C言語におけるデータ型の中でも、char 型は文字を扱うための基本的な型として知られていますが、その中でも 符号なし整数として扱う unsigned char 型 は、システムプログラミングや画像処理、通信プロトコルの実装など、多岐にわたる分野で極めて重要な役割を果たします。
単なる文字の格納に留まらず、「1バイトのバイナリデータ」を正確に制御するための最小単位として機能するため、その特性を深く理解することは効率的で安全なプログラムを書く上で欠かせません。
本記事では、unsigned char の基礎知識から、他の型との違い、具体的な活用シーンまで、テクニカルな視点で詳しく解説します。
unsigned char の基本概念
C言語における unsigned char とは、1バイト (通常8ビット) のメモリ領域を専有し、符号(プラス・マイナス)を持たない整数を格納するためのデータ型です。
C言語の標準規格では、char 型は少なくとも8ビットのサイズを持つことが保証されており、現代のほとんどのシステムにおいて 1バイト = 8ビット として扱われます。
通常、char 型は「文字」を格納するために使われますが、コンピュータ内部ではすべてのデータは数値として処理されます。
例えば、’A’ という文字は ASCIIコードで 65 という数値に対応しています。
unsigned char は、この数値を 0 以上の正数としてのみ扱うことを明示的に宣言するものです。
C言語には char、signed char、unsigned char という3つの「文字型」が存在します。
これらはすべて同じサイズ(1バイト)ですが、コンパイラによって char が符号ありとして扱われるか、符号なしとして扱われるかが異なるため、バイナリデータを扱う際には明示的に unsigned char を使用するのがベストプラクティスとされています。
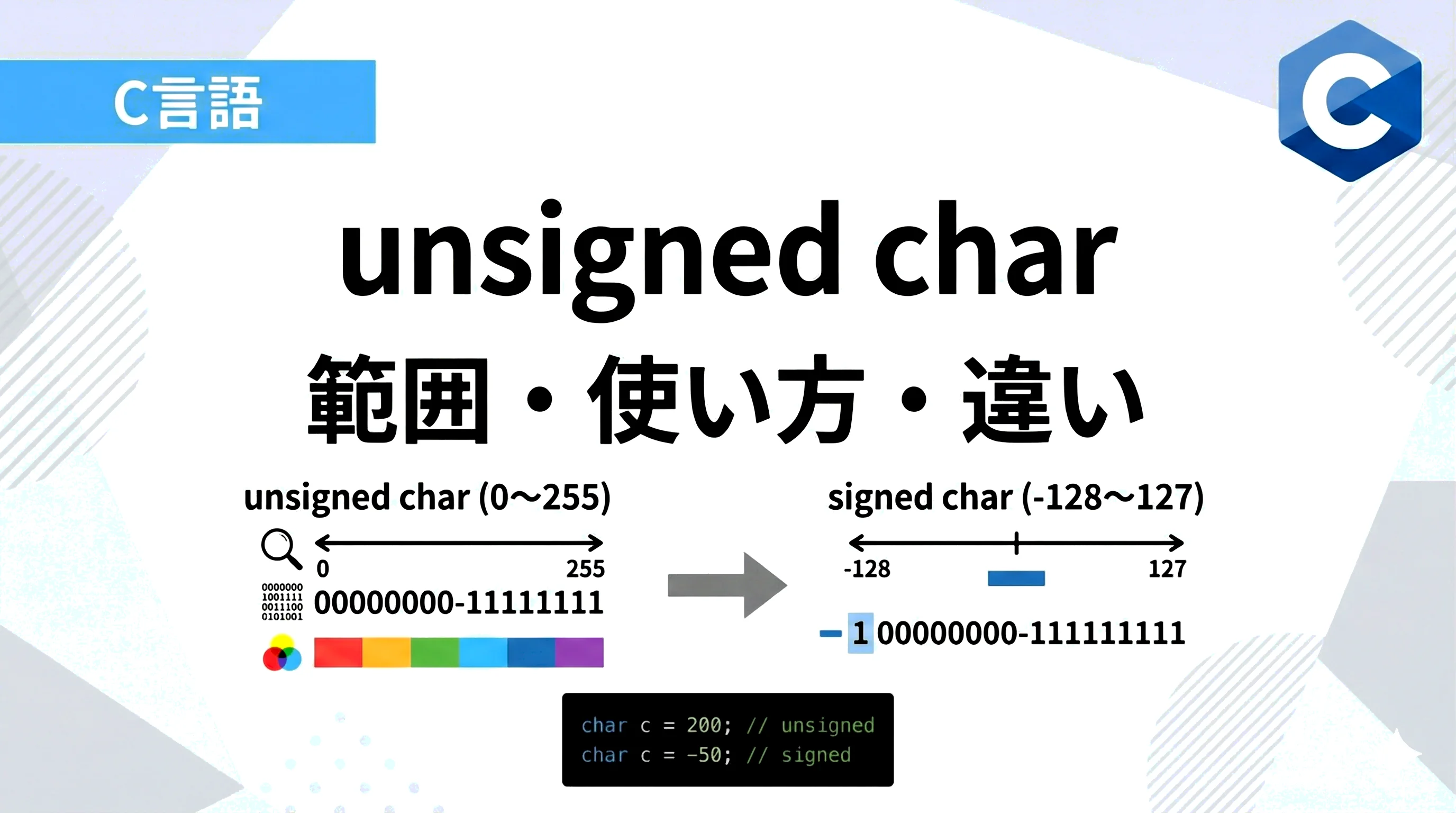
unsigned char の範囲とメモリ表現
unsigned char が保持できる値の範囲は、ビット数に依存します。
標準的な8ビット環境において、その範囲は以下のようになります。
| 型 | ビット数 | 最小値 | 最大値 |
|---|---|---|---|
| unsigned char | 8bit | 0 | 255 |
| signed char | 8bit | -128 | 127 |
8ビットのメモリ領域では、2の8乗である 256 通りの状態を表現できます。
unsigned char の場合、負の値を考慮する必要がないため、すべてのビットを数値の大きさを表すために使用します。
そのため、00000000 (10進数の0) から 11111111 (10進数の255) までの範囲をカバーできるのです。
一方、signed char では最上位ビット (MSB: Most Significant Bit) を符号ビット(0なら正、1なら負)として使用するため、正の方向に表現できる範囲が半分になります。
このように、「負の値が必要ないデータ(画像の色成分、パケットのサイズなど)」を扱う場合には、unsigned char が最適です。
char と signed char、unsigned char の決定的な違い
C言語の初心者が混同しやすいポイントの一つに、単なる char と signed / unsigned char の使い分けがあります。
これらはすべて1バイトのサイズを持ちますが、言語仕様上の扱いは明確に区別されています。
コンパイラ依存の char 型
驚くべきことに、C言語の標準規格では、char 型が符号付きか符号無しかを規定していません。
これは 実装定義 (Implementation-defined) と呼ばれる仕様であり、使用するコンパイラやCPUアーキテクチャによって挙動が変わります。
例えば、x86系アーキテクチャの多くのコンパイラでは char は signed として扱われますが、ARM系など一部の環境ではデフォルトで unsigned として扱われることがあります。
移植性の問題
プログラムを異なるプラットフォーム間で移植する際、単なる char を数値計算に使用していると、「ある環境では正しく動くが、別の環境ではオーバーフローや符号反転が起きて計算が狂う」というバグの原因になります。
したがって、文字そのものを扱う場合は char を使い、「0〜255の数値」としてデータを扱いたい場合は必ず unsigned char を明示することが重要です。
unsigned char の主な用途
unsigned char は、単なる文字の格納以外に以下のような高度な用途で頻繁に利用されます。
1. バイナリデータのハンドリング
ファイルの読み込みやネットワーク通信において、送受信されるデータは「バイト列」として扱われます。
これらはテキストではなく、画像データ、音声データ、実行ファイルなどの「生のバイナリ」です。
バイナリデータには 0x00 から 0xFF (255) までのすべての値が含まれる可能性があるため、符号の影響を受けない unsigned char の配列(バッファ)に格納するのが一般的です。
2. 画像処理におけるピクセルデータ
デジタル画像の多くは、RGB (Red, Green, Blue) の各成分を 8ビット (0〜255) で表現します。
例えば、フルカラー画像の場合、1つのピクセルは3つの unsigned char 型のデータで構成されます。
- 0:輝度なし(黒)
- 255:最大輝度
画像フィルタ処理や輝度補正の計算を行う際、負の値が発生すると不都合が生じるため、この型が標準的に使われます。
3. ビット演算
特定のビットを立てたり、マスクをかけたりする「ビット操作」を行う際にも unsigned char は有用です。
signed 型で右シフト演算を行うと、符号ビットが維持される「算術シフト」が発生し、意図しない値(空いたビットに1が埋まるなど)になることがありますが、unsigned 型であれば常に 0 が埋まる「論理シフト」が保証されるため、安全に操作できます。
型変換と演算における注意点
unsigned char を扱う際には、C言語特有の「整数昇格 (Integer Promotion)」というルールに注意しなければなりません。
整数昇格の仕組み
C言語では、char や short などの小さい整数型を演算に使用する場合、計算の前に自動的に int 型へと拡張されます。
これを 整数昇格 と呼びます。
例えば、2つの unsigned char 変数を足し合わせる際、内部的には一旦 int として計算され、その後に結果が代入先の型に合わせて切り詰められます。
unsigned char a = 200;
unsigned char b = 100;
int result = a + b; // 300として計算されるこの挙動自体は便利ですが、比較演算を行う際などに signed int との混在が起きると、意図しない比較結果を招くリスクがあります。
特に、大きな数値(128以上)を扱う unsigned char を符号ありの型と比較する際は注意が必要です。
printf 関数での書式指定
unsigned char を printf 関数で表示する場合、その用途に合わせて書式指定子を使い分ける必要があります。
- 文字として表示:
%c - 10進数の数値として表示:
%u(整数昇格により %d でも動作しますが、厳密には %u が適切です) - 16進数のバイナリとして表示:
%02x
バイナリデータのダンプ出力などでは、%02x を使うことで「1バイトを2桁の16進数」として綺麗に表示できるため、デバッグの際によく使われるテクニックです。
uint8_t との関係
現代的なC言語プログラミング(特に C99 規格以降)では、<stdint.h> ヘッダーで定義されている uint8_t 型が頻繁に使用されます。
uint8_t は、「確実に8ビットの符号なし整数」であることを保証する型エイリアスです。
内部的には unsigned char として定義されていることがほとんどですが、コードの可読性と移植性を高めるために、数値としての「8ビットデータ」を強調したい場合は uint8_t を使用し、伝統的な「文字」や「汎用的な1バイトバッファ」を指す場合は unsigned char を使うといった使い分けがなされます。
実践的なサンプルコード
以下に、unsigned char を使用してバイナリデータを安全に処理する例を示します。
#include <stdio.h>
int main() {
// 0から255までの値を保持する配列
unsigned char data_buffer[] = { 0x00, 0x7F, 0x80, 0xFF };
int size = sizeof(data_buffer) / sizeof(data_buffer[0]);
for (int i = 0; i < size; i++) {
// 数値として表示
printf("Index %d: Value = %u (Hex: 0x%02X)\n", i, data_buffer[i], data_buffer[i]);
// 128以上の値を正しく判定できる(signed charだと負数扱いになる可能性がある)
if (data_buffer[i] >= 128) {
printf(" -> This value is in the upper range.\n");
}
}
// オーバーフローの挙動
unsigned char max_val = 255;
max_val = max_val + 1;
printf("Overflow result: %u\n", max_val); // 0 に戻る
return 0;
}このコードでは、unsigned char を使うことで、0x80 (128) や 0xFF (255) といった値が負の数として誤認されることなく、正確に比較・出力されていることがわかります。
また、255に1を足すと 0 に戻る(ラップアラウンド)という符号なし型特有の性質も確認できます。
まとめ
C言語の unsigned char は、コンピュータが扱うデータの最小単位である「1バイト」を最も純粋な形で扱うための非常に強力な型です。
0〜255という明確な範囲を持ち、符号による曖昧さを排除できるため、システム開発や組み込み、画像処理といった「ハードウェアに近い層」でのプログラミングにおいて、その重要性は極めて高いと言えます。
最後に、unsigned char を使いこなすためのポイントを整理します。
- バイナリデータを扱う際は、デフォルトの
charではなくunsigned charを明示的に選ぶ。 - 値の範囲が 0〜255 であることを意識し、負の値が必要な場合は
signed charを検討する。 - 移植性を重視するプロジェクトでは、
stdint.hのuint8_tの活用も視野に入れる。 - 整数昇格による暗黙的な型変換のルールを理解し、演算時のバグを防ぐ。
これらの特性を正しく理解し、適切に型を選択することで、堅牢で効率的なC言語プログラムを構築することができるようになります。
データ構造の基礎である「1バイト」を制することは、C言語マスターへの第一歩と言えるでしょう。