C言語は、ハードウェアに近いレイヤーで効率的なメモリ制御ができるプログラミング言語として、数十年もの間、システム開発や組み込み開発の第一線で活用されています。
その中で、数値を扱う「整数型」には複数のバリエーションが存在しますが、今回詳しく解説するのはshort型(短精度整数型)です。
short型は、基本となる int 型よりも消費メモリを抑えることができるデータ型として知られていますが、その特性を正しく理解していないと、思わぬバグやパフォーマンスの低下を招くことがあります。
本記事では、short型の定義からサイズ、表現できる範囲、書式指定子の使い方、そして int 型との使い分けまで、プロの視点で徹底的に解説します。
short型の基礎知識と定義
C言語における short 型は、正式には short int と呼ばれる整数型の一種です。
プログラム内では単に short と記述されることが一般的ですが、これらは全く同じ意味を持ちます。
C言語の言語規格(C99、C11、C17、そして最新のC23)において、各整数型のサイズは「具体的なバイト数」が厳格に定められているわけではなく、「型のサイズの最小順序」が規定されています。
具体的には、以下の順序を維持する必要があります。
char ≦ short ≦ int ≦ long ≦ long long
多くの現代的なプラットフォーム(x86_64アーキテクチャやARMアーキテクチャなど)では、short型は2バイト(16ビット)として実装されています。
一方で、int 型は4バイト(32ビット)であることが多いため、short型は文字通り「短い整数」として機能します。
符号付きと符号なし
short型には、正の数と負の数の両方を扱える signed short (通常は単に short と書く)と、0以上の正の数のみを扱う unsigned short があります。
メモリ効率を最大限に高めたい場合、扱う数値の範囲に応じてこれらを適切に選択することが重要です。
short型のサイズと表現可能な数値範囲
プログラミングにおいて、扱うデータがどの程度の大きさになるかを把握することは、メモリの節約だけでなくバッファオーバーフローやオーバーフローの防止に直結します。
一般的なシステムにおけるshort型のスペックは以下の通りです。
| 型名 | バイト数 | ビット数 | 最小値 | 最大値 |
|---|---|---|---|---|
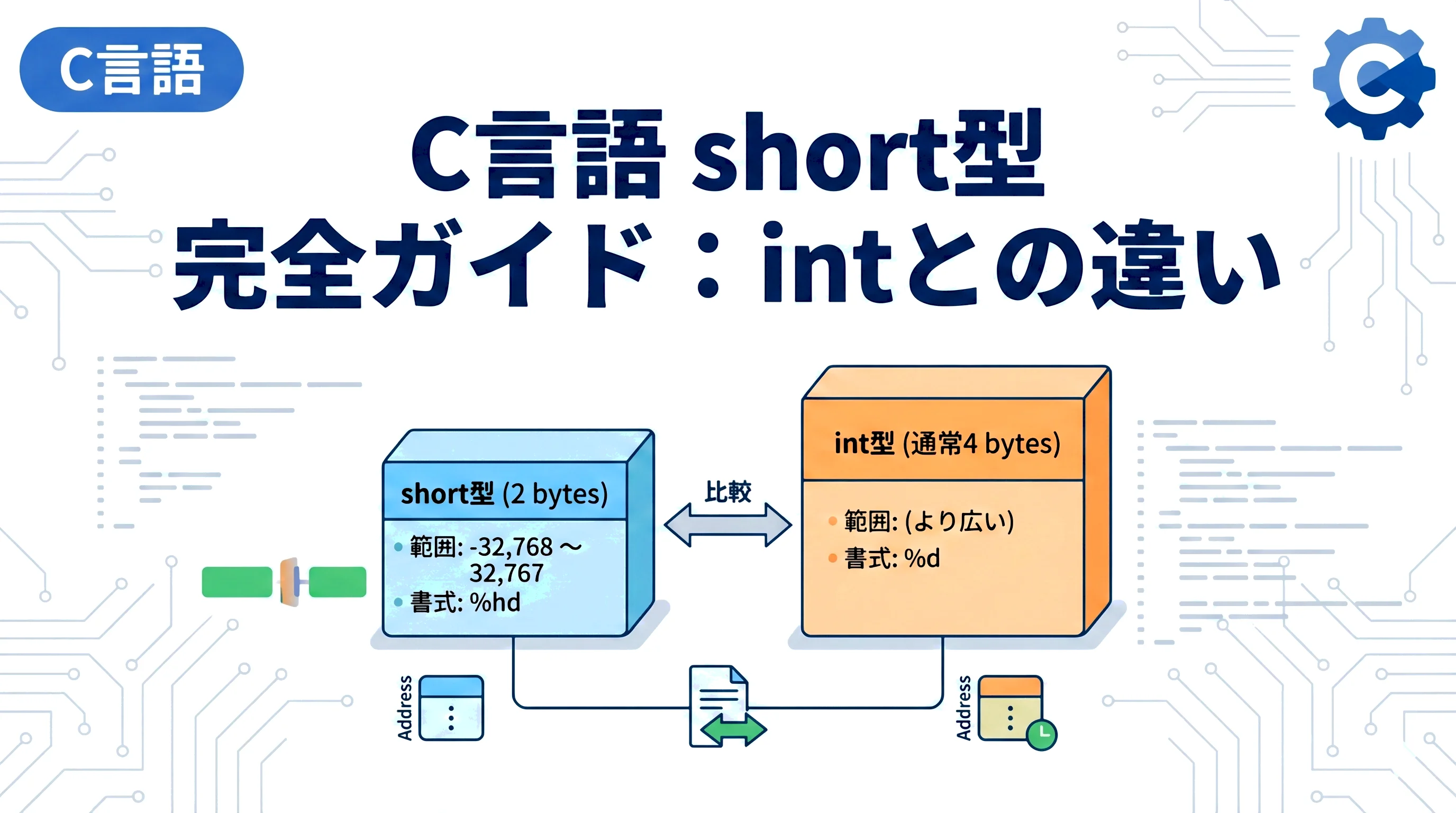
| short (signed short) | 2バイト | 16ビット | -32,768 | 32,767 |
| unsigned short | 2バイト | 16ビット | 0 | 65,535 |
C言語では、これらの上限値や下限値を確認するために、標準ライブラリの <limits.h> ヘッダーが用意されています。
このヘッダーをインクルードすることで、SHRT_MIN や SHRT_MAX、USHRT_MAX といった定数を利用でき、環境に依存しない安全なコードを記述することが可能です。
規格上の最小要件
ISO/IEC 9899(C言語規格)によれば、short型は少なくとも16ビットの精度を持つことが保証されています。
そのため、どのようなC言語コンパイラを使用しても、少なくとも -32,767 から 32,767 までの範囲は安全に扱えると考えられます(多くの実装では負の数の表現に2の補数を用いるため、最小値は -32,768 となります)。
short型とint型の決定的な違い
初心者から中級者にかけて多くの方が抱く疑問が、「なぜすべて int 型で済ませてはいけないのか?」という点です。
ここでは、short型と int 型の主な違いを3つの観点から比較します。
1. メモリ消費量
最も明確な違いは、1つの変数が占有するメモリ容量です。
short:2バイトint:4バイト(多くの環境)
単一の変数ではわずか2バイトの差ですが、数万、数億の要素を持つ「配列」を扱う場合、この差は無視できません。
例えば、要素数1,000,000の整数配列を作成する場合、int では約4MB必要ですが、short なら約2MBで済みます。
メモリリソースが極めて限定的な組み込みシステムや、大規模な画像データ・音声データのバッファ処理において、short型の採用は非常に大きなメリットとなります。
2. 演算速度の逆転現象
意外かもしれませんが、short型の方が int 型よりも処理が遅くなるケースがあります。
現代のCPU(32ビットまたは64ビットプロセッサ)は、自身のレジスタサイズ(ワードサイズ)に合わせてデータを処理するのが最も得意です。
32ビットCPUにとって、2バイトのデータを読み書きする場合、位置を調整するためのビットシフトやマスク処理といった余計な命令が発生することがあります。
したがって、メモリ容量に余裕があるデスクトップアプリケーションなどで、単なるループカウンターとして変数を使うのであれば、int 型を選択するのがパフォーマンス的に最適です。
3. 数値の飽和とオーバーフロー
int 型は約21億までの数値を扱えますが、short 型は約3万までです。
プログラムの拡張によって扱う数値が大きくなった際、short型では容易にオーバーフロー(桁あふれ)が発生します。
符号付き整数のオーバーフローはC言語の仕様上「未定義動作」となり、予測不能なバグの原因となるため、将来的な数値の増大が見込まれる箇所には short型を避けるべきです。
short型の書式指定子(printf/scanf)
標準入出力関数である printf や scanf を使用する際、型に応じた正しい「書式指定子」を指定する必要があります。
printf関数での出力
printf でshort型の値を表示する場合、%hd を使用します。
%d:int型%hd:short型(hはhalfの略)%hu:unsigned short型
実際には、printf に渡される際にshort型の引数は int 型に自動的に格上げ(プロモーション)されるため、%d を使っても正しく表示されることが多いですが、コードの可読性と厳密性の観点から %hd を使うのが作法です。
scanf関数での入力
一方で、scanf を使用して値を格納する場合は、必ず %hd を使用しなければなりません。
short val;
scanf("%hd", &val); // 正しいもしここで %d を使用してしまうと、scanf は 4バイトのデータとしてメモリに書き込もうとします。
しかし、変数 val には2バイト分しか領域がないため、隣接するメモリ領域を破壊(メモリ破壊)してしまい、プログラムがクラッシュする重大な原因となります。
整数昇格(Integer Promotion)という罠
C言語には整数昇格(Integer Promotion)という重要なルールがあります。
これは、char や short といった int よりも小さい型が式の中で評価される際、自動的に int 型(または unsigned int 型)に変換される仕組みです。
例えば、以下のコードを見てみましょう。
short a = 30000;
short b = 10000;
int c = a + b;この演算において、a と b は一旦 int 型に変換されてから加算が行われます。
その結果、中間結果が short の範囲(32,767)を超えていたとしても、int の範囲内であれば正しく計算されます。
しかし、最終的に結果を short 型の変数に代入し直す場合、そこで再び型が切り詰められ、意図しない値になるリスクがあります。
この仕様を理解しておくことは、特にビット演算や条件比較において論理バグを防ぐために不可欠です。
stdint.h と int16_t の活用
近年(特にC99以降)のモダンなC言語開発では、プラットフォームごとにサイズが曖昧になりがちな short や int の代わりに、<stdint.h> で定義されている固定幅整数型を使用することが推奨されています。
int16_t: 符号付き16ビット整数(shortに相当)uint16_t: 符号なし16ビット整数(unsigned shortに相当)
これらを使用することで、どのOSやコンパイラを使っても「必ず16ビット(2バイト)」であることが保証されます。
通信プロトコルの実装やバイナリファイルの読み書きなど、バイト単位の厳密な制御が求められる場面では、short ではなく stdint.h の型を使うのが現在のデファクトスタンダードです。
short型が実際に使われる具体的な場面
理論的な違いを学んだところで、実務においてどのようなシーンでshort型が選ばれるのか、具体例を挙げます。
1. 組み込みデバイスの制御
マイコン(MCU)などのリソースが非常に乏しい環境では、RAMが数KBしかないことも珍しくありません。
センサーから取得した10ビットや12ビットの値を保持する際、int(4バイト)を使うのは無駄が多いため、2バイトの short を多用してメモリを節約します。
2. メディアデータの処理
デジタル音声(WAVファイルなど)のサンプリングデータは、多くの場合「16bitリニアPCM」形式です。
この場合、1つのサンプルがちょうど16ビット(2バイト)であるため、C言語上では short 型の配列としてデータを読み込むのが最も自然で効率的です。
画像処理における各ピクセルのチャンネル値(特に医療用画像や高深度画像など)でも、2バイト整数が使われることがあります。
3. ネットワークパケットの構造体
TCP/IPなどのネットワークプロトコルにおいて、ポート番号の指定は16ビット(0~65,535)と定められています。
そのため、ソケットプログラミングにおける構造体定義(例:sockaddr_in)では、ポート番号を保持するために unsigned short 型(または uint16_t)が利用されています。
実装時の注意点とTips
short型を安全に使用するためのテクニックをいくつか紹介します。
符号の有無による振る舞いの違い
short(符号付き)をより大きな型である int に代入する場合、符号拡張(Sign Extension)が行われます。
例えば、16進数で 0xFFFF という値を持つ short 変数は、10進数では -1 です。
これを int に代入すると 0xFFFFFFFF(-1)となります。
一方、unsigned short で 0xFFFF(65,535)を int に代入すると、そのまま 0x0000FFFF(65,535)となります。
ビット操作を行う際は、この符号拡張の挙動を意識しないと思わぬバグに繋がります。
キャストの明示
int 型の結果を short 型に代入する際は、コンパイラによる警告を避けるため、および意図的な切り捨てであることを示すために明示的なキャストを行うことが推奨されます。
int bigValue = 40000;
short smallValue = (short)bigValue; // 意図的なキャストサンプルプログラムで動作を確認する
実際にshort型の挙動を確認するためのコード例を見てみましょう。
このコードでは、サイズ、範囲、およびオーバーフローの挙動を確認できます。
#include <stdio.h>
#include <limits.h>
int main(void) {
short s_val = 32767;
unsigned short us_val = 65535;
printf("shortのサイズ: %zu バイト\n", sizeof(short));
printf("shortの最大値: %hd\n", SHRT_MAX);
printf("unsigned shortの最大値: %hu\n\n", USHRT_MAX);
// オーバーフローの実験
printf("--- オーバーフローの挙動 ---\n");
printf("最大値 32767 に 1 を加算: ");
s_val = s_val + 1;
printf("%hd\n", s_val); // 一般的に -32768 にループする
printf("unsigned最大値 65535 に 1 を加算: ");
us_val = us_val + 1;
printf("%hu\n", us_val); // 0 に戻る
return 0;
}このプログラムを実行すると、short 型の限界値を超えた際に数値がどのように変化するかを確認できます。
特に符号付き整数のオーバーフローは、環境によっては異なる挙動を示す可能性があるため、理論上の最大値を超えないような設計が常に求められます。
まとめ
C言語における short 型は、メモリ効率を追求するプログラミングにおいて非常に強力な武器となります。
16ビットという限られたサイズの中で数値を扱うため、int 型と比較して以下のような特徴があります。
- 省メモリ性:大量のデータ配列やリソースの少ない組み込み環境で真価を発揮する。
- 表現範囲:符号付きで -32,768 ~ 32,767。これを超える場合は
intやlongが必要。 - 書式指定子:
printfやscanfでは%hd(符号なしは%hu)を使用する。 - パフォーマンス:メモリ節約にはなるが、CPUの演算速度としては
intの方が有利な場合が多い。
現代のシステム開発では、移植性を高めるために int16_t などの固定幅整数型を併用することも一般的ですが、その背後にある short 型の仕組みを理解しておくことは、C言語エンジニアとしての基礎体力を養うことと同義です。
適切なデータ型を選択することは、プログラムの「堅牢性」「効率性」「可読性」を左右します。
扱うデータの性質を見極め、「本当にその変数は short で十分か、それとも int にすべきか」を常に問いかけながら設計を進めていきましょう。