 符号付き整数のオーバーフロー: 未定義動作 (Undefined Behavior)。つまり、何が起こるか保証されません。クラッシュする場合もあれば、一見正常に動いているように見えて計算結果がデタラメになる場合もあります。
#include <iostream>
#include <limits>
int main() {
// 符号なしのラップアラウンド
unsigned int u_val = std::numeric_limits<unsigned int>::max();
std::cout << "Before: " << u_val << std::endl;
u_val += 1; // 最大値に1を足す
std::cout << "After : " << u_val << " (Wrapped around to 0)" << std::endl;
// 符号付きのオーバーフロー(非常に危険なコード)
int s_val = std::numeric_limits<int>::max();
std::cout << "\nSigned Max: " << s_val << std::endl;
// s_val += 1; // これは未定義動作を引き起こす
return 0;
}Before: 4294967295
After : 0 (Wrapped around to 0)
Signed Max: 2147483647現実のソフトウェア開発では、ユーザーからの入力値などが原因でオーバーフローが発生しないよう、事前に範囲チェックを行うことが必須となります。
整数リテラルと型指定
コード内に直接記述する数値(リテラル)にも型があります。
デフォルトでは、数値リテラルはintとして扱われますが、サフィックス(接尾辞)を付けることで型を明示できます。
100U:unsigned int100L:long100LL:long long100ULL:unsigned long long
また、C++14からは桁区切り文字としてシングルクォート(')を使用できるようになりました。
これにより、大きな数値を読みやすく記述できます。
// 10億を分かりやすく記述
long long huge_value = 1'000'000'000LL;まとめ
C++の整数型は、単なる数値の器を超えて、システムのメモリ管理やパフォーマンスの根幹を支える要素です。
本記事で解説した重要ポイントを振り返ります。
- 標準の整数型(
int,long等)はサイズが環境によって変動する可能性がある。 - 固定幅整数型(
std::int32_t等)を使用することで、移植性と安全性を高められる。 - 符号付き整数のオーバーフローは未定義動作であり、厳禁である。
- 配列のインデックス等には、専用の型である
std::size_tを使用する。
型を適切に選択することは、「将来の自分や他の開発者がバグに悩まされないための投資」でもあります。
まずは基本となるintと、サイズの保証が必要な場面でのstd::int32_tやstd::int64_tを使い分けるところから意識してみてください。
正しい型の理解は、より堅牢で効率的なC++プログラムを書くための第一歩となります。