C言語を学習する上で、多くのプログラミング初心者が最初に直面する大きな壁が「ポインタ」です。
変数や関数といった基本文法を学んだ後に登場するこの概念は、目に見えないメモリの世界を扱うため、イメージが湧きにくく挫折の原因になることも少なくありません。
しかし、ポインタこそがC言語の本質であり、コンピュータを自在に操るための最強の武器でもあります。
ポインタをマスターすることで、プログラムの実行速度を劇的に向上させたり、複雑なデータ構造を効率的に管理したりすることが可能になります。
本記事では、ポインタの仕組みから、なぜプロフェッショナルの現場でポインタが重宝されるのか、その具体的なメリットを詳しく解説します。
ポインタの正体とは?メモリとアドレスの関係
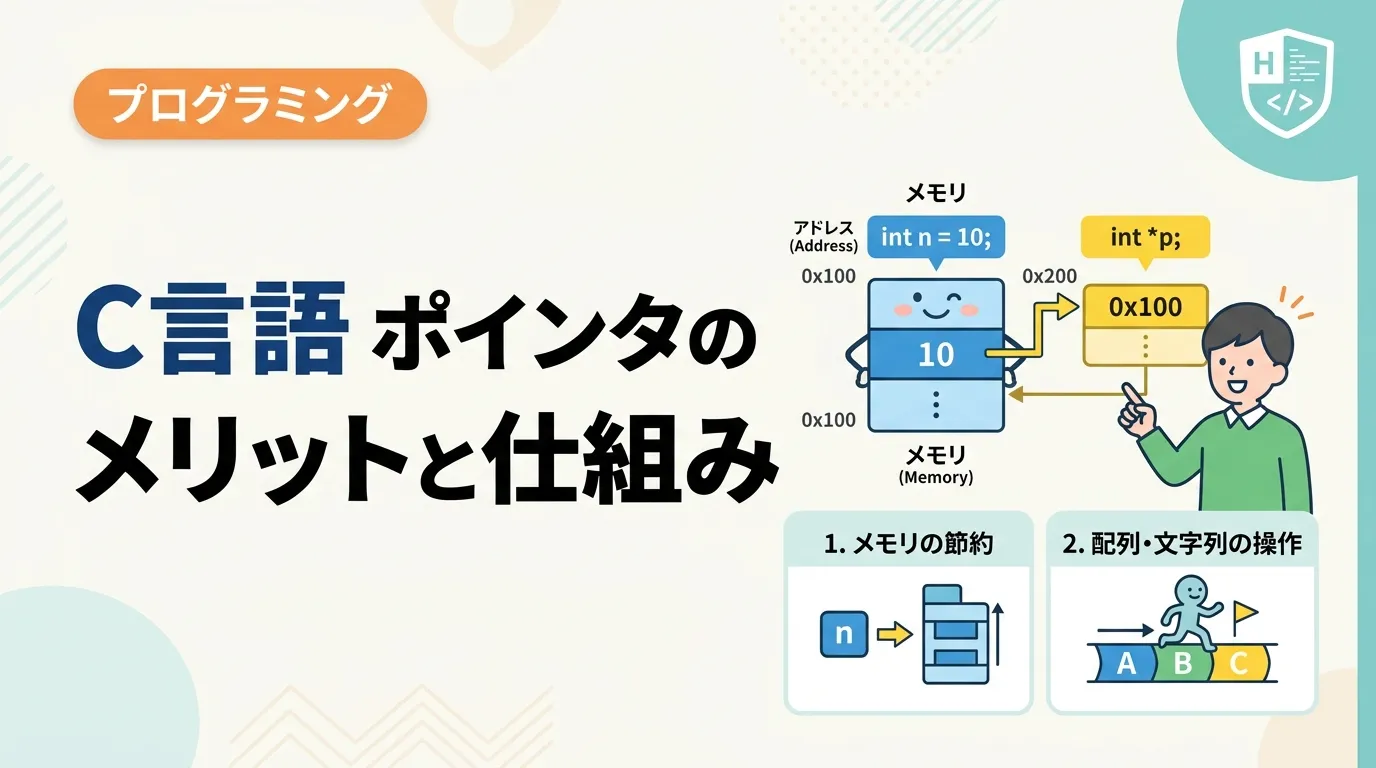
ポインタを理解するためには、まずコンピュータの「メモリ」の仕組みを知る必要があります。
メモリは、データの一時的な保存場所であり、巨大な「番号付きの部屋(セル)」が並んでいるイメージです。
この一つ一つの部屋にはアドレス(住所)と呼ばれる番号が割り振られています。
通常、私たちが変数を使用するとき、例えば int a = 10; と記述すれば、コンピュータはメモリ内のどこかの部屋に「10」という数値を書き込みます。
このとき、プログラム側では「a」という名前でデータを管理しますが、コンピュータ内部では「0x7ffee4b28abc」といった数値のアドレスで管理されています。
ポインタ変数の役割
ポインタとは、一言で言えば「他の変数が保存されているメモリのアドレス(住所)を格納するための変数」です。
通常の変数が「値(10や20など)」を直接保持するのに対し、ポインタ変数は「どこにデータがあるかという場所の情報」を保持します。
アドレス演算子と間接参照演算子
ポインタを扱う際には、以下の2つの記号が極めて重要になります。
| 演算子 | 名称 | 役割 |
|---|---|---|
& | アドレス演算子 | 変数のメモリ上のアドレスを取得する |
* | 間接参照演算子(デリファレンス) | ポインタが指し示すアドレスにある値を読み書きする |
以下のコードで、ポインタの基本的な動きを確認してみましょう。
#include <stdio.h>
int main() {
int num = 100; // 通常の変数
int *ptr; // ポインタ変数の宣言(int型のアドレスを格納する)
ptr = # // numのアドレスをptrに代入
printf("numの値: %d\n", num);
printf("numのアドレス: %p\n", (void *)&num);
printf("ptrが保持しているアドレス: %p\n", (void *)ptr);
printf("ptrを経由してアクセスした値: %d\n", *ptr);
return 0;
}numの値: 100
numのアドレス: 0x7ffd5e2a2aac
ptrが保持しているアドレス: 0x7ffd5e2a2aac
ptrを経由してアクセスした値: 100このプログラムでは、ptr というポインタ変数が num の「住所」を覚えています。
そして、*ptr と記述することで、その住所に直接アクセスして中身を取り出しています。
これがポインタの基本メカニズムです。
メリット1:関数の引数で「元のデータ」を書き換えられる
C言語の関数において、ポインタを使う最大のメリットの一つが「値の参照渡し(擬似的な参照渡し)」です。
通常、C言語の関数は「値渡し(Call by Value)」という仕組みを採用しています。
これは、関数に引数を渡す際、その「コピー」が作成されることを意味します。
そのため、関数の中で引数の値をいくら書き換えても、呼び出し元の元の変数には一切影響を与えません。
しかし、ポインタを使って「変数のアドレス」を渡せば、関数内から呼び出し元の変数を直接操作することが可能になります。
値の入れ替え(Swap)による比較
2つの変数の値を入れ替える処理を例に見てみましょう。
#include <stdio.h>
// ポインタを使わない場合(値渡し)
void swap_fail(int x, int y) {
int temp = x;
x = y;
y = temp;
}
// ポインタを使う場合(アドレス渡し)
void swap_success(int *px, int *py) {
int temp = *px;
*px = *py;
*py = temp;
}
int main() {
int a = 10, b = 20;
// 失敗例
swap_fail(a, b);
printf("swap_fail後: a = %d, b = %d\n", a, b);
// 成功例
swap_success(&a, &b);
printf("swap_success後: a = %d, b = %d\n", a, b);
return 0;
}swap_fail後: a = 10, b = 20
swap_success後: a = 20, b = 10swap_fail では関数内にコピーされた値だけが入れ替わっていますが、swap_success ではアドレスを通じてメモリ上の実体を書き換えているため、呼び出し元の値が正しく変更されています。
このように、関数の外部に対して副作用(結果の反映)を持たせたい場合に、ポインタは不可欠なツールとなります。
メリット2:巨大なデータの転送コストを最小化できる
現代のアプリケーションでは、画像データ、複雑な構造体、大量の配列など、サイズの大きなデータを扱うことがよくあります。
これらのデータを関数に渡す際、ポインタを使わないと非常に効率が悪くなります。
コピーのオーバーヘッドを防ぐ
例えば、1,000個の要素を持つ構造体があったとします。
この構造体を値渡しで関数に渡すと、CPUはメモリ上の1,000個のデータをすべて別の場所にコピーしなければなりません。
これには「処理時間の増大」と「メモリ消費量の増加」という2つのデメリットがあります。
一方で、ポインタを使用した場合、渡すのはたった一つのアドレス情報(通常、64ビット環境なら8バイト程度)だけです。
データの本体がどれほど巨大であっても、ポインタのサイズは常に一定です。
- 値渡し: 巨大なデータを丸ごとコピーするため、動作が重くなる。
- ポインタ渡し: データの「場所」だけを教えるため、一瞬で処理が終わる。
この性質により、大規模なシステム開発やゲームプログラミング、リアルタイム制御といった高いパフォーマンスが要求される現場では、ポインタの活用が前提となっています。
メリット3:動的なメモリ確保(ヒープ領域の活用)
C言語で配列を宣言する場合、通常は int arr[10]; のようにサイズをあらかじめ決めておく必要があります(静的確保)。
しかし、実際にプログラムを動かしてみるまで、データがいくつ必要になるか分からないケースは多々あります。
ここで登場するのが、malloc(Memory Allocation)関数とポインタの組み合わせです。
これを動的メモリ確保と呼びます。
必要な分だけメモリを確保する
ポインタを使用することで、プログラムの実行中に必要な分だけメモリ領域を確保し、不要になったら解放(free)することができます。
#include <stdio.h>
#include <stdlib.h> // malloc, freeのために必要
int main() {
int size;
int *dynamic_arr;
printf("配列のサイズを入力してください: ");
scanf("%d", &size);
// 指定されたサイズ分、メモリを動的に確保
dynamic_arr = (int *)malloc(size * sizeof(int));
if (dynamic_arr == NULL) {
printf("メモリの確保に失敗しました。\n");
return 1;
}
for (int i = 0; i < size; i++) {
dynamic_arr[i] = i * 10;
printf("dynamic_arr[%d] = %d\n", i, dynamic_arr[i]);
}
// 使い終わったら必ず解放
free(dynamic_arr);
printf("メモリを解放しました。\n");
return 0;
}このように、ユーザーの入力や読み込むファイルのサイズに応じて柔軟にメモリを使い分けることができるのは、ポインタを介してアドレスを管理しているからこそ可能です。
メリット4:複雑なデータ構造(リスト・木構造)の構築
ポインタを最も高度に活用する例が、データ構造の構築です。
配列はメモリ上にデータが連続して並ぶ必要がありますが、ポインタを使えば、メモリ上の離れた場所にあるデータ同士を関連付けることができます。
連結リスト(Linked List)
例えば「連結リスト」は、データと「次のデータの場所(ポインタ)」をセットにした構造です。
- データA(次の場所:データBのアドレス)
- データB(次の場所:データCのアドレス)
- データC(次の場所:NULL)
このようにポインタで繋ぐことで、データの途中に新しい要素を挿入したり、削除したりする操作が、配列よりも遥かに高速に行えます。
また、二分探索木やグラフ構造といった、現代のアルゴリズムに欠かせない複雑な構造も、すべてポインタによる「データの紐付け」によって実現されています。
メリット5:ハードウェアやOSに近い低層レイヤーの操作
C言語が「低級言語(ハードウェアに近い言語)」と呼ばれる所以の一つが、ポインタによってメモリの特定のアドレスを直接指し示せる点にあります。
デバイスドライバと組み込み開発
組み込みシステム(家電や自動車の制御など)では、特定のハードウェアレジスタがメモリ上の特定のアドレスに割り当てられていることがよくあります。
volatile unsigned int *reg = (unsigned int *)0x40001000;
といったコードを書くことで、特定のハードウェアを直接制御することが可能です。
JavaやPythonといった高級言語では、安全性のためにメモリアドレスを直接触ることは禁止されています。
しかし、OSのカーネル開発やデバイスドライバの開発、極限の最適化が必要なライブラリ開発においては、この「メモリへの直接アクセス」ができる自由度こそが、C言語が現在も第一線で使われ続けている最大の理由です。
ポインタを扱う際の注意点と安全な使い方
ポインタは非常に強力なツールですが、扱いを誤るとプログラムを異常終了させたり、セキュリティホールを作ったりする危険性も秘めています。
以下の点には常に注意を払う必要があります。
- NULLポインタのチェック
どこも指していないポインタ(NULL)に対して操作を行おうとすると、Segmentation Fault(不正なメモリアクセス)でプログラムが強制終了します。
- 未初期化ポインタ
宣言したばかりのポインタにはゴミデータ(デタラメなアドレス)が入っています。
初期化せずに使用するのは極めて危険です。
- メモリリーク
mallocで確保したメモリをfreeし忘れると、プログラムが動いている間、メモリが消費され続けてしまいます。
現代的なC言語の記述では、これらのリスクを避けるために「静的解析ツール」を活用したり、コーディング規約で「ポインタの有効範囲(スコープ)」を厳格に管理したりすることが一般的です。
まとめ
C言語におけるポインタは、単なる「アドレスの保存変数」以上の価値を持っています。
- 関数の枠を超えてデータを自由に操作できる。
- 巨大なデータをコピーせず、最小限のコストでやり取りできる。
- 実行時に必要なメモリ量を決定できる柔軟性を持つ。
- 連結リストや木構造など、高度なデータ構造を実現できる。
- ハードウェアの性能を限界まで引き出す低層操作が可能になる。
ポインタの概念を理解することは、単にC言語の文法を覚えることではなく、「コンピュータがどのようにメモリを使い、どのように動いているのか」というコンピュータサイエンスの核心に触れることと同義です。
最初は難しく感じるかもしれませんが、実際にコードを書き、メモリの動きを意識することで、ポインタはあなたのプログラミングスキルを一段上のステージへと引き上げてくれるでしょう。
C言語の真のパワーを解き放つために、ぜひポインタの習得に挑戦してみてください。