C言語を用いて開発を行う際、ターゲットとなるCPUアーキテクチャが32bitか64bitかを意識することは、プログラムの動作安定性やパフォーマンスを左右する極めて重要な要素です。
かつては32bit環境が主流でしたが、現代ではサーバー、デスクトップ、そしてスマートフォンに至るまで64bit環境が標準となっています。
しかし、C言語はハードウェアに近いレイヤーを扱う言語であるため、ビット数の違いによるデータ型のサイズ変更やメモリ管理の仕様差が、思わぬバグや互換性の問題を引き起こすことがあります。
32bitと64bitの根本的な違い
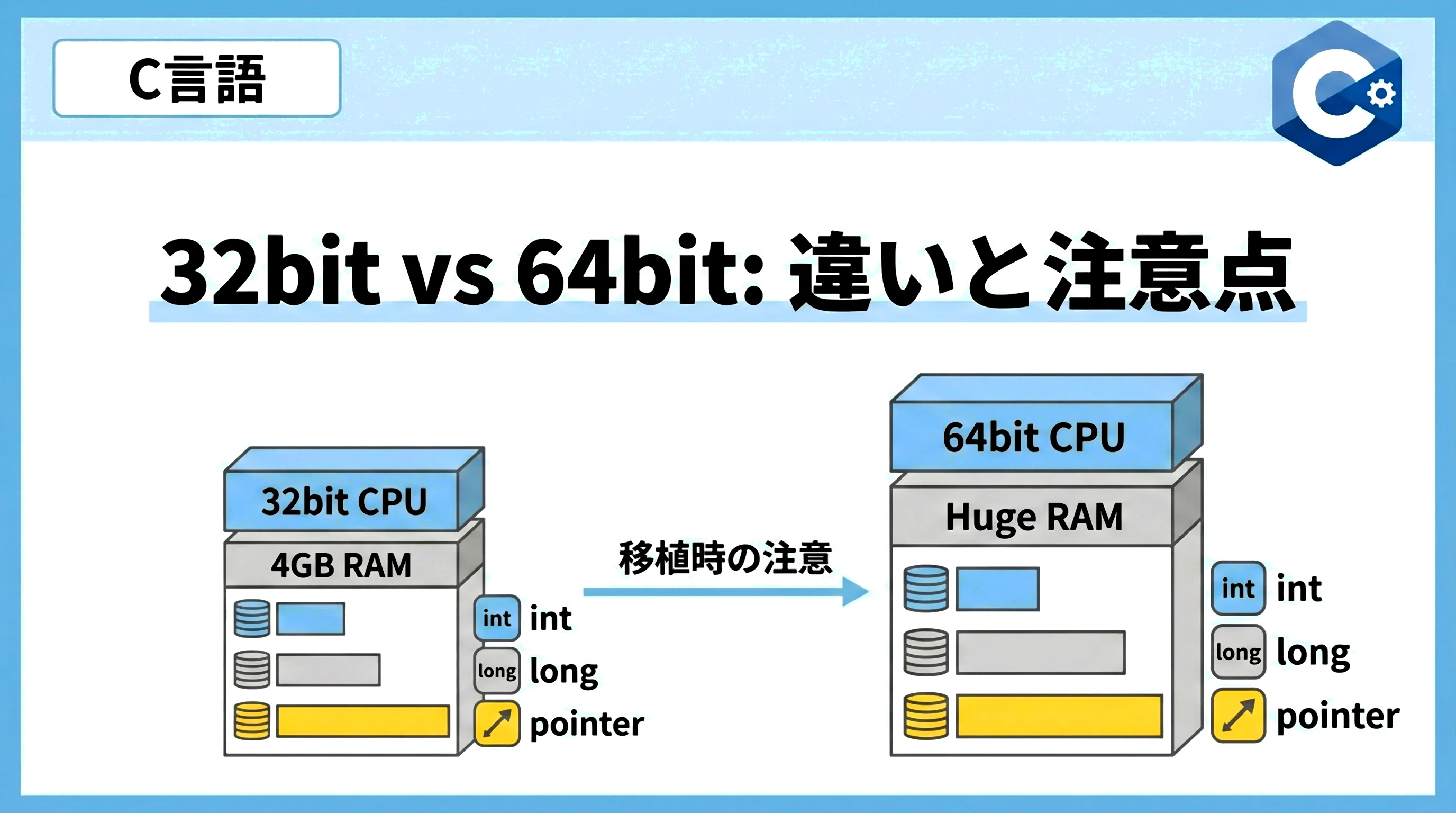
CPUにおける32bitと64bitの最大の違いは、一度に処理できるデータの幅(レジスタのサイズ)と、アクセス可能なメモリのアドレス空間の広さにあります。
32bitアーキテクチャでは、CPUの汎用レジスタが32ビット(4バイト)幅です。
これにより、一度に扱える整数の範囲は0から4,294,967,295(符号なしの場合)に制限されます。
また、メモリアドレスも32ビットで管理されるため、物理的にアクセス可能なメモリ容量は最大で4GB(2の32乗バイト)という「4GBの壁」が存在しました。
一方、64bitアーキテクチャでは、レジスタ幅が64ビット(8バイト)に拡張されています。
これにより、計算能力が向上するだけでなく、理論上は16EB(エクサバイト)という膨大なメモリ空間を扱うことが可能になります。
C言語においては、この「アドレス幅の拡張」がポインタ型のサイズに直結するため、コードの記述方法に細心の注意が必要となります。
C言語におけるデータモデルの違い
C言語の標準規格では、各データ型の具体的なバイト数は厳格に固定されていません。
代わりに、ターゲット環境に応じた「データモデル」が採用されています。
32bitから64bitへ移行する際、どの型のサイズが変更されるかは、このデータモデルによって決まります。
主要なデータモデル:ILP32、LP64、LLP64
現代の主要なOSでは、主に以下の3つのデータモデルが使われています。
- ILP32 (Int, Long, Pointer 32bit)
32bit OS(Windows 32bit、Linux 32bitなど)で一般的に採用されているモデルです。
int、long、ポインタがすべて4バイト(32ビット)です。
- LP64 (Long, Pointer 64bit)
Unix系OS(Linux 64bit、macOSなど)で採用されているモデルです。
intは4バイトのままですが、longとポインタが8バイト(64ビット)に拡張されます。
- LLP64 (Long Long, Pointer 64bit)
Windows 64bitで採用されているモデルです。
intだけでなくlongも4バイトのままで維持され、long longとポインタのみが8バイトになります。
データ型サイズ比較表
各環境における主要な型のサイズを以下の表にまとめます(単位:バイト)。
| 型 (Type) | 32bit (ILP32) | 64bit (Linux: LP64) | 64bit (Windows: LLP64) |
|---|---|---|---|
char | 1 | 1 | 1 |
short | 2 | 2 | 2 |
int | 4 | 4 | 4 |
long | 4 | 8 | 4 |
long long | 8 | 8 | 8 |
pointer | 4 | 8 | 8 |
size_t | 4 | 8 | 8 |
ここで特に注意すべきは、Windows 64bitでは long 型が4バイトのままであるという点です。
Linux環境で動作していたコードをWindows 64bitへ移植する際、long が8バイトであることを前提に書かれていると、データの切り捨てが発生し、重大なバグの原因となります。
ポインタのサイズ変化と型キャストの危険性
64bit化において最も影響が大きいのは、ポインタ型のサイズが4バイトから8バイトになることです。
32bit環境向けに書かれた古いC言語のコードでは、ポインタを int 型や long 型にキャストして保持しているケースが多々あります。
ポインタを整数型に代入する問題
32bit環境(ILP32)では、ポインタも int も4バイトであるため、以下のコードは一見正常に動作します。
// 32bit環境では動く可能性がある危険なコード
int addr = (int)malloc(100);しかし、これを64bit環境(LP64やLLP64)でコンパイル・実行すると、8バイトのポインタ情報が4バイトの整数型に押し込まれ、上位4バイトが消失します。
この結果、無効なメモリアドレスを参照することになり、セグメンテーションフォールト(強制終了)を引き起こします。
このような問題を回避するためには、ポインタを整数として扱う必要がある場合、<stdint.h> で定義されている intptr_t または uintptr_t を使用してください。
これらの型は、実行環境のポインタサイズに合わせて自動的に適切なサイズに調整されます。
メモリアライメントと構造体のパディング
32bitと64bitでは、メモリアライメント(境界調整)のルールも変化します。
CPUはメモリからデータを読み出す際、特定のバイト数の倍数のアドレスから読み出す方が効率が良い(あるいは、そうでないと読み出せない)という特性を持っています。
構造体サイズの変化
以下の構造体を例に考えます。
struct Sample {
int a; // 4バイト
long* b; // ポインタ
};32bit環境(ILP32)では:
int a: 4バイトlong* b: 4バイト- 合計: 8バイト
64bit環境(LP64)では:
int a: 4バイト- (パディング): 4バイト
long* b: 8バイト- 合計: 16バイト
64bit環境では、8バイトのポインタ b を8の倍数のアドレスに配置しようとするため、a の後ろに4バイトの空きスペース(パディング)が挿入されます。
その結果、データ型のサイズ以上にメモリ消費量が増大することがあります。
大量の構造体を配列で保持するようなプログラムでは、このパディングの影響を考慮してメンバの並び順を最適化することが推奨されます。
移植時に注意すべきポイント
32bit向けに開発されたレガシーなシステムを64bit環境へ移行する際、エンジニアが直面する具体的な注意点を解説します。
1. printf/scanf の書式指定子
データ型のサイズが変わるため、入出力の書式指定子も適切に変更する必要があります。
特に size_t 型の出力には %zu
size_t s = sizeof(int);
// 悪い例 (32bitなら動くが64bitでは警告が出る可能性がある)
printf("Size: %d\n", s);
// 正しい例
printf("Size: %zu\n", s);また、long 型の出力も、LP64環境(Linux 64bit)では %ld ですが、32bit環境の値をそのまま期待していると、出力結果が想定と異なる場合があります。
2. 暗黙の型変換と符号拡張
大きな型から小さな型への代入(例:long から int への代入)は、64bit環境では情報の欠落を招きます。
また、負の数を含む計算において、32bitの符号付き整数を64bitの符号なし整数に変換する際などに、符号拡張による意図しない値の変化が発生することがあります。
3. 標準ライブラリの活用
具体的なバイト数に依存したコードを書かないことが、移植性を高める近道です。
- バイト数を固定したい場合:
<stdint.h>のint32_t,int64_tを使用する。 - メモリサイズや添字を扱う場合:
size_tを使用する。 - ポインタの差分を扱う場合:
ptrdiff_tを使用する。
プログラムによるサイズ確認
実際に、自分の開発環境がどのようなデータモデルを採用しているかを確認するためのプログラムを作成してみましょう。
#include <stdio.h>
#include <stdint.h>
int main() {
printf("--- Data Type Size Checker ---\n\n");
// 基本的なデータ型のサイズを表示
printf("char : %zu byte(s)\n", sizeof(char));
printf("short : %zu byte(s)\n", sizeof(short));
printf("int : %zu byte(s)\n", sizeof(int));
printf("long : %zu byte(s)\n", sizeof(long));
printf("long long : %zu byte(s)\n", sizeof(long long));
printf("pointer : %zu byte(s)\n", sizeof(void*));
printf("size_t : %zu byte(s)\n", sizeof(size_t));
printf("\n--- Pointer Arithmetic ---\n");
int array[2] = {10, 20};
int *p1 = &array[0];
int *p2 = &array[1];
// ポインタ間の差を表示
printf("Address of p1: %p\n", (void*)p1);
printf("Address of p2: %p\n", (void*)p2);
printf("Difference as ptrdiff_t: %td\n", (intptr_t)p2 - (intptr_t)p1);
return 0;
}実行結果(64bit Linux環境の場合)
--- Data Type Size Checker ---
char : 1 byte(s)
short : 2 byte(s)
int : 4 byte(s)
long : 8 byte(s)
long long : 8 byte(s)
pointer : 8 byte(s)
size_t : 8 byte(s)
--- Pointer Arithmetic ---
Address of p1: 0x7ffc8e3a1a30
Address of p2: 0x7ffc8e3a1a34
Difference as ptrdiff_t: 4上記の出力結果から、この環境が LP64モデル(longとpointerが8バイト)であることがわかります。
ポインタ間の物理的なアドレス差が4バイト(int のサイズ分)であることも確認できます。
パフォーマンスへの影響
64bit環境は32bit環境よりも常に高速であるとは限りません。
ポインタのサイズが2倍になるということは、ポインタを多用するプログラムではメモリ消費量が増え、CPUキャッシュのヒット率が低下する可能性があることを意味します。
一方で、64bit CPUはより多くのレジスタを備えており、関数の引数渡しをスタックではなくレジスタ経由で行うなど、最適化が進んでいるため、複雑な計算を行うプログラムでは劇的なパフォーマンス向上が期待できます。
また、64bit環境ではSSEやAVXといった拡張命令セットが標準で利用可能であることが多いため、浮動小数点演算の高速化も恩恵の一つです。
まとめ
C言語における32bitと64bitの違いは、単なる「扱える数値の大きさ」の違いに留まりません。
- データモデルの違い(ILP32 / LP64 / LLP64)により、
long型やポインタ型のサイズがOSごとに異なります。 - ポインタの8バイト化により、従来の
int型へのキャストは危険な行為となりました。 - メモリアライメントの変化により、構造体のサイズが増大し、メモリレイアウトが変わる可能性があります。
- 移植性を高めるためには、
<stdint.h>の固定幅整数型やsize_tを積極的に活用することが不可欠です。
現代のソフトウェア開発において、32bit環境を完全に切り捨てることは難しい場合もありますが、64bitの特性を正しく理解し、アーキテクチャに依存しない堅牢なコードを記述するスキルは、プロフェッショナルなC言語エンジニアにとって必須の教養と言えるでしょう。
この記事で紹介した知識を基に、より安全で効率的なプログラミングを目指してください。