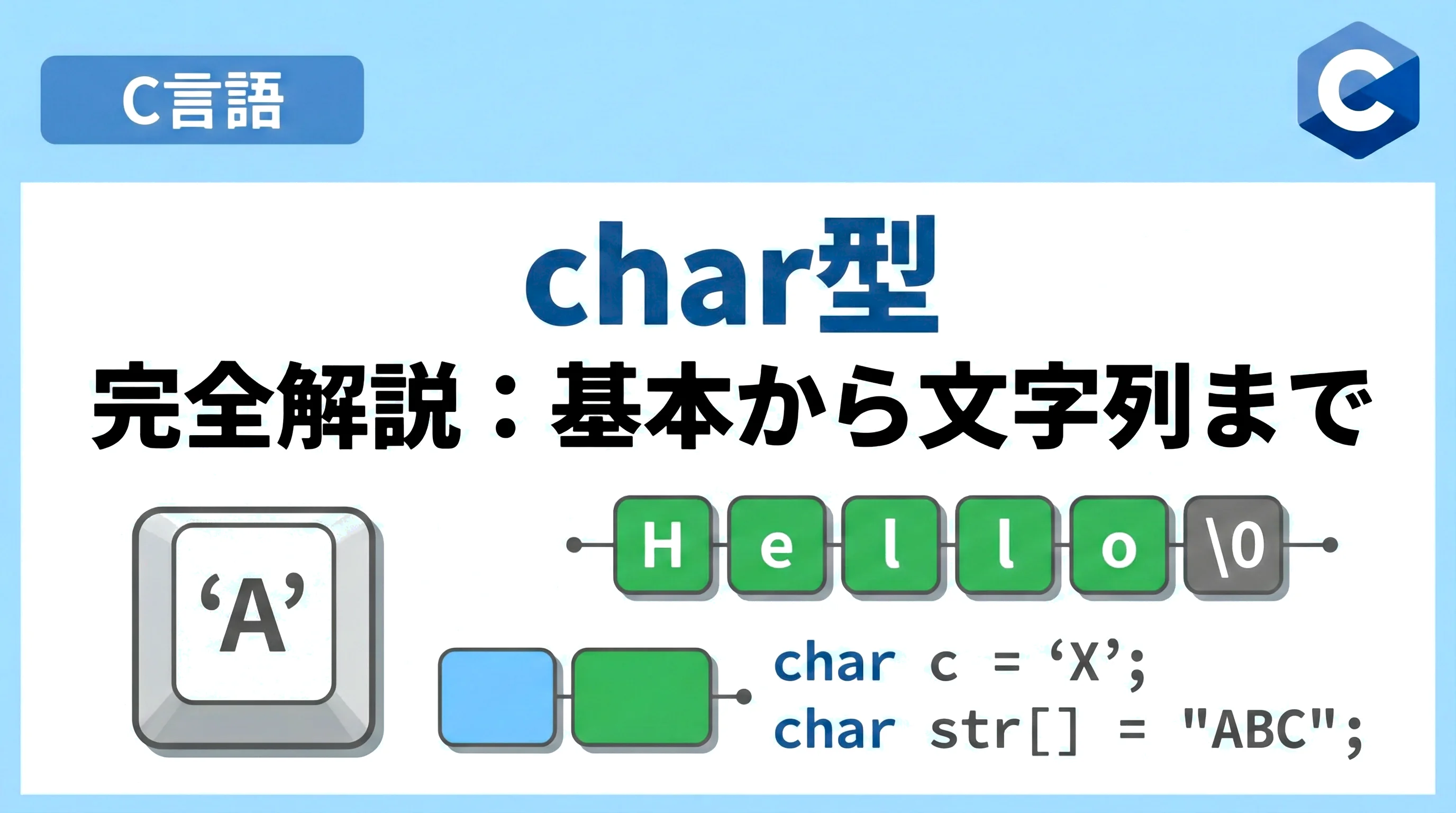
C言語におけるプログラミングを学ぶ上で、避けて通れない最も基本的なデータ型の一つが char型 です。
コンピューターは内部的にすべてのデータを数値として処理していますが、人間が理解できる「文字」を扱うために設計されたのがこの型です。
C言語の初心者にとって、char型は単に文字を格納する変数に見えるかもしれませんが、その実態は 1バイトの整数型 であり、数値と文字の架け橋となる重要な役割を担っています。
この記事では、char型の定義やメモリ上の仕組みといった基礎知識から、宣言・初期化の方法、さらには複数の文字を扱う「文字列」の概念まで、実戦で役立つ知識を網羅的に解説します。
C言語の根幹を支えるchar型をマスターすることで、データの入出力やテキスト処理のスキルを飛躍的に向上させることができるでしょう。
char型とは?その正体とメモリ上の仕組み
C言語の char 型は、一般的に 文字 (Character) を表現するためのデータ型 として定義されています。
しかし、コンピューターの仕組みを深く理解するためには、char型が「最小単位の整数型」であることを知っておく必要があります。
1バイトの整数としてのchar型
C言語の規格において、char型のサイズは 必ず1バイト (8ビット) であることが保証されています。
1バイトで表現できる値の範囲は256通りです。
このため、char型の正体は「-128から127」または「0から255」の範囲の数値を保持する小さな整数型に過ぎません。
私たちが char c = 'A'; と記述したとき、コンピューターは「A」という形をそのままメモリに保存するのではなく、対応する数値(ASCIIコードなど)をバイナリデータとして格納します。
例えば、アルファベットの「A」は数値の 65 として扱われます。
ASCIIコードと文字の対応
コンピューターが数値と文字を変換するために使用する対応表を「文字コード」と呼びます。
C言語において最も標準的に利用されるのが ASCII (American Standard Code for Information Interchange) です。
主要な文字とASCII値の対応は以下の通りです。
| 文字 | ASCII値 (10進数) |
|---|---|
| ‘0’ – ‘9’ | 48 – 57 |
| ‘A’ – ‘Z’ | 65 – 90 |
| ‘a’ – ‘z’ | 97 – 122 |
| ‘ ‘ (スペース) | 32 |
このように、char型の中身が整数であるため、C言語では 文字に対して足し算や引き算を行うことが可能 です。
例えば、’A’ に 1 を足すと ‘B’ になり、’a’ から ‘A’ を引くことで大文字と小文字のオフセット(32)を計算するといった処理が頻繁に行われます。
char型の宣言と初期化の基本
char型を使用するには、他の変数と同様に宣言と初期化が必要です。
文字を扱う際、C言語特有のルールとして シングルクォーテーション (‘) の使用が挙げられます。
基本的な宣言方法
変数の宣言は、型名の後に変数名を記述します。
char alphabet;
char symbol;文字定数による初期化
char型の変数に文字を代入する場合、その文字を '' (シングルクォーテーション) で囲みます。
char grade = 'A';
char initial = 'S';ここで注意が必要なのは、ダブルクォーテーション (“) を使用してはいけない という点です。
C言語において "A" は「文字列(char型の配列)」を指し、単一の char 型変数に代入しようとするとコンパイルエラーや予期せぬ動作の原因となります。
数値による初期化
char型は整数型であるため、直接数値を代入することも可能です。
char letter = 65; // 'A' と同じ意味このコードを実行すると、letter には文字 ‘A’ が格納されます。
ただし、可読性の観点からは、文字を扱いたい場合はリテラル(’A’)を直接記述するのが一般的です。
char型の入出力方法
プログラムで文字を扱う場合、標準入出力関数である printf や scanf を使用します。
printf関数での出力
文字を表示するには、書式指定子 %c を使用します。
また、その文字の内部的な数値を知りたい場合は %d を使用します。
#include <stdio.h>
int main(void) {
char my_char = 'Z';
printf("文字としての表示: %c\n", my_char);
printf("数値としての表示: %d\n", my_char);
return 0;
}scanf関数での入力
ユーザーから1文字入力を受け取る場合も %c を使用します。
char input;
printf("1文字入力してください: ");
scanf("%c", &input);
printf("入力された文字は %c です。\n", input);注意点として、scanf で %c を使用する場合、直前の入力で残った改行文字(’\n’)を読み込んでしまうことがあります。
これを防ぐためには、scanf(" %c", &input); のように書式指定子の前に半角スペースを入れることで、空白文字をスキップするテクニックがよく使われます。
エスケープシーケンスの活用
キーボードから直接入力できない特殊な文字や、画面表示を制御する文字を表現するために エスケープシーケンス が用意されています。
これらはバックスラッシュ(環境によっては円記号 \)から始まる2文字の組み合わせで表現されますが、内部的には 1文字(1バイト) として扱われます。
代表的なエスケープシーケンスを以下の表にまとめます。
| シーケンス | 意味 | 用途 |
|---|---|---|
| \n | 改行 (Newline) | カーソルを次の行の先頭に移動する |
| \t | 水平タブ (Tab) | 一定間隔の空白を挿入する |
| ‘ | シングルクォーテーション | 文字としての ‘ を表現する |
| “ | ダブルクォーテーション | 文字列中での ” を表現する |
| \ | バックスラッシュ | \ 記号そのものを表現する |
| \0 | ヌル文字 (Null) | 文字列の終端を示す(極めて重要) |
例えば、シングルクォーテーション自体を変数に格納したい場合は、char quote = '''; と記述します。
signed char と unsigned char の違い
char型には、符号の扱いによって3つの異なる種類が存在します。
これは、char型を「文字」としてではなく「数値(データ)」として扱う場合に非常に重要になります。
- char: 環境(コンパイラ)によって、signed(符号あり)かunsigned(符号なし)のどちらかとして扱われます。
- signed char: 明示的に符号ありとして宣言。範囲は -128 ~ 127。
- unsigned char: 明示的に符号なしとして宣言。範囲は 0 ~ 255。
なぜ使い分けるのか?
通常の英数字を扱うだけであれば char 型で十分です。
しかし、画像データや通信プロトコルなどの バイナリデータ を扱う場合、負の値を考慮したくないことが多いため、unsigned char が多用されます。
逆に、小さな数値を計算に使い、負の値も保持したい場合には signed char を指定します。
C言語の標準仕様では、単なる char がどちらとして振る舞うかは実装に依存するため、数値計算に使用する場合は明示的に指定するのが安全なプログラミングの秘訣です。
C言語における文字列の正体
C言語には、JavaやPythonのような独立した「String型」は存在しません。
文字列は、char型の配列 として表現されます。
これがC言語の学習において最大の壁の一つとなる「文字列」の正体です。
文字列の構造とヌル文字
文字列は、複数の文字がメモリ上に連続して並んだものです。
しかし、どこが文字列の終わりなのかをコンピューターに教える必要があります。
そのため、C言語では文字列の最後に必ず ヌル文字 (\0) を配置するというルールがあります。
例えば、”Hello” という5文字の文字列を格納するには、最低でも 6バイト(’H’, ‘e’, ‘l’, ‘l’, ‘o’, ‘\0’)のメモリ領域が必要です。
文字列の宣言と初期化
文字列(char型の配列)を宣言・初期化する方法はいくつかあります。
// 方法1: 配列サイズを明示
char str1[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
// 方法2: 文字列リテラルを使用(自動的に \0 が付与される)
char str2[] = "Hello";
// 方法3: ポインタを使用(読み取り専用となることが多い)
const char *str3 = "Hello";char str2[] = "Hello"; という書き方は非常に便利で、コンパイラが自動的に文字数を数え、終端の \0 を含めたサイズ(この場合は6要素)の配列を確保してくれます。
char配列と文字列操作の注意点
char型の配列で文字列を扱う際、初心者が最も陥りやすい罠が 代入と比較 です。
代入は「=」ではできない
一度宣言したchar型の配列に対し、後から別の文字列を「=」で代入することはできません。
char name[20];
// name = "Sato"; // これはエラー!配列の内容を変更するには、strcpy 関数(string.h ヘッダが必要)を使用するか、一文字ずつ代入する必要があります。
#include <string.h>
strcpy(name, "Sato"); // これが正しい方法比較は「==」ではできない
同様に、文字列同士が同じかどうかを == で判定することはできません。
== は「メモリ上のアドレス」が同じかどうかを比較してしまうからです。
内容を比較するには strcmp 関数を使用します。
if (strcmp(str1, str2) == 0) {
// 文字列が一致した場合の処理
}strcmp は、文字列が等しい場合に 0 を返すという点に注意してください。
標準ライブラリ <string.h> の活用
char型およびその配列を効率的に扱うために、C言語には string.h という便利なライブラリが用意されています。
代表的な関数をいくつか紹介します。
strlen: 文字列の長さを取得
文字列の中に何文字入っているかを返します。
ただし、終端の \0 はカウントに含まれません。
size_t len = strlen("Apple"); // len は 5strcat: 文字列の結合
既存の文字列の後ろに、別の文字列を繋げます。
char base[20] = "Visual";
strcat(base, " Studio"); // base は "Visual Studio" になるsprintf: 書式付き文字列の作成
数値を文字列に変換したい場合に非常に便利です。
char buffer[50];
int age = 25;
sprintf(buffer, "私は %d 歳です。", age);これらの関数を使用する際は、常に 配列のサイズ(バッファサイズ)を越えないか を意識する必要があります。
バッファオーバーフローは、プログラムの強制終了やセキュリティ脆弱性の大きな原因となります。
char型とポインタの関係
C言語の中級ステップへと進むためには、char型 と ポインタ の関係を理解する必要があります。
文字列リテラル(”Hello” など)は、プログラムのメモリ上の「静的領域」に配置され、その先頭アドレスを指すポインタとして扱うことができます。
const char *message = "Welcome";
printf("%s\n", message);このコードにおいて、message は文字列そのものを保持しているのではなく、’W’ が格納されている メモリ上の番地(アドレス) を保持しています。
配列とポインタの違い
- char str[] = “Hi”; : メモリ上に書き換え可能な領域を確保し、そこに “Hi” をコピーする。
- char *ptr = “Hi”; : 書き換え不可(読み取り専用)な領域にある “Hi” の場所を指す。
多くの場合、文字列を加工する必要があるときは配列を使用し、関数に文字列を渡す際や固定のメッセージを表示する際はポインタを使用します。
最新のC言語における文字の扱い
現代のプログラミング環境では、英語圏のASCIIコードだけでは不十分であり、日本語などの多言語を扱うための Unicode (UTF-8) が標準となっています。
UTF-8とchar型の関係
UTF-8は、1文字を1バイトから4バイトの可変長で表現します。
C言語の char 型は1バイトであるため、日本語の「あ」を格納しようとすると、3バイト分(char 3つ分)の領域を消費します。
char jp[] = "あ";
printf("サイズ: %zu\n", sizeof(jp)); // ヌル文字含め 4 と表示されることが多いワイド文字 (wchar_t)
日本語のような多バイト文字を「1文字」として固定長で扱いたい場合、wchar_t 型が用意されています。
しかし、現代のWeb開発やシステム開発では、互換性の高い char 型配列を用いたUTF-8処理が主流となっています。
C11規格以降では、u8 プレフィックスを用いたUTF-8リテラルの明示や、char16_t, char32_t といったより厳格な型も導入されており、用途に応じた使い分けが進んでいます。
char型を使用する上でのベストプラクティス
安全で効率的なプログラムを書くために、以下のポイントを心がけましょう。
- バッファサイズの確保: 文字列を格納する配列は、常に「最大文字数 + 1(ヌル文字分)」以上のサイズを確保してください。
- 初期化の徹底: 宣言時に
char str[10] = "";のように初期化することで、ゴミデータによるバグを防げます。 - 関数の安全性:
strcpyやstrcatの代わりに、コピーする長さを制限できるstrncpyやstrncatを検討してください(または環境に応じた安全な関数)。 - 整数としての利用: 0~100程度の小さな数値を扱う場合は、
int型(通常4バイト)よりもchar型(1バイト)を使うことで、メモリ消費を節約できます(大量のデータを扱う構造体などで有効です)。
まとめ
char型 は、C言語において文字と数値を繋ぐ非常に柔軟で強力なデータ型です。
その本質が「1バイトの整数」であることを理解すれば、文字コードの仕組みや文字列の構造、さらにはメモリの効率的な使い方までが見えてきます。
今回のポイントを振り返りましょう。
charは1バイトの整数型であり、ASCIIコードなどで文字を表現する。- 単一の文字は
''、文字列は""で囲む。 - 文字列は「char型の配列」であり、末尾には必ず ヌル文字 (\0) が必要。
- 文字列の操作には
==や=ではなく、strcmpやstrcpyなどの専用関数を使う。 - バイナリデータを扱う際は
unsigned charを活用する。
char型を正しく使いこなすことは、メモリ管理を重視するC言語プログラミングの第一歩です。
基礎をしっかりと固めることで、より複雑なデータ構造やポインタ制御、多言語対応といった高度なトピックにもスムーズに挑戦できるようになるでしょう。
ぜひ、実際のコードを書きながらその挙動を体感してみてください。