C言語を学ぶ上で、データ構造の理解は避けて通れない重要なステップです。
その中でも「スタック (Stack)」は、シンプルでありながらコンピュータシステムの根幹を支える極めて強力な概念です。
関数の呼び出し管理、数式の計算、再帰処理の制御など、プログラムが動作するあらゆる場面でスタックの仕組みが利用されています。
本記事では、C言語におけるスタックの基本原理から、配列および連結リストを用いた具体的な実装方法、さらには実践的な活用シーンまでを網羅的に詳しく解説します。
プログラミング初心者から中級者まで、データ構造への理解を深めるための決定版ガイドとしてご活用ください。
スタックの基本概念とLIFOの仕組み
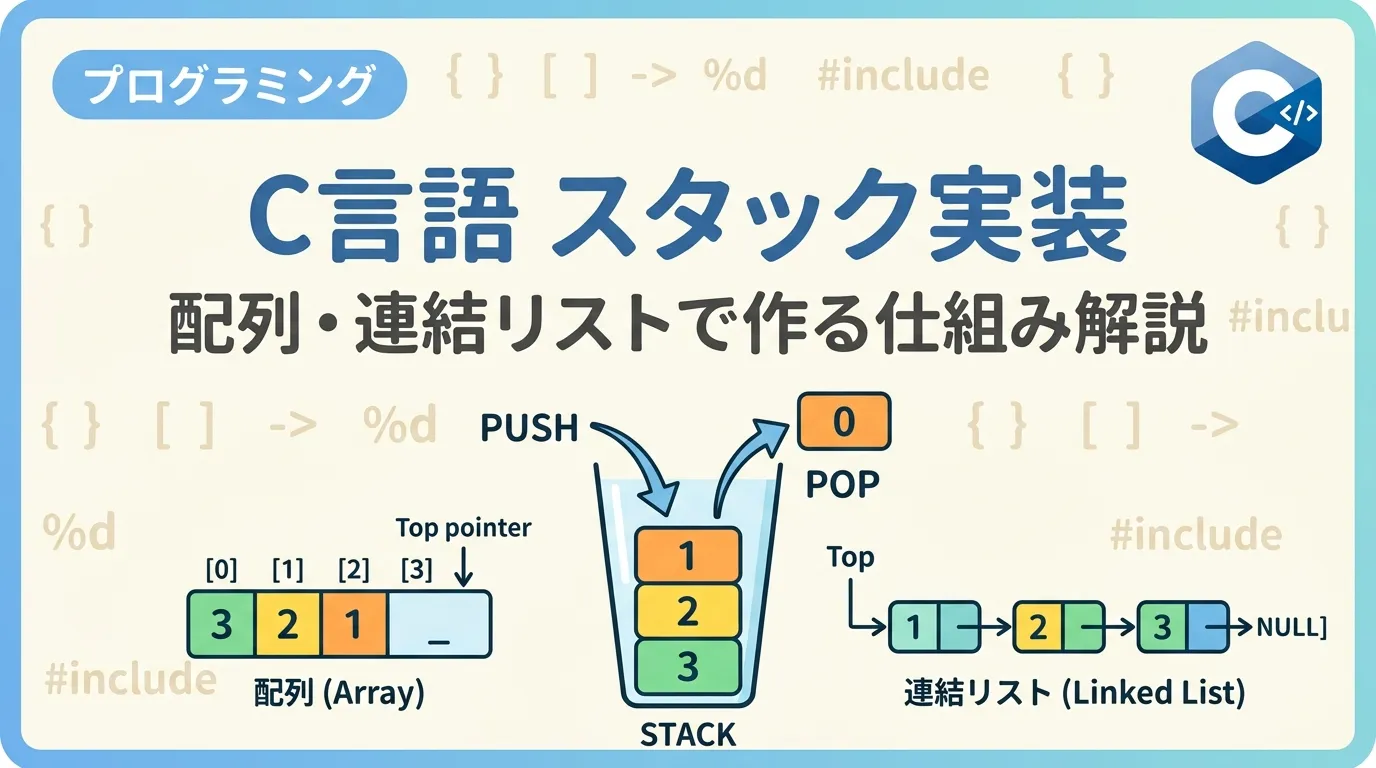
スタックは、データを一列に並べて管理するデータ構造の一種であり、「後入れ先出し (LIFO: Last-In First-Out)」という規則に従って動作します。
これは、机の上に本を積み重ねていく様子をイメージすると分かりやすいでしょう。
最後に置いた本が一番上にあり、最初に取り出すことができるのは常にその一番上の本です。
スタックの主要な操作
スタックを操作するためには、主に以下の 5 つの関数(操作)を定義するのが一般的です。
- push(プッシュ):スタックの最上部に新しいデータを追加します。
- pop(ポップ):スタックの最上部からデータを取り出し、削除します。
- peek / top(ピーク / トップ):最上部のデータを確認しますが、削除はしません。
- isEmpty(イズ・エンプティ):スタックが空かどうかを確認します。
- isFull(イズ・フル):スタックが満杯かどうかを確認します(配列実装の場合に重要)。
なぜC言語でスタックを学ぶのか
C言語はメモリ操作を直接記述できるため、スタックの内部構造を理解するのに最適な言語です。
高級言語では標準ライブラリとして提供されていることが多いですが、自力で実装することで、「メモリがどのように割り当てられ、ポインタがどう動くのか」というコンピュータサイエンスの基礎を体得できます。
配列によるスタックの実装
まずは、最もシンプルで直感的な「配列」を用いた実装方法を見ていきましょう。
配列を使用する場合、スタックの最大容量をあらかじめ決めておく必要があります。
配列スタックの構造
配列実装では、データを格納する配列と、現在の一番上の要素を示すインデックス(通常 top と呼びます)を管理します。
| 要素 | 説明 |
|---|---|
data[] | 実際の値を保持する固定長の配列 |
top | 最上部要素のインデックス。空の時は -1 |
MAX | スタックが保持できる最大要素数 |
配列スタックのソースコード
以下に、配列を用いたスタックの基本実装を示します。
#include <stdio.h>
#include <stdbool.h>
#define MAX 5 // スタックの最大サイズ
// スタックの構造体定義
typedef struct {
int items[MAX];
int top;
} Stack;
// スタックの初期化
void initStack(Stack *s) {
s->top = -1; // -1はスタックが空であることを示す
}
// スタックが満杯か確認
bool isFull(Stack *s) {
return s->top == MAX - 1;
}
// スタックが空か確認
bool isEmpty(Stack *s) {
return s->top == -1;
}
// データの追加 (Push)
void push(Stack *s, int value) {
if (isFull(s)) {
printf("エラー:スタックが満杯です。 %d をプッシュできません。\n", value);
} else {
s->top++;
s->items[s->top] = value;
printf("%d をプッシュしました。\n", value);
}
}
// データの取り出し (Pop)
int pop(Stack *s) {
if (isEmpty(s)) {
printf("エラー:スタックが空です。\n");
return -1; // エラー値
} else {
int value = s->items[s->top];
s->top--;
return value;
}
}
int main() {
Stack s;
initStack(&s);
push(&s, 10);
push(&s, 20);
push(&s, 30);
printf("ポップした値: %d\n", pop(&s));
printf("ポップした値: %d\n", pop(&s));
return 0;
}10 をプッシュしました。
20 をプッシュしました。
30 をプッシュしました。
ポップした値: 30
ポップした値: 20配列実装のメリットとデメリット
メリット:
- 実装が非常に簡単で、コードの可読性が高い。
- メモリの連続領域を使用するため、アクセス速度が高速。
- ポインタのオーバーヘッドがない。
デメリット:
- サイズが固定であり、実行中に拡張することができない。
- 最初に大きなメモリを確保しすぎると、無駄が発生する可能性がある。
連結リストによるスタックの実装
次に、動的にサイズを変更できる「連結リスト (Linked List)」を用いた実装を解説します。
この方法では、新しい要素が追加されるたびにメモリを確保するため、理論上はメモリが許す限り無限にデータを積むことができます。
連結リストスタックの構造
各要素(ノード)は、「保持する値」と「次のノードへのポインタ」を持ちます。
スタックの top は、常にリストの先頭ノードを指すようにします。
連結リストスタックのソースコード
動的メモリ確保(malloc)を使用した実装例です。
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
// ノードの構造体定義
typedef struct Node {
int data;
struct Node *next;
} Node;
// スタックを管理するトップポインタ
Node* top = NULL;
// スタックが空か確認
bool isEmpty() {
return top == NULL;
}
// データの追加 (Push)
void push(int value) {
// 新しいノードのメモリを確保
Node *newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL) {
printf("メモリ割り当てに失敗しました。\n");
return;
}
newNode->data = value;
newNode->next = top; // 現在のトップを次のノードに指定
top = newNode; // 新しいノードをトップにする
printf("%d をプッシュしました。\n", value);
}
// データの取り出し (Pop)
int pop() {
if (isEmpty()) {
printf("エラー:スタックが空です。\n");
return -1;
}
Node *temp = top;
int poppedValue = temp->data;
top = top->next; // 次のノードをトップに移動
free(temp); // メモリを解放
return poppedValue;
}
// 最上部の値を確認 (Peek)
int peek() {
if (!isEmpty()) {
return top->data;
}
return -1;
}
int main() {
push(100);
push(200);
push(300);
printf("現在の最上部: %d\n", peek());
printf("ポップした値: %d\n", pop());
printf("ポップした値: %d\n", pop());
printf("ポップした値: %d\n", pop());
return 0;
}100 をプッシュしました。
200 をプッシュしました。
300 をプッシュしました。
現在の最上部: 300
ポップした値: 300
ポップした値: 200
ポップした値: 100連結リスト実装のメリットとデメリット
メリット:
- 動的なサイズ変更が可能。あらかじめ最大数を決める必要がない。
- 必要な分だけメモリを消費するため、メモリ効率が良い(要素が少ない場合)。
デメリット:
- ポインタ(
next)を保持するための追加メモリが必要。 mallocとfreeの呼び出しに伴う実行時のコスト(オーバーヘッド)がある。
配列 vs 連結リスト:どちらを使うべきか?
どちらの実装を選ぶべきかは、アプリケーションの要件によって異なります。
以下の比較表を参考にしてください。
| 特徴 | 配列実装 | 連結リスト実装 |
|---|---|---|
| メモリ割り当て | 静的(コンパイル時または初期化時) | 動的(実行時) |
| アクセス速度 | 高速(キャッシュ効率が良い) | 配列に比べると低速 |
| サイズの柔軟性 | 低い(固定長) | 高い(可変長) |
| メモリ消費 | 最大サイズ分を常に占有 | 要素数 + ポインタ分 |
| 実装の難易度 | 低い | やや高い(ポインタ操作) |
基本的には、データ数が予測可能であれば配列を、予測不可能であれば連結リストを選択するのが定石です。
スタックの応用例:逆ポーランド記法と数式計算
スタックの具体的な活用例として有名なのが、「逆ポーランド記法 (Reverse Polish Notation, RPN)」の計算です。
通常の数式「3 + 4」を「3 4 +」のように記述する方式で、スタックを使うとコンピュータで非常に効率的に計算できます。
アルゴリズムの流れ
- 数値を読み込んだらスタックに
pushする。 - 演算子(+, -, * など)を読み込んだら、スタックから 2 つの値を
popする。 - 計算結果を再びスタックに
pushする。 - 最後にスタックに残った値が計算結果となる。
このように、スタックは「一時的にデータを保持し、後で逆順または特定の順序で取り出す」必要があるアルゴリズムにおいて不可欠な存在です。
メモリ管理における「スタック領域」との違い
C言語を学んでいると、「スタック」という言葉をデータ構造以外でも耳にします。
それはメモリ管理における「スタック領域」です。
データ構造としてのスタック
この記事で解説してきた、struct などを用いて論理的に構築したデータ管理手法です。
メモリセグメントとしてのスタック
OSがプログラム実行時に割り当てるメモリ領域の一部です。
- 役割:ローカル変数の保存、関数の戻り先アドレスの保持。
- 挙動:関数が呼び出されると「スタックフレーム」が積まれ、関数が終了すると自動的に破棄されます。
- スタックオーバーフロー:再帰呼び出しが深すぎたり、巨大なローカル配列を確保したりすると、この領域が足りなくなりプログラムがクラッシュします。
論理的なデータ構造としてのスタックは、このメモリの「スタック領域」の動きを模倣して作られているとも言えます。
スタック実装時の注意点とベストプラクティス
スタックを自作する際には、いくつかの典型的なバグや設計上の注意点があります。
1. アンダーフローとオーバーフローのチェック
空のスタックから pop しようとすることをアンダーフロー、満杯のスタックに push しようとすることをオーバーフローと呼びます。
これらをチェックせずに操作を続けると、セグメンテーションフォールトやデータの破損を招きます。
必ず isEmpty や isFull によるガードを入れましょう。
2. メモリリークの防止(連結リストの場合)
連結リストで実装する場合、pop したノードのメモリを必ず free する必要があります。
また、プログラム終了時にスタック内に残っている全ノードを解放する処理も忘れないようにしてください。
3. 汎用的なデータ型の扱い
上記のサンプルコードでは int 型を扱っていますが、実際の開発では void*(汎用ポインタ)を使用することで、任意のデータ構造を格納できるスタックを作成できます。
これにより、再利用性の高いライブラリを構築可能です。
// 汎用スタックのノード例
typedef struct Node {
void *data; // 任意のデータへのポインタ
struct Node *next;
} Node;まとめ
スタックは、C言語におけるデータ構造の基礎であり、プログラミングの論理的思考を養うための絶好の題材です。
「LIFO (後入れ先出し)」という単純なルールに基づいていながら、その応用範囲はコンパイラの設計から最新のアプリケーション開発まで多岐にわたります。
本記事では、配列による静的な実装と連結リストによる動的な実装の 2 種類を解説しました。
- 配列実装は、速度とシンプルさを求める場合に適しています。
- 連結リスト実装は、柔軟性とメモリ効率(動的な拡張性)を求める場合に適しています。
これらのコードを実際に自分の手で打ち込み、動作を追いかけることで、C言語のポインタ操作やメモリ管理の感覚がより鮮明になるはずです。
スタックをマスターした後は、対になるデータ構造である「キュー (Queue)」や、より複雑な「木構造 (Tree)」の学習へと進んでみてください。
データ構造の理解を深めることは、より効率的で堅牢なコードを書くための確かな一歩となるでしょう。